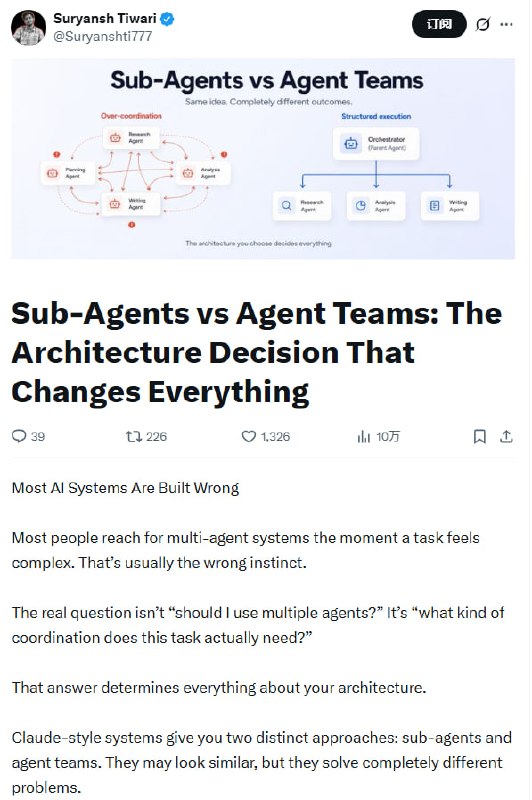
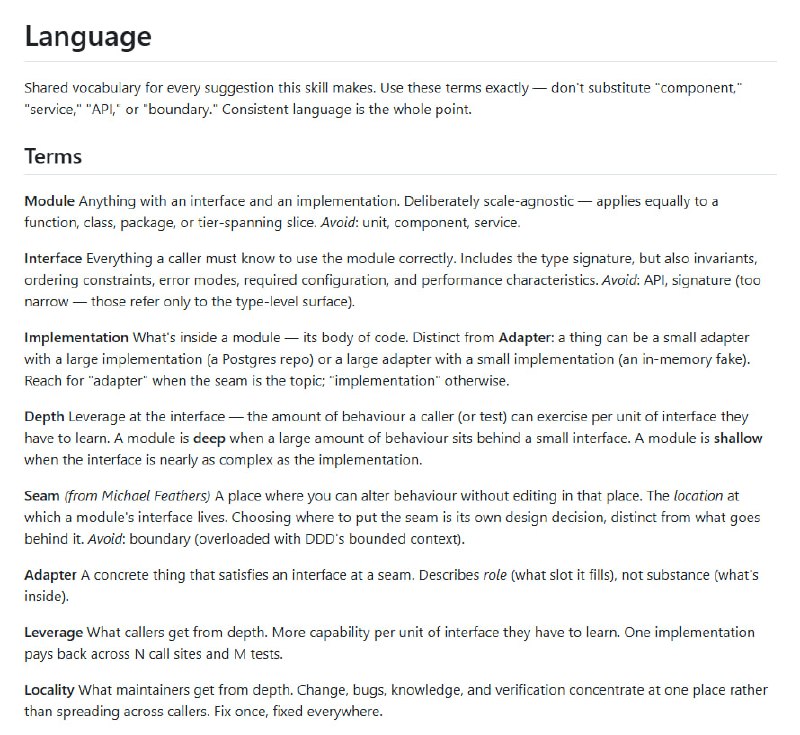
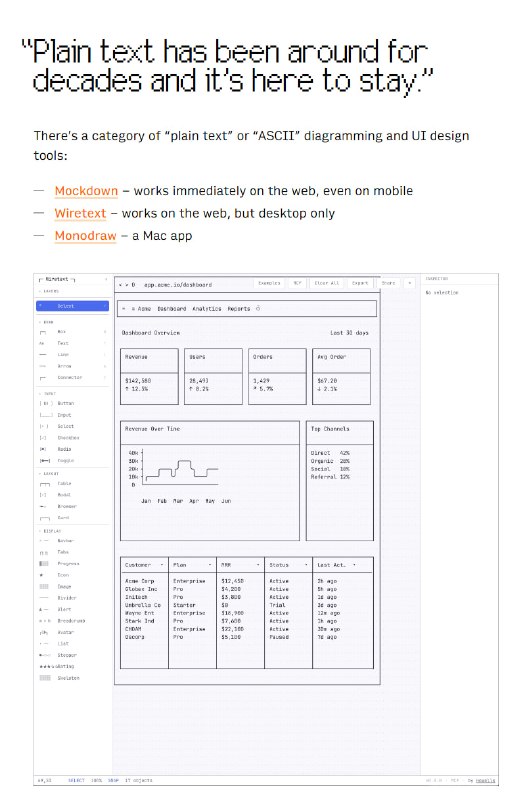
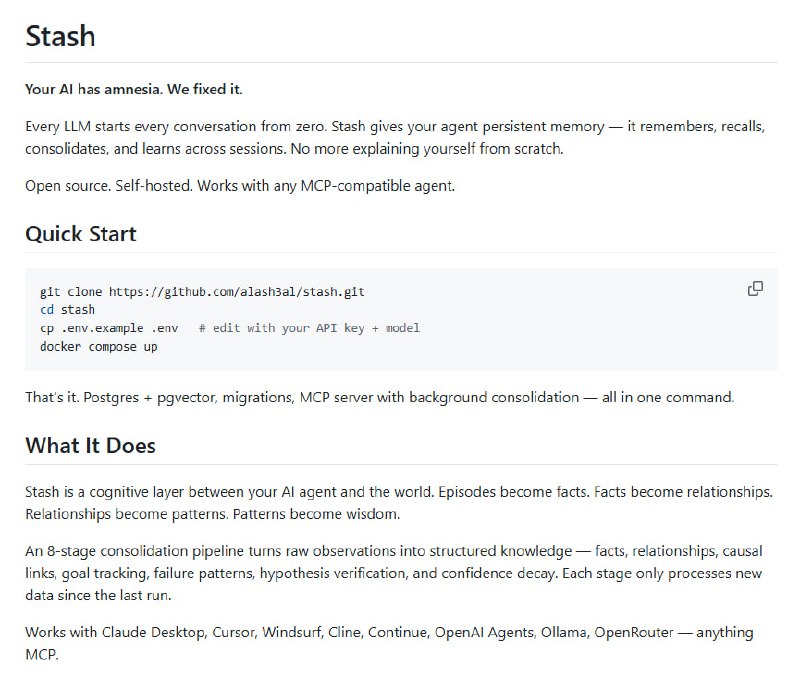
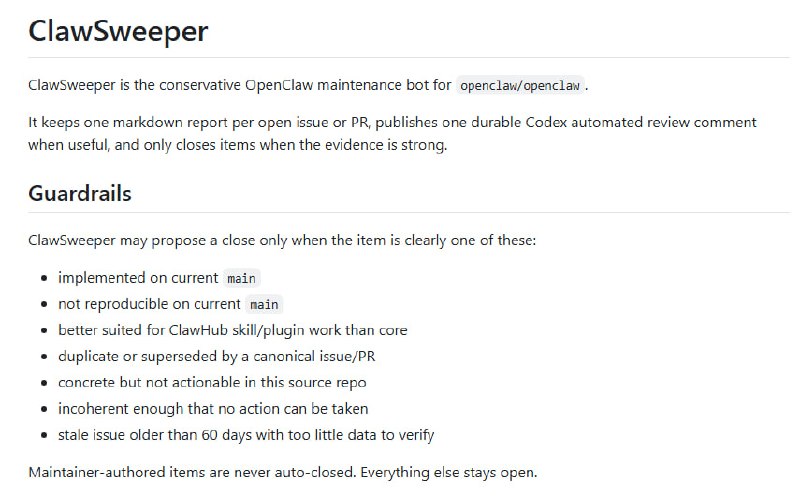
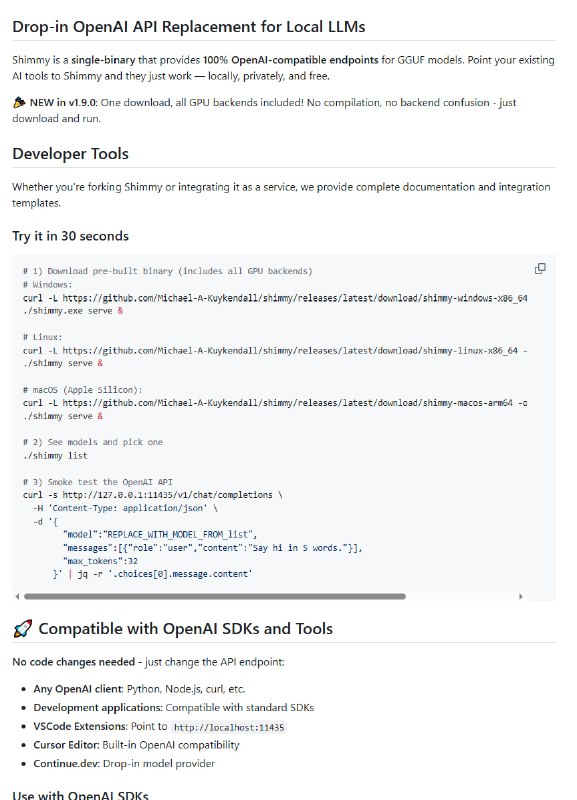
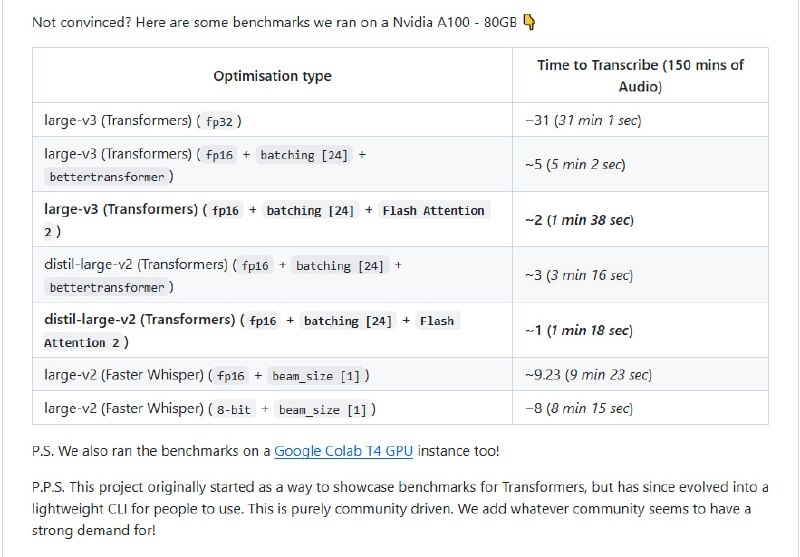
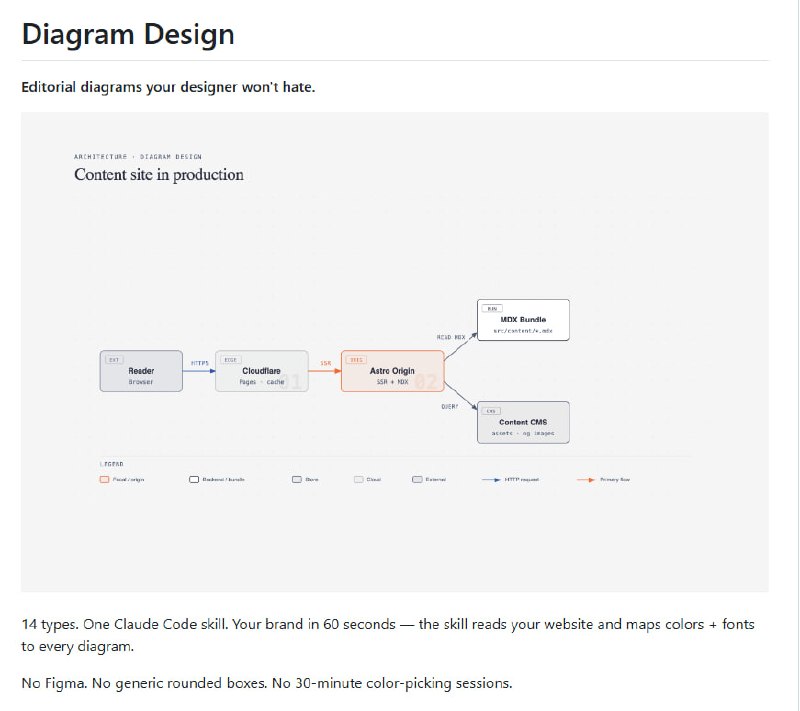
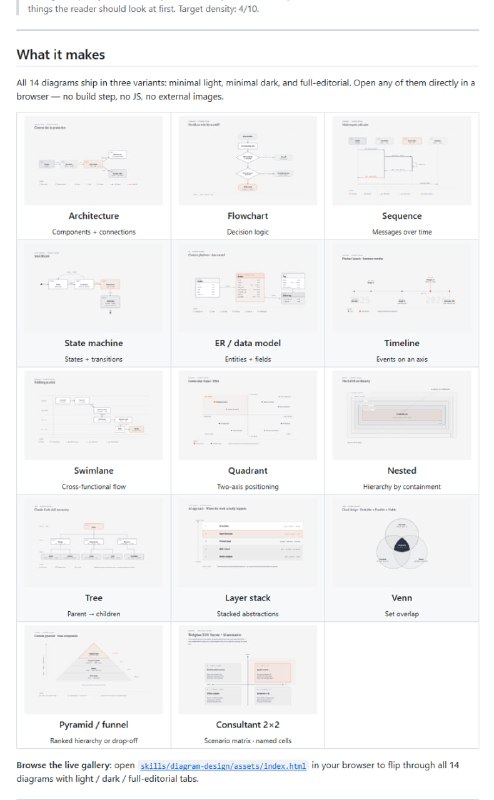
