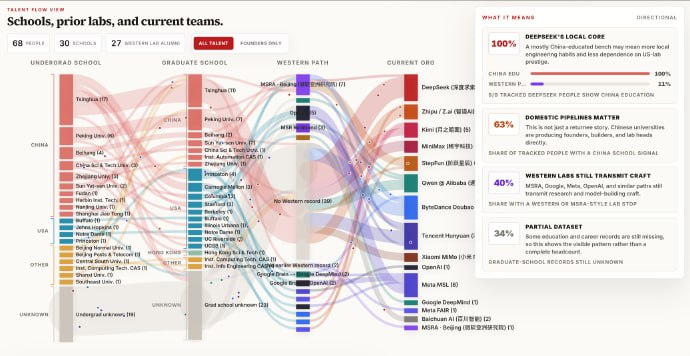
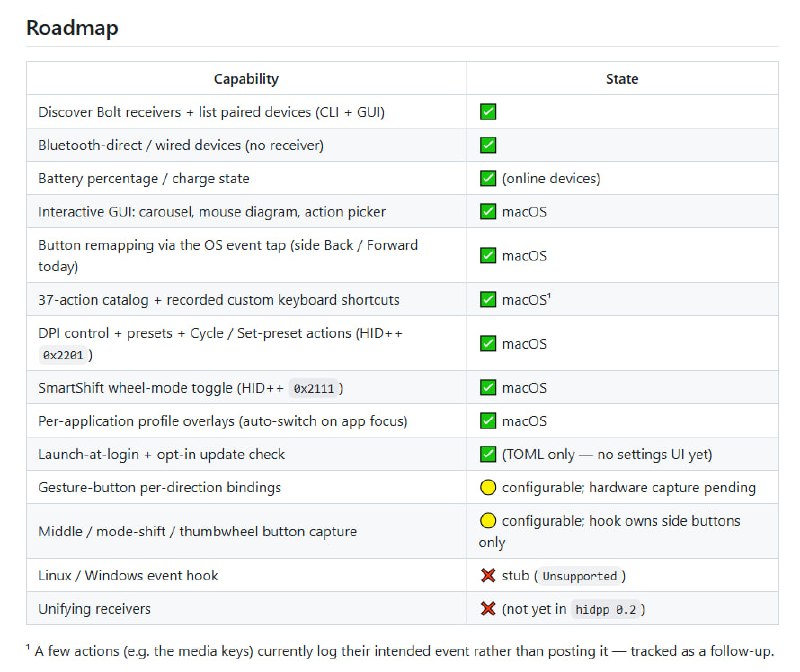
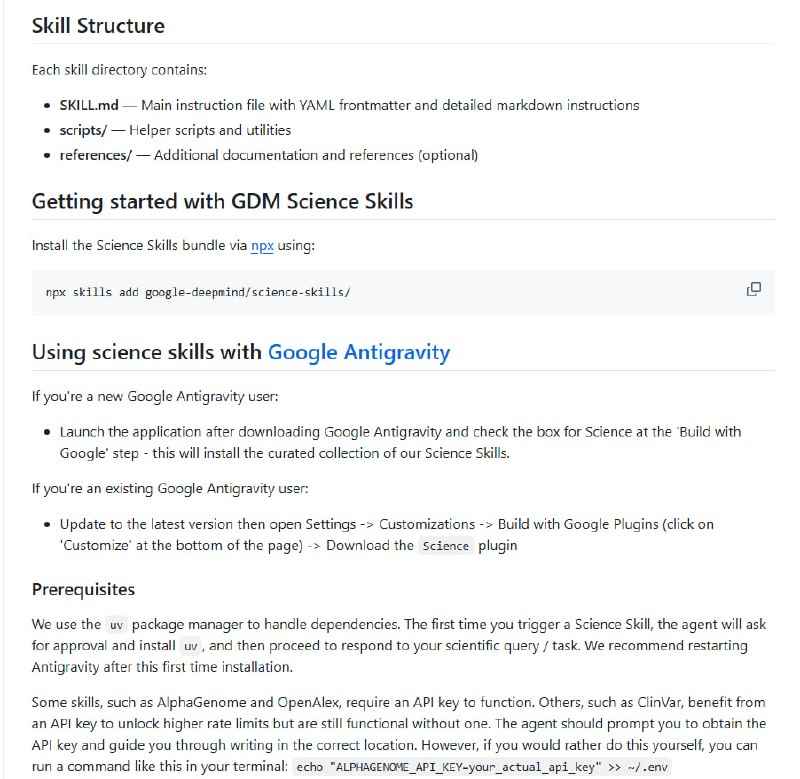
GDM Science Skills 是一套专为科研任务打造的 Agent 技能集合,覆盖基因组学、结构生物学、化学信息学、文献检索等多个领域,把 30 多个常用数据库和工具的能力集成在一起。
它能让 AI 代理更好地理解科学上下文、减少 token 消耗,同时保持更高的执行准确度。每个技能都包含结构化的指令、辅助脚本和参考资料,方便快速嵌入科研工作流。
主要功能:
- 集成 AlphaGenome、AFDB、UniProt 等 30+ 数据库与工具;
- 提供结构化指令与脚本,扩展 Agent 在专业科学任务上的能力;
- 支持通过 npx 一键安装,也可直接在 Google Antigravity 中加载;
- 部分技能支持 API Key 以提升调用上限,无 Key 也可基础使用;
- 附带示例与技术报告,方便快速上手和二次开发。
支持通过 npx 或 Google Antigravity 快速部署,适合科研人员、生物信息学团队和 AI 科研工具开发者。