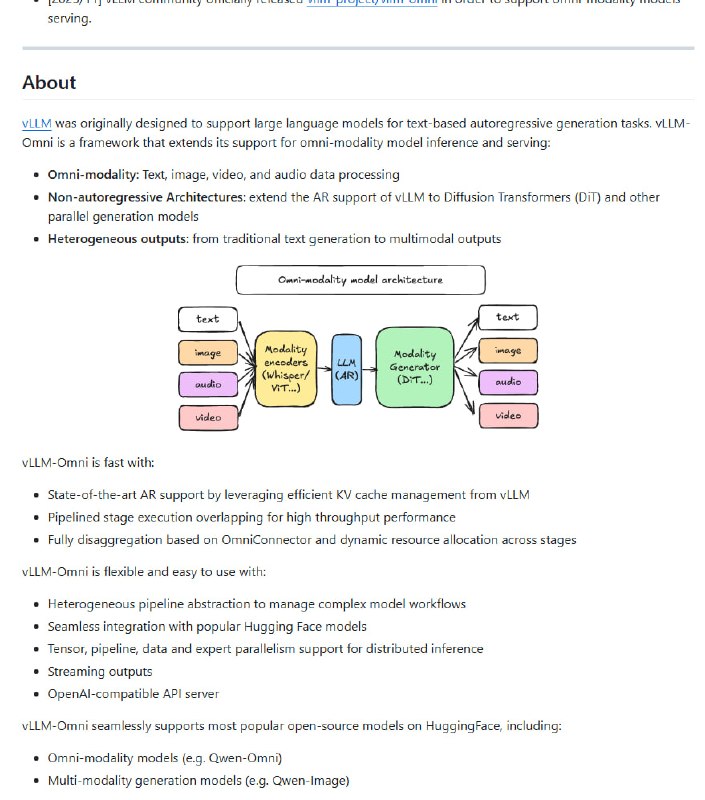
vLLM-Omni 基于高效的 KV cache 管理和流水线执行,专为支持包括文本、图像、音频、视频等多模态输入的模型设计,轻松实现异构模型推理和服务。
它不仅兼容主流 Hugging Face 开源模型,还支持分布式推理、多阶段流水线调度、流式输出和 OpenAI 兼容接口,极大提升多模态模型在线推理的效率和灵活性。
主要功能:
- 支持多模态数据(文本、音频、图像、视频)处理与生成;
- 支持非自回归架构如扩散模型,实现高效的并行生成;
- 基于 KV cache 优化自回归模型推理性能;
- 异构流水线抽象,管理复杂多阶段模型工作流;
- 分布式推理支持,涵盖张量并行、数据并行和专家并行;
- 开箱即用的 OpenAI 兼容 API 服务器,方便集成;
- 支持主流平台(CUDA/ROCm/NPU/XPU),广泛适配多硬件环境。
适合AI开发者、研究人员和企业级应用场景的多模态AI模型推理部署。