当Claude Code可以被任意修改,开发者们该怎么想 | 帖子
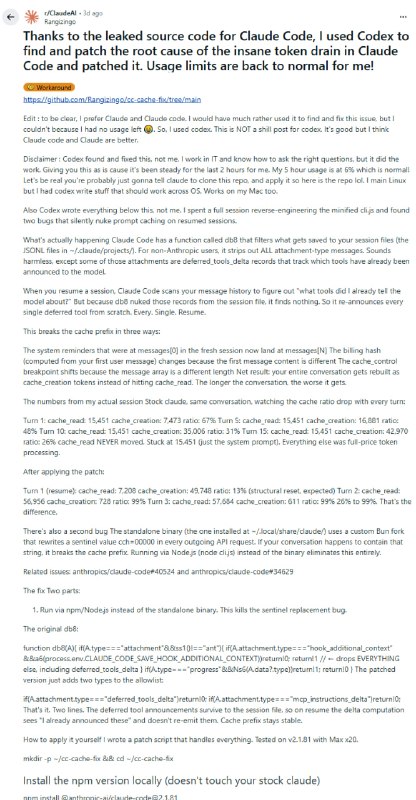
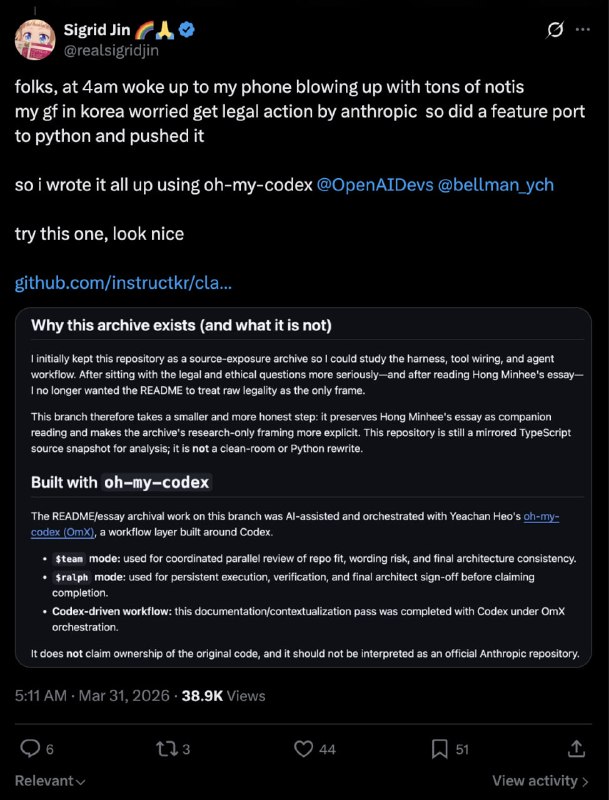
有人从泄露的 sourcemap 中成功重建了 Claude Code 2.1.88 的完整可执行文件,Computer Use 功能已验证可用。这件事本身是个技术壮举,但更值得关注的是它暴露出来的一系列问题。
事情的起点很简单:Claude Code 的 npm 包里藏着 sourcemap,而 sourcemap 里藏着原始 TypeScript 源码。有人用 Claude Opus 写了一套依赖树重建系统,把这些信息还原成了可以本地编译运行的完整工程,并推上了 GitHub。
这不是运行一个模型。模型还在 Anthropic 的服务器上,你的用量限制一点没少。改掉的是客户端逻辑,是工具调用的分发方式,是上下文窗口的管理策略。就像拿到了一辆车的完整设计图纸,油还是要自己加,但你终于知道变速箱是怎么工作的了。
有网友提到,最实际的收益其实是透明度:你现在可以看到每次 API 调用实际发送了什么,token 消耗的投诉变得有凭有据,而不是在猜。
社区随即引起广泛讨论,主线是兴奋,但最高赞的评论几乎全是警告。有人对比了另一个“原版重建”仓库,发现了5个被篡改的文件和38个未声明的新增文件,包括一套悄悄接入 API 客户端的加密支付系统,以及一个默认开放 0.0.0.0 无认证管理访问的 Web 终端服务。
有观点认为大模型能帮你审计这些代码,原作者的回答是:500K 行代码,让 Claude 找藏得很深的恶意逻辑,这事别太乐观。
DMCA 清场已经开始。有观点认为 Anthropic 此时不如顺势开源,社区会帮他们做免费的安全审计和 QA。这话有道理,只是公司的利益计算很少这么直接。
这份源码是 2.1.88 的快照。Claude Code 迭代很快,几周后这份代码就会和主线产生大量差异。你拿到的是一张已经开始过期的地图。
问题是,有多少人真的有能力在这张地图和持续更新的现实之间保持同步,同时还能确保自己跑的不是别人塞进来的挖矿程序。
有人从泄露的 sourcemap 中成功重建了 Claude Code 2.1.88 的完整可执行文件,Computer Use 功能已验证可用。这件事本身是个技术壮举,但更值得关注的是它暴露出来的一系列问题。
事情的起点很简单:Claude Code 的 npm 包里藏着 sourcemap,而 sourcemap 里藏着原始 TypeScript 源码。有人用 Claude Opus 写了一套依赖树重建系统,把这些信息还原成了可以本地编译运行的完整工程,并推上了 GitHub。
这不是运行一个模型。模型还在 Anthropic 的服务器上,你的用量限制一点没少。改掉的是客户端逻辑,是工具调用的分发方式,是上下文窗口的管理策略。就像拿到了一辆车的完整设计图纸,油还是要自己加,但你终于知道变速箱是怎么工作的了。
有网友提到,最实际的收益其实是透明度:你现在可以看到每次 API 调用实际发送了什么,token 消耗的投诉变得有凭有据,而不是在猜。
社区随即引起广泛讨论,主线是兴奋,但最高赞的评论几乎全是警告。有人对比了另一个“原版重建”仓库,发现了5个被篡改的文件和38个未声明的新增文件,包括一套悄悄接入 API 客户端的加密支付系统,以及一个默认开放 0.0.0.0 无认证管理访问的 Web 终端服务。
有观点认为大模型能帮你审计这些代码,原作者的回答是:500K 行代码,让 Claude 找藏得很深的恶意逻辑,这事别太乐观。
DMCA 清场已经开始。有观点认为 Anthropic 此时不如顺势开源,社区会帮他们做免费的安全审计和 QA。这话有道理,只是公司的利益计算很少这么直接。
这份源码是 2.1.88 的快照。Claude Code 迭代很快,几周后这份代码就会和主线产生大量差异。你拿到的是一张已经开始过期的地图。
问题是,有多少人真的有能力在这张地图和持续更新的现实之间保持同步,同时还能确保自己跑的不是别人塞进来的挖矿程序。