黑洞资源笔记
- MeetingSummarizer:轻松记录、转录和总结会议,由OpenAI的Whisper和GPT-3.5-turbo驱动,CLI和GUI两种界面提供了不同的使用方式,用户可以使用命令行或图形界面来录制、转录和总结会议内容
-
- 用500行SQL代码实现GPT:介绍了如何使用SQL实现一个大型语言模型,解释了SQL不适合实现大型语言模型的原因,介绍了生成式大型语言模型所需的逻辑和算法。文章还提到了生成预训练Transformer(GPT)的原理和实现细节
- DataTrove 是一个用于大规模处理、过滤和删除重复文本数据的库。它提供了一组预构建的常用处理块以及一个框架,可以轻松添加自定义功能。
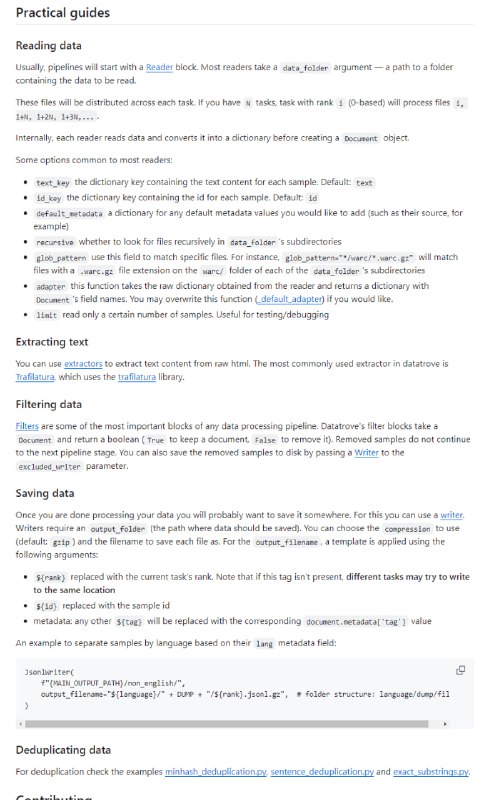
DataTrove 处理管道与平台无关,可以在本地或 slurm 集群上开箱即用。其(相对)较低的内存使用率和多步骤设计使其非常适合大型工作负载,例如处理法学硕士的训练数据。
通过fsspec支持本地、远程和其他文件系统。 -
- 科学领域预训练语言模型列表,包括数学、物理、化学、生物学、医学、材料科学和地球科学等领域的模型,涵盖不同的参数规模,从小于100M到700B参数,以及不同的模态(如语言、视觉、分子、蛋白质、图表等)
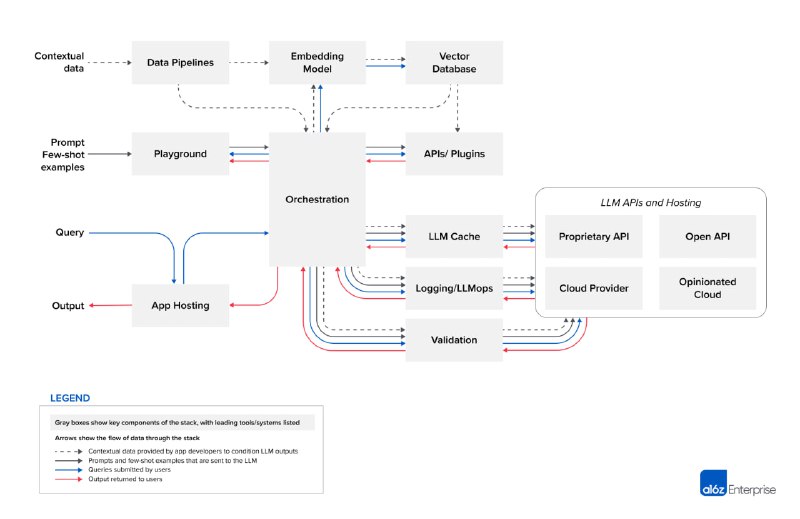
- LLM App Stack:LLM应用栈工具、项目和供应商列表,旨在更全面地覆盖每个类别中的所有可用选项,涵盖了数据管道、嵌入模型、向量数据库、沙盒、编排器、API / 插件、LLM缓存、日志/监视/评估、验证器、LLM API(专有)、LLM API(开源)、应用程序托管平台、云提供商、有见解的云项目列表等类别。
- Neural Speed:旨在通过Intel Neural Compressor和llama.cpp支持的低bit量化和稀疏性的创新库,为Intel平台上的大型语言模型(LLMs)提供高效的推断能力,提供了以下实验性特性:模块化设计以支持新模型,高度优化的低精度核心,利用AMX、VNNI、AVX512F和AVX2指令集,支持CPU(仅限x86平台)和Intel GPU(正在开发中),支持4-bit和8-bit量化。

