通过引入外部文档记录假设与证据,可以有效防止 AI 在长上下文压缩中丢失推理链。这种方法能将耗费数亿 Token 的无效尝试,转化为分钟级的根因定位。
有时候,解决问题的关键不在于增加计算量,而在于建立一个“外部存储层”。
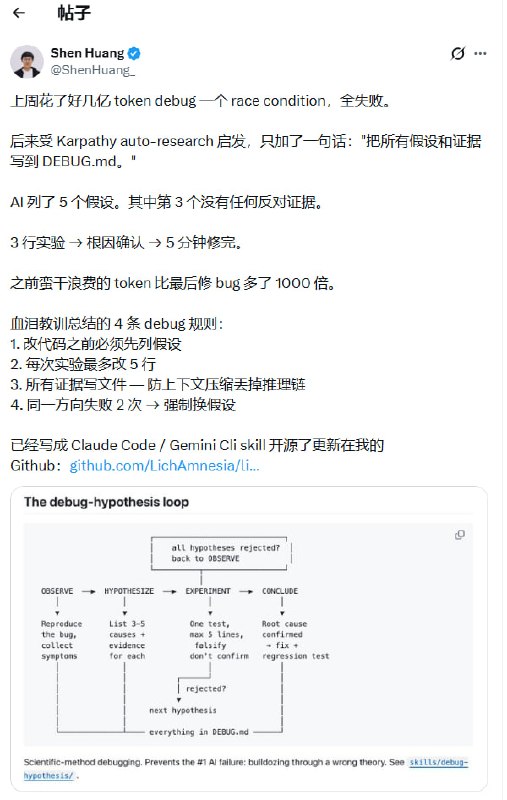
最近有个很有意思的案例:有人为了调试一个竞态条件(Race Condition),消耗了数亿 Token 却颗粒无收。直到引入了一个简单的指令——要求 AI 把所有假设和证据写进 `DEBUG.md`。结果 AI 列出五个假设,发现第三个没有任何反对证据,随后仅通过三次实验就锁定了根因。
这本质上是在为 Agent 的推理过程做“持久化”。
现在的长上下文模型看似能记住一切,但实际上存在严重的上下文压缩问题。当对话轮次过多,中间的逻辑链条会像被挤压的内存一样发生信息丢失。把证据写在文件里,就是给 AI 提供了一个不可篡改的、具备强一致性的“单点真理来源”。
有网友提到,这种做法其实是在手动实现原本应该由自动化测试框架(Harness)完成的工作。好的系统应该能自动判断哪些中间推理需要持久化,而不是靠人去写规则提醒它。
这里总结了四条极具实操性的调试准则:
首先,改代码前必须先列假设。不要直接进入指令流水线,先在逻辑层完成预判。
其次,每次实验的改动量要极小。虽然有人觉得“最多改 5 行”太死板,但追求“外科手术式”的微创改动,能让因果关系变得极其清晰。
第三,强制要求将证据写入文件。这是防止推理链断裂的唯一手段。
最后,如果同一个方向失败两次,必须强制切换假设。
有观点认为,AI 给出的往往不是答案,而是一面镜子。它照出的是我们假设中的盲点。当我们在面对复杂 Bug 时,习惯性地想通过增加 Token 投入来“硬刚”,这其实是一种低效的暴力破解。
真正的智能不在于无止境的计算,而在于能够像人类一样,在证据和假设之间建立起逻辑的边界。
如果实验的路径已经走到了死胡同,是不是该考虑给 Agent 换一个全新的搜索分支了?