黑洞资源笔记
-
-
- TextGen:实现了多种文本生成模型,包括:UDA、GPT2、Seq2Seq、BART、T5等模型,开箱即用
UDA(非核心词替换)/EDA:本项目参考Google的UDA(非核心词替换)算法和EDA算法,基于TF-IDF将句子中部分不重要词替换为同义词,随机词插入、删除、替换等方法,产生新的文本,实现了文本扩增
BT(回译):本项目基于百度翻译API实现了回译功能,先把中文句子翻译为英文,再把英文翻译为新的中文
Seq2Seq:本项目基于PyTorch实现了Seq2Seq、ConvSeq2Seq、BART模型的训练和预测,可以用于文本翻译、对话生成、摘要生成等文本生成任务
T5:本项目基于PyTorch实现了T5和CopyT5模型训练和预测,可以用于文本翻译、对话生成、对联生成、文案撰写等文本生成任务
GPT2:本项目基于PyTorch实现了GTP2模型训练和预测,可以用于文章生成、对联生成等文本生成任务
SongNet:本项目基于PyTorch实现了SongNet模型训练和预测,可以用于规范格式的诗词、歌词等文本生成任务
TGLS:本项目实现了TGLS无监督相似文本生成模型,是一种“先搜索后学习”的文本生成方法,通过反复迭代学习候选集,最终模型能生成类似候选集的高质量相似文本
TextGen -
-
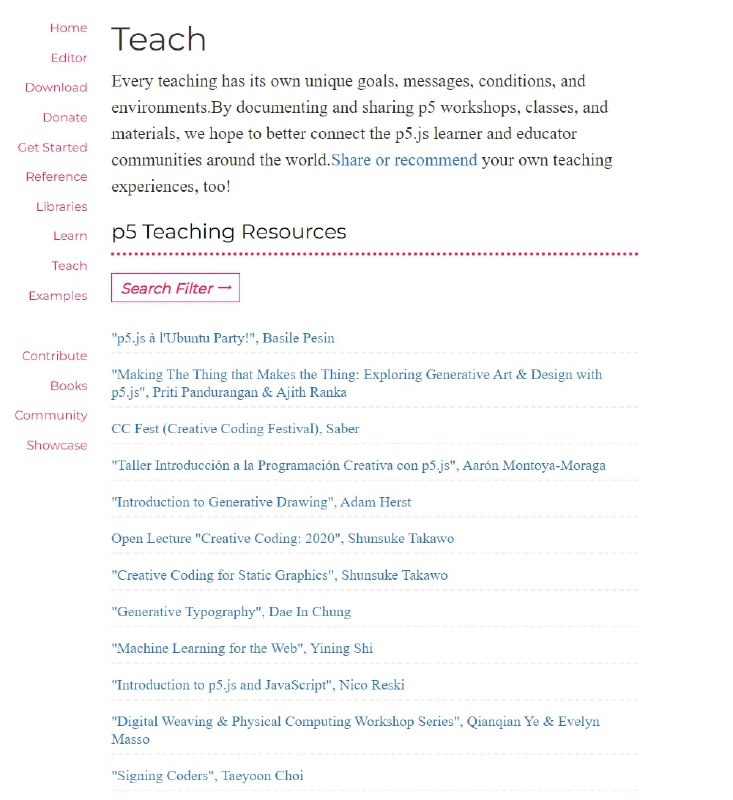
- P5.js一个让艺术家、设计师、教育工作者可以访问编码的JavaScript库
-
-
-
- 这是slack如何决定发送通知的流程图。
这是一个很好的例子,说明为什么一个简单的功能可能需要更长的时间。
这也可以解释为什么人们有时没有收到通知或清除红点。 - 这个叫 html.to.design 的 Figma 插件可以一键把网站导入成设计稿

将任何网站转换为完全可编辑的Figma设计。利用现有网站并将其html导入Figma以开始自己的设计,而无需从头开始构建每个元素。
安装此插件,html.to.design,在空白的 Figma 文件上搜索插件下的“html.to.design”,或使用 cmd+/。在浏览器中打开要转换的网站并复制 URL,将URL粘贴到插件中,选择设备和尺寸,然后单击“导入”将html转换为Figma设计。
传送门 | #工具 #插件 -
- 现代可扩展的Python项目管理器 | Hatch
- 面向文本分析的低代码自动化工具 一个开源的、低代码的、由AI驱动的自动化工具。Obsei由以下部分组成
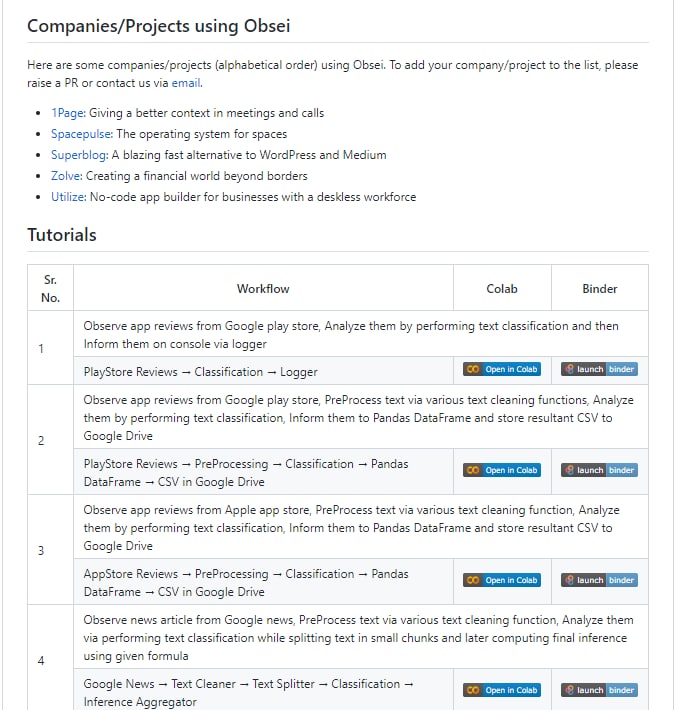
从各种来源收集非结构化数据,如Twitter上的推文、Reddit上的Subreddit评论、Facebook上的页面帖子评论、App Stores评论、Google评论、Amazon评论、新闻、网站等。
分析器。用各种人工智能任务分析收集的非结构化数据,如分类、情感分析、翻译、PII等。
信息员。将分析的数据发送到各种目的地,如票务平台、数据存储、数据框架等,以便用户可以采取进一步的行动,并对数据进行分析。
所有的观察者都可以在数据库(Sqlite、Postgres、MySQL等)中存储他们的状态,这使得Obsei适用于预定作业或无服务器应用程序。
未来的方向--
面向文本、图像、音频、文档和视频的工作流
从所有可能的私人和公共渠道收集数据
将每个可能的工作流程添加到人工智能下游应用中,以实现人工认知工作流程的自动化
obsei | #工具 - 从类似Markdown的文本创建漂亮的级联时间线 | Markwhen
-
-