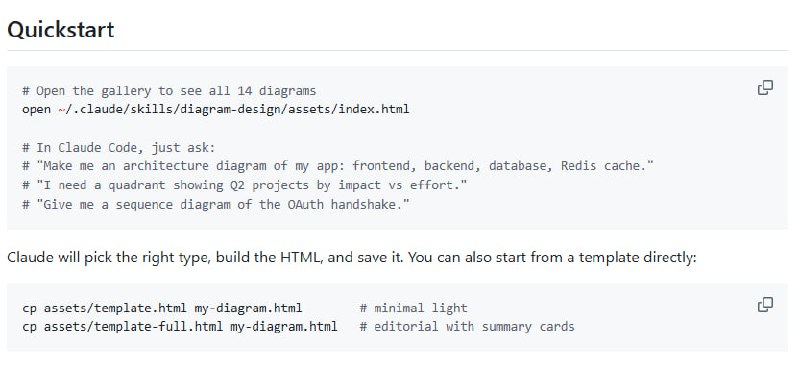
分析大型代码库时要来回切换编辑器、文档、依赖图和搜索工具,AI 助手也常常忽略深层依赖和调用链,造成修改失误。
GitNexus 把代码库分析所需的功能全部整合到一起,提供了零服务器的代码智能引擎解决方案。
不仅能构建完整的知识图谱(依赖、调用链、功能集群、执行流),还支持 Graph RAG 智能体、MCP 协议集成、多仓库管理,甚至浏览器内可视化探索。
主要功能:
- 完整知识图谱构建,支持 14+ 编程语言(TS/JS/Python/Java 等)的 AST 解析和跨文件符号解析;
- MCP 服务器集成,与 Claude Code、Cursor、Codex 等 AI 编辑器无缝对接;
