本地运行大模型推理需要复杂的Python环境、Ollama笨重二进制或llama.cpp编译烦恼,依赖多、启动慢、配置麻烦。
Shimmy 用一个Rust单二进制搞定一切,提供完全OpenAI API兼容的本地推理服务器,GGUF + SafeTensors支持,免费永远免费。
不仅自动发现Hugging Face/Ollama模型,还支持热模型切换、多GPU后端自动检测、MOE混合推理,甚至一键运行70B+大模型。
主要功能:
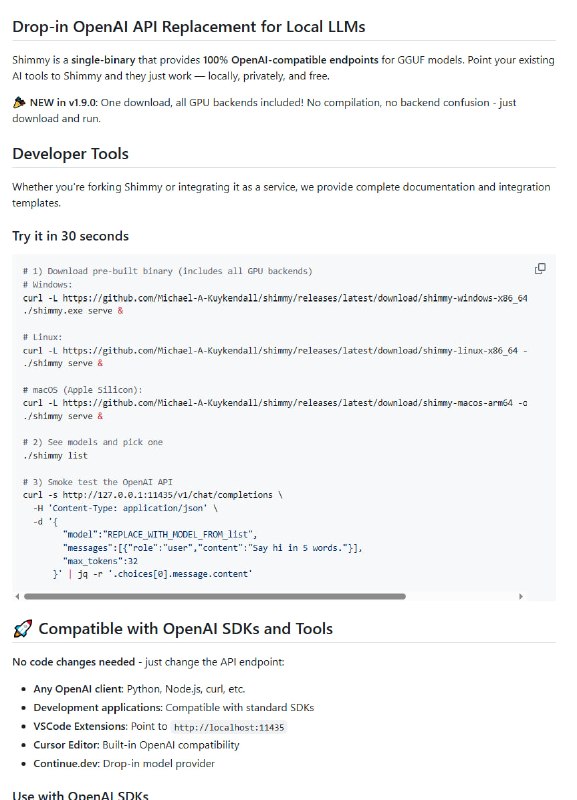
- 100% OpenAI API兼容,支持/v1/chat/completions等标准接口;
- 单二进制~5MB,包含所有GPU后端(CUDA/Vulkan/OpenCL/MLX),无需编译;
- 自动模型发现,支持Hugging Face缓存、Ollama目录、LoRA适配器;
- MOE CPU/GPU混合推理,消费级硬件跑70B+模型;
- 智能GPU自动检测+端口分配,无需任何配置即开即用;
- 支持VSCode Copilot、Cursor、Continue.dev等开发工具无缝集成。
支持 Windows、Linux、macOS 多平台,一键下载运行,30秒内启动本地AI服务,完美适合开发者本地开发和隐私推理。