一个脚本省掉50K Token:AI编程的冷启动优化实践 |
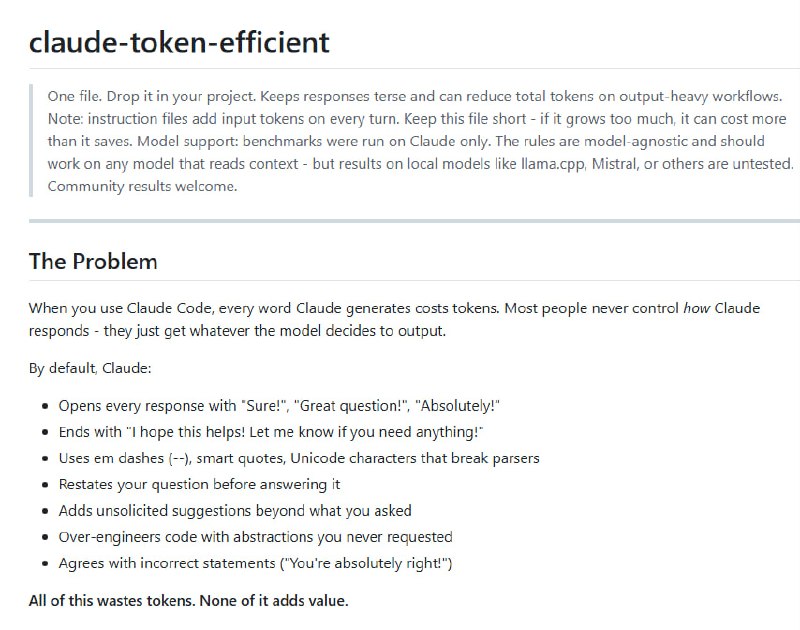
帖子Claude Code每次新对话都会花费大量token重新探索代码库结构,这是个被忽视的隐性成本。有人构建了预索引工具将这个开销从50K token压缩到3K以内,引发社区广泛讨论。
每次打开Claude Code,它做的第一件事不是帮你写代码,而是四处张望。
读目录、扫文件、查函数签名。大项目上,这个“熟悉环境”的过程要烧掉30到50K token,然后才轮到你真正想问的那个问题。有人给这个现象起了个名字:“探索税”。
一位开发者用一个叫`ai-codex`的脚本来解决这个问题。逻辑很简单:提前把项目结构扫描一遍,生成五个压缩后的Markdown文件,分别记录API路由、页面树、库导出、数据库schema和组件索引。在CLAUDE.md里加一行声明,让Claude每次对话优先读这几个文件,直接跳过探索阶段。
在一个有950个API路由、255个数据库模型的项目上测试:原来理解一个模块需要15次工具调用,使用索引后降到5次grep,总token消耗从50K级别压缩到约3K。
这条帖子在Reddit引发广泛讨论,涌现出大量类似工具。Cymbal用SQLite加tree-sitter做实时增量索引,JCodeMunch走MCP路线做精准符号检索,还有TheBrain、codebase-memory-mcp等等。有观点认为,这种“工具大爆炸”本身就说明Claude Code在原生能力上存在明显缺口。
最被质疑的点是索引过期问题。作者的回答是:路由和schema这类结构变动频率远低于代码内容本身,把`npx ai-codex`挂到git pre-commit hook里,每次提交自动更新,耗时不到一秒,基本无感知。
也有人提出不同意见。有网友认为配合Serena做实时符号分析、再加上合理的工具调用引导,也能把冷启动控制在3到5次调用以内,不一定需要静态索引。还有人指出,Rails或Django这类约定强制的框架根本不存在这个问题,因为模型早就被训练知道“路由在哪里”,这本质上是JavaScript生态系统过于混乱的代价。
有网友提到,加上prompt caching会产生双重节省效应:索引文件本身变化少,缓存命中率极高,等于既减少了加载的token量,又降低了每个token的单价。这个组合值得实测。
更深的问题是:预索引解决的是“什么在哪里”,解决不了“这些东西之间怎么关联”。模块耦合、依赖链、架构边界,这一层每次还是得从代码里重新推导。
所以预索引是个好的地板,不是天花板。
预索引能给你一张楼层平面图,Claude不用再挨个开门找厨房,但进了厨房之后,冰箱里装了什么,还是得自己看。
这个工具本身是Claude Code在单次对话中独立设计并构建完成的,这个细节本身也挺有意思。