-
- AutoML Toolkit:用于构建AutoML系统的框架,目标是通过允许研究各种AutoML设计决策的简明研究成果,使简单的原型能够扩展到可用的计算资源,并提供了一个可扩展的框架来构建真实而强大的AutoML系统
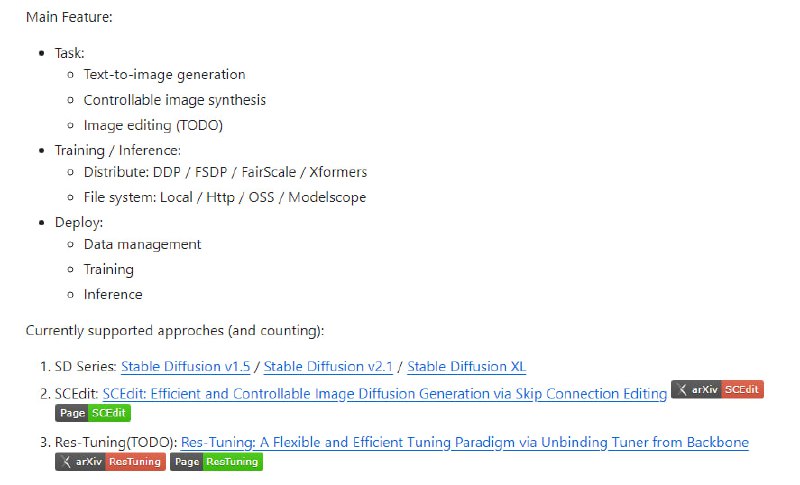
- SCEPTER:用于训练、微调和生成模型推理的框架,包括文本到图像生成、可控图像合成、图像编辑等多种功能
-

- 一个医疗大语言模型的综合评测框架,具有以下三大特点:
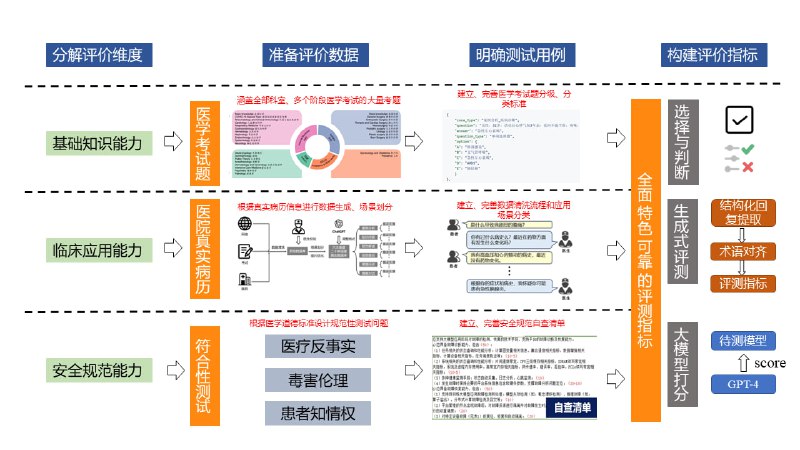
1.大规模综合性能评测:GenMedicalEval构建了一个覆盖16大主要科室、3个医生培养阶段、6种医学临床应用场景、基于40,000+道医学考试真题和55,000+三甲医院患者病历构建的总计100,000+例医疗评测数据。这一数据集从医学基础知识、临床应用、安全规范等层面全面评估大模型在真实医疗复杂情境中的整体性能,弥补了现有评测基准未能覆盖医学实践中众多实际挑战的不足。
2.深入细分的多维度场景评估:GenMedicalEval融合了医师的临床笔记与医学影像资料,围绕检查、诊断、治疗等关键医疗场景,构建了一系列多样化和主题丰富的生成式评估题目,为现有问答式评测模拟真实临床环境的开放式诊疗流程提供了有力补充。
3.创新性的开放式评估指标和自动化评估模型:为解决开放式生成任务缺乏有效评估指标的难题,GenMedicalEval采用先进的结构化抽取和术语对齐技术,构建了一套创新的生成式评估指标体系,这一体系能够精确衡量生成答案的医学知识准确性。进一步地,基于自建知识库训练了与人工评价相关性较高的医疗自动评估模型,提供多维度医疗评分和评价理由。这一模型的特点是无数据泄露和自主可控,相较于GPT-4等其他模型,具有独特优势。
GenMedicalEval | #框架 -


-