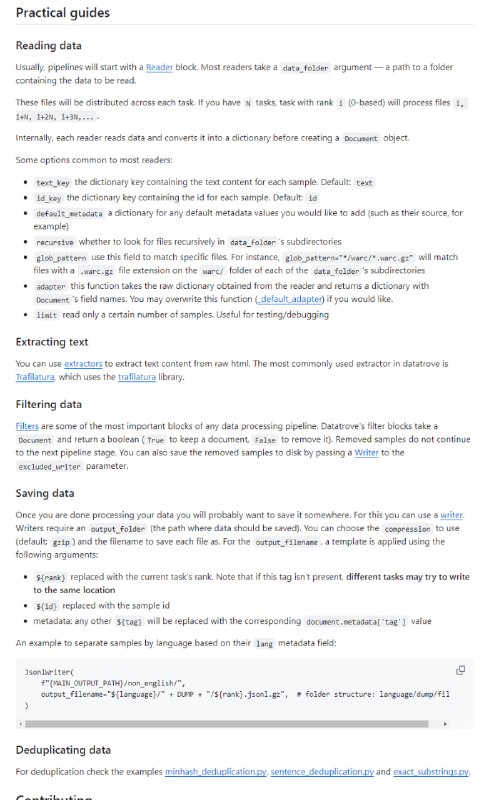
15:17 · Jan 21, 2024 · Sun × DataTrove 是一个用于大规模处理、过滤和删除重复文本数据的库。它提供了一组预构建的常用处理块以及一个框架,可以轻松添加自定义功能。DataTrove 处理管道与平台无关,可以在本地或 slurm 集群上开箱即用。其(相对)较低的内存使用率和多步骤设计使其非常适合大型工作负载,例如处理法学硕士的训练数据。通过fsspec支持本地、远程和其他文件系统。