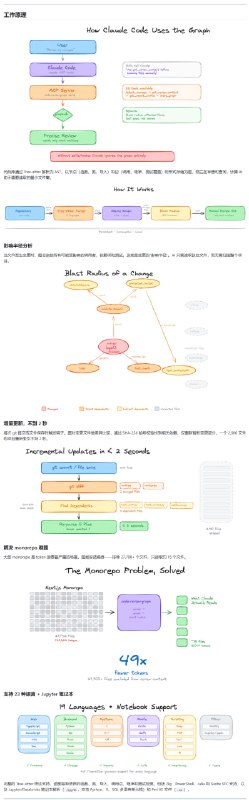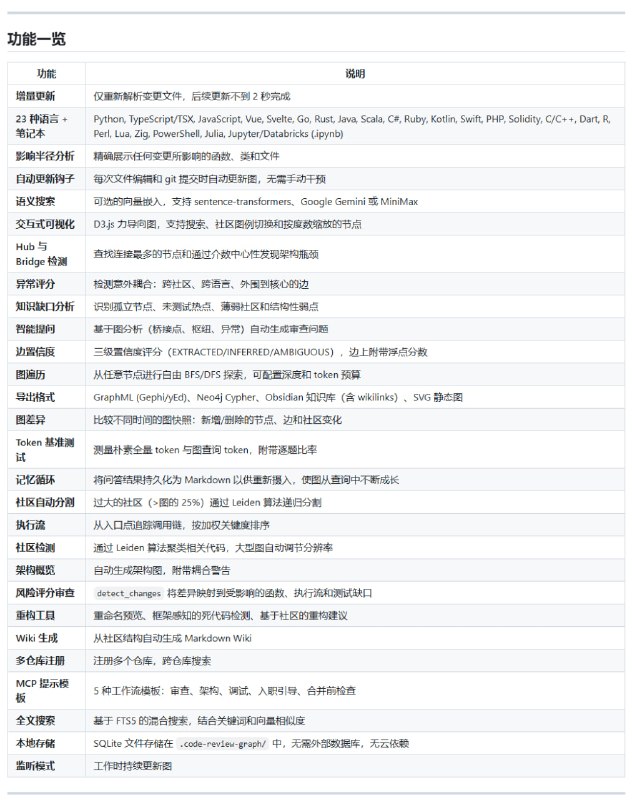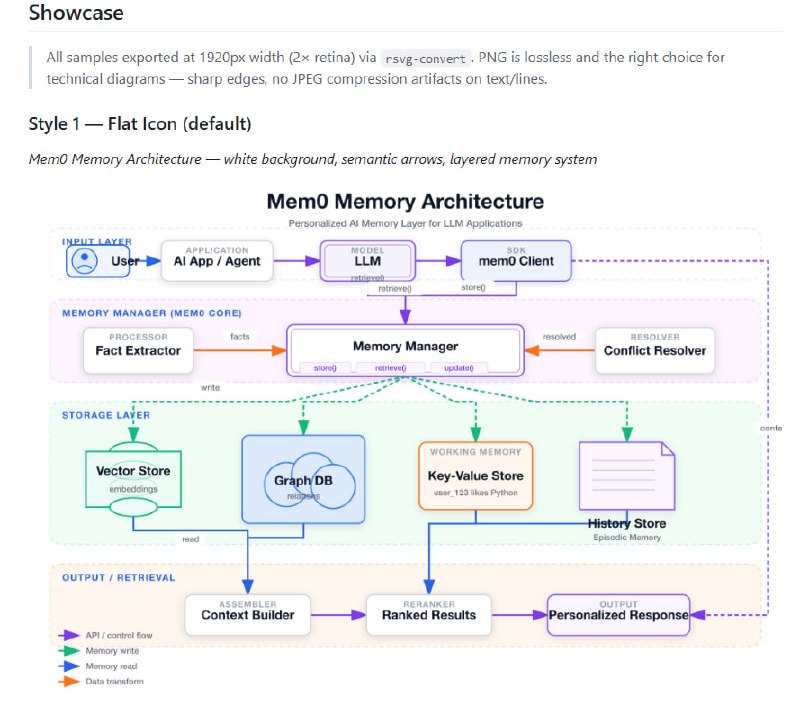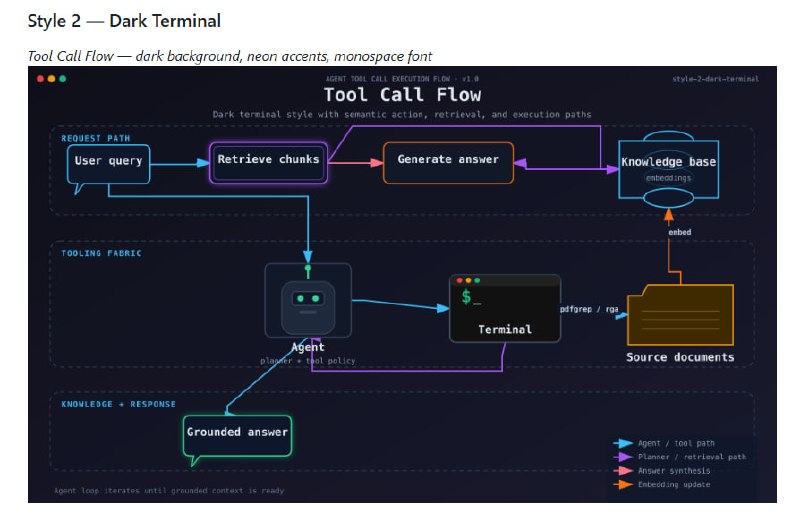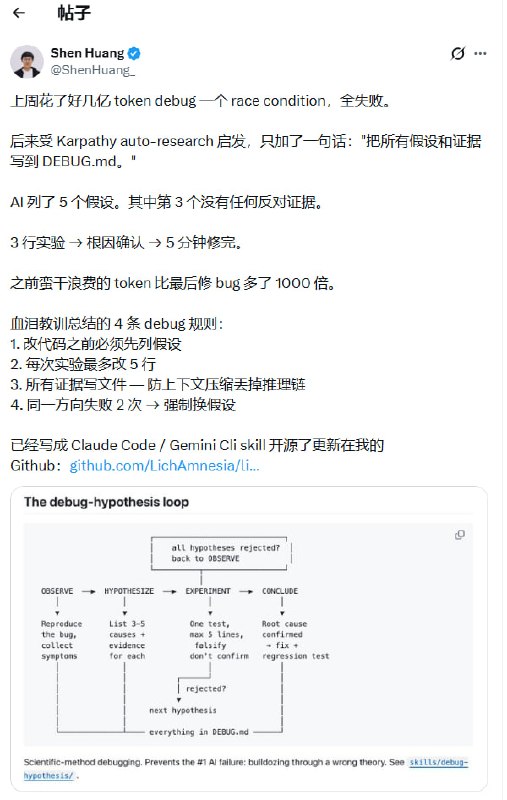
大多数人把 Claude 当作一个语法更通顺的搜索引擎:提问、阅读、关闭标签。如果你也是这样,你正坐在金矿上捡碎石。
Claude 的真正价值不在于给出答案,而在于重塑你的思考方式。以下是 12 个能彻底改变你产出质量的深度用法,按影响力从低到高排列:
一、 破除思维盲区:从验证到挑战
1. 极限施压(Steelmaning): 别让它夸你。告诉它:“我决定做 X,请针对这个决策进行‘最强反驳’。”让它找出你计划中那个注定会失败的致命漏洞。在现实撞墙前,先在对话框里撞墙。
2. 深度访谈: 别直接下指令。要求它:“在我写完之前,不断向我提问,直到你完全理解我想表达的核心逻辑。”generic 的输入只会得到平庸的输出,这个步骤能逼你把模糊的直觉具象化。
3. 模拟特定读者:“请以一位看过 400 个项目的挑剔投资人的视角阅读这段话,告诉我你在哪里失去了兴趣。”好内容不分绝对的好坏,只看是否精准击中了目标受众的偏见与痛点。
4. 永久化个人声韵: 在 Project 中喂入 10 篇你的原创文章。让它学习你的节奏、用词习惯和呼吸感。你的声音就是你的品牌,别让 AI 的翻译腔毁了它。