- 智能工具集:影响范围分析、变更检测、多文件重命名、Cypher 图查询;
- 浏览器 Web UI,支持拖拽 ZIP/仓库即时生成交互式知识图谱和 RAG 聊天;
- 多仓库支持,统一图谱查询执行流和跨仓库合约匹配;
- 自动生成 AGENTS.md、技能文件和代码 Wiki 文档。
支持 CLI(npm install -g gitnexus)、Docker、多平台本地运行,也提供在线试用 gitnexus.vercel.app,适合开发者、AI 工程师和大型项目团队。
GitNexus 把代码库分析所需的功能全部整合到一起,提供了零服务器的代码智能引擎解决方案。
不仅能构建完整的知识图谱(依赖、调用链、功能集群、执行流),还支持 Graph RAG 智能体、MCP 协议集成、多仓库管理,甚至浏览器内可视化探索。
主要功能:
- 完整知识图谱构建,支持 14+ 编程语言(TS/JS/Python/Java 等)的 AST 解析和跨文件符号解析;
- MCP 服务器集成,与 Claude Code、Cursor、Codex 等 AI 编辑器无缝对接;
- 智能工具集:影响范围分析、变更检测、多文件重命名、Cypher 图查询;
- 浏览器 Web UI,支持拖拽 ZIP/仓库即时生成交互式知识图谱和 RAG 聊天;
- 多仓库支持,统一图谱查询执行流和跨仓库合约匹配;
- 自动生成 AGENTS.md、技能文件和代码 Wiki 文档。
支持 CLI(npm install -g gitnexus)、Docker、多平台本地运行,也提供在线试用 gitnexus.vercel.app,适合开发者、AI 工程师和大型项目团队。