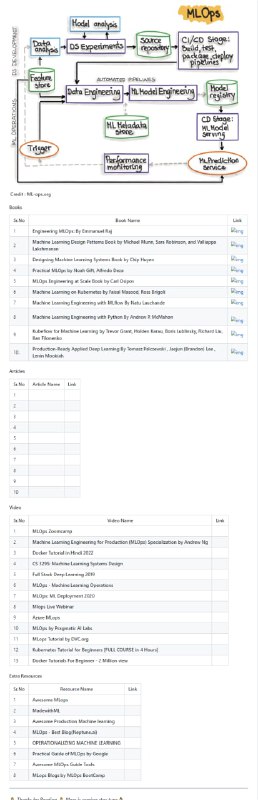
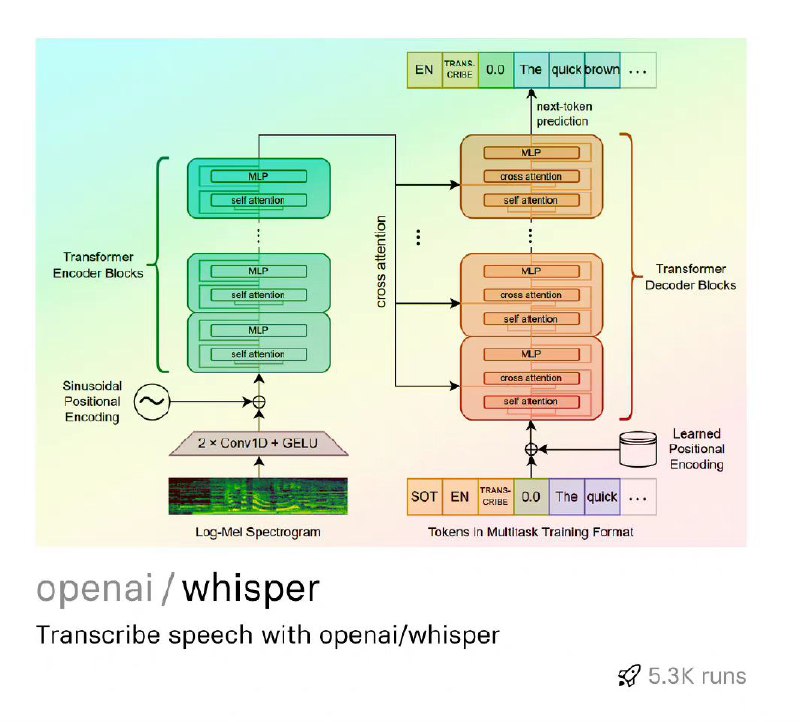
TencentPretrain:腾讯预训练模型框架
预训练已经成为人工智能技术的重要组成部分,为大量人工智能相关任务带来了显著提升。TencentPretrain是一个用于对文本、图像、语音等模态数据进行预训练和微调的工具包。TencentPretrain遵循模块化的设计原则。通过模块的组合,用户能迅速精准的复现已有的预训练模型,并利用已有的接口进一步开发更多的预训练模型。通过TencentPretrain,我们建立了一个模型仓库,其中包含不同性质的预训练模型(例如基于不同模态、编码器、目标任务)。用户可以根据具体任务的要求,从中选择合适的预训练模型使用。TencentPretrain继承了
开源项目UER的部分工作,并在其基础上进一步开发,形成支持多模态的预训练模型框架。
TencentPretrain有如下几方面优势:
可复现 TencentPretrain已在许多数据集上进行了测试,与原始预训练模型实现(例如BERT、GPT-2、ELMo、T5、CLIP)的表现相匹配
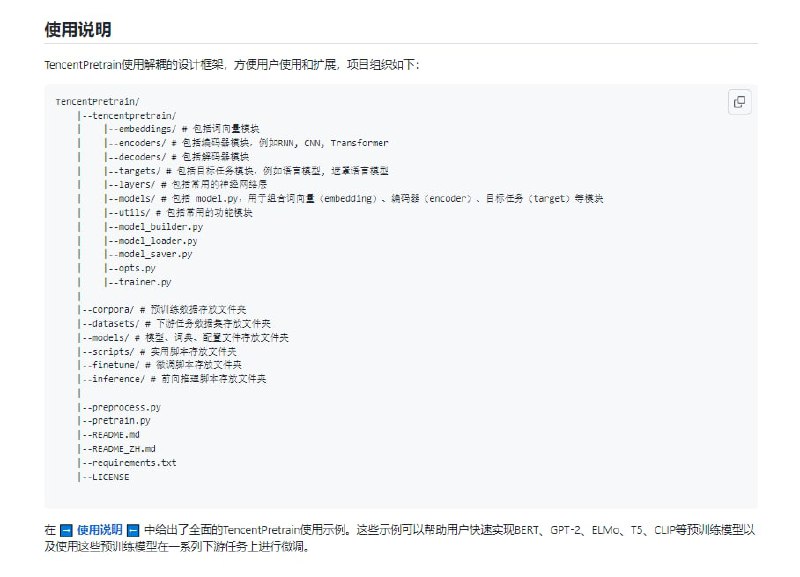
模块化 TencentPretrain使用解耦的模块化设计框架。框架分成Embedding、Encoder、Target等多个部分。各个部分之间有着清晰的接口并且每个部分包括了丰富的模块。可以对不同模块进行组合,构建出性质不同的预训练模型
多模态 TencentPretrain支持文本、图像、语音模态的预训练模型,并支持模态之间的翻译、融合等操作
模型训练 TencentPretrain支持CPU、单机单GPU、单机多GPU、多机多GPU训练模式,并支持使用DeepSpeed优化库进行超大模型训练
模型仓库 我们维护并持续发布预训练模型。用户可以根据具体任务的要求,从中选择合适的预训练模型使用
SOTA结果 TencentPretrain支持全面的下游任务,包括文本/图像分类、序列标注、阅读理解、语音识别等,并提供了多个竞赛获胜解决方案
预训练相关功能 TencentPretrain提供了丰富的预训练相关的功能和优化,包括特征抽取、近义词检索、预训练模型转换、模型集成、文本生成等
项目地址 |
项目文档 |
#框架