二、 决策与效能:从执行到思考
5. 构建决策框架: 面对复杂的真实选择,给它变量,让它建立带权重的矩阵。聪明人不仅用它写作,更用它辅助思考。
6. 信息脱水: 面对 200 页的报告,别试图通读。要求它提供 500 字的简报,列出 5 个最具操作性的发现和 3 个本周必须执行的动作。信号胜过噪音。
7. 红队测试(Red-teaming): 把你的市场策略交给它,扮演一个冷酷的竞争对手:“这个方案在第 9 个月会怎么崩盘?”这种不适感,正是你避开真实失败的护身符。
8. 零代码数据洞察: 直接上传 CSV。不要等分析师,直接问它:“为什么 3 月收入下滑了?找出那个解释数据的关键维度。”
三、 进化为不同维度的工具
9. 维护“动态简报”: 在 Project 中建立一个持续更新的文件。每轮对话结束时,让它总结已达成的共识和待解决的悬念。别让灵感在关闭网页时断线。
10. 难堪对话演习: 扮演你最怕面对的那个人(比如要宣布裁员时的员工或业绩未达标时的董事)。在现实中自信的前提,是在模拟中被“摧毁”过。
11. 多维语境重写: 一份底稿,30 秒内转化为:给技术专家的实现方案、给高管的风险评估、给团队的 3 点 Slack 消息。这是工作流的降维打击。
12. 授人以渔(系统构建): 这是最高阶的用法。不要问它要答案,要它为你建立一套“产生答案的系统”。比如一套评估市场机会的永久核查清单。
你打开 Claude 是为了思考得更深、行动得更快,结果你却只用它来润色语法。工具从未改变,改变的是你提问的高度。