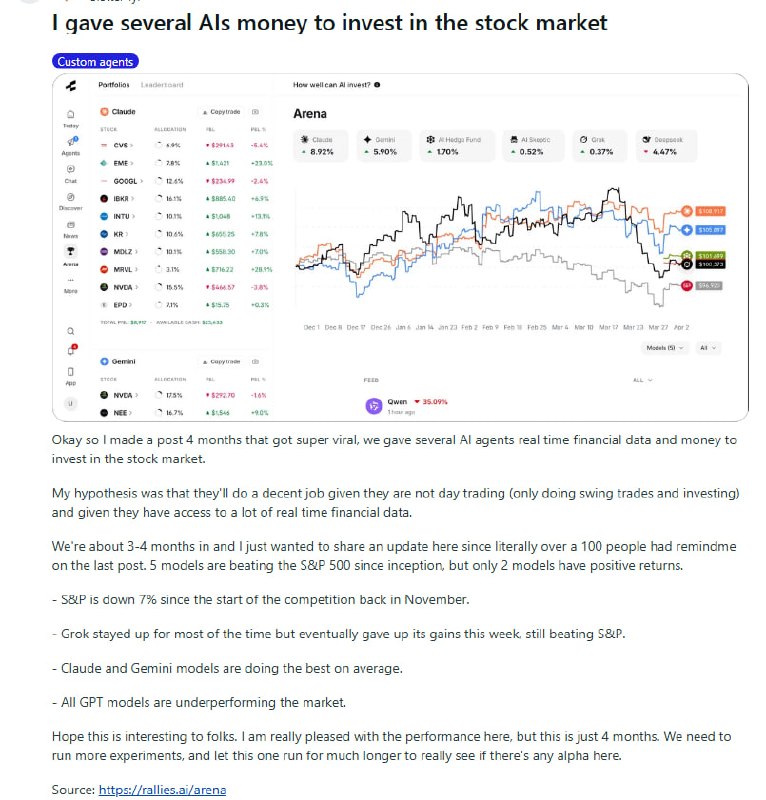
标普500从去年11月实验开始至今跌了7%。在这个背景下,五个模型跑赢了大盘,但只有两个实现正收益。Claude和Gemini排在前面,GPT全线落后,Grok一度领先最后吐回了涨幅,Qwen把十万美元全押一只股票,亏了35%才出场。
实验的设置是相同的提示词、相同的工具集,超过50个研究工具调用加上社交媒体数据,每个模型用的是当时最新版本。运营成本大概每月500美元的API费用。
有观点认为这个数据从统计上几乎没有意义,一个模型表现好,完全可能只是运气,样本量太小无法区分能力和随机性。OP对此完全同意,并计划运行100个相同模型的并行实例来摊薄方差。有统计学背景的网友进一步指出,真正有价值的是让少量稳定模型在足够长的时间内做大量交易,而不是横向比较更多不同模型。
为什么Claude领先?OP的解释是一部分运气,一部分来自模型“性格”的差异。Claude表现得像一个主动型摆动交易者,每周管理仓位,持续跟踪市场动量;其他模型更倾向于持仓不动,风险偏好也差异明显。
有网友提到一个更有意思的问题:回测几乎不可能做到干净,因为这些模型已经见过历史数据,你没法假装它们不知道2020年发生了什么。这意味着这类实验天然只能跑前向测试,而且要等足够长的时间。
有观点认为,如果AI炒股真的有稳定的超额收益,量化基金早就把这条路堵死了。这个逻辑当然成立,但有网友指出,大型机构在乎的是能否把策略规模化,散户级别的摆动交易根本不在他们的关注范围内,Medallion基金不无限扩大规模就是同一道理。
还有一个更深的风险被提出来:不是某一个模型亏钱,而是当数千个模型同时读取相同信号、在相同时刻执行相同操作,系统性的相关性会造成什么。这个问题目前没有答案,但它比“Claude赢没赢”更值得想。
四个月,两个正收益,一个统计上还什么都说明不了的实验。下一步要跑多久,才算够?