随着文档量增加,高维向量空间的语义边界会变得模糊,导致检索精度大幅下降。解决办法在于从单纯的“搜索”转向基于图结构的“推理”。
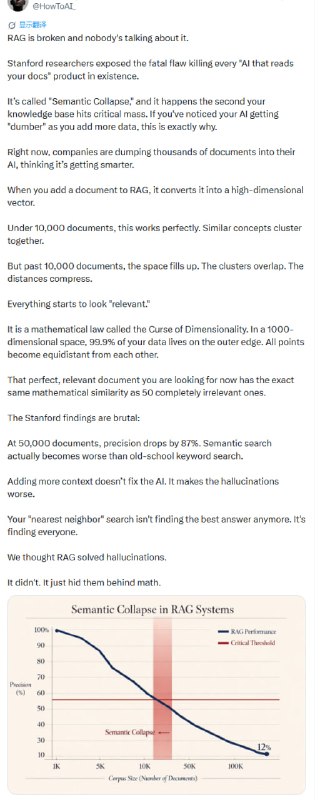
把成千上万的文档一股脑塞进 RAG,就像试图在一个溢出的堆内存里寻找一个特定变量。随着文档量突破 10,000 这个临界点,语义空间开始变得拥挤。原本清晰的特征簇在极高维度的压缩下逐渐重叠,每个向量看起来都和别的向量“挺像”。
斯坦福的研究揭示了这种现象:当规模达到 5 万份文档时,检索精度会暴跌 87%。这其实就是维度灾难。在高维空间里,数据点趋向于分布在边缘,彼此之间的距离变得几乎相等。此时的语义搜索,找出来的不再是那个最精准的答案,而是一堆看起来都“相关”的噪声。
有观点认为,这种现象源于工程实现的局限。目前的做法太过于依赖扁平化的向量检索。真正的知识不是散落在空间里的孤立点,而是一张带有层级、时效和权威性的图。如果只做余弦相似度计算,就无法处理法律条文被废止或辖区变更这种逻辑关联。
解决路径正从“增加数据量”转向“优化检索结构”。通过 GraphRAG 引入关系约束,或者利用局部上下文窗口来规避全局坍缩。知识的价值在于连接,而非单纯的堆砌。