新课更新 @hodonote
黑洞资源笔记
-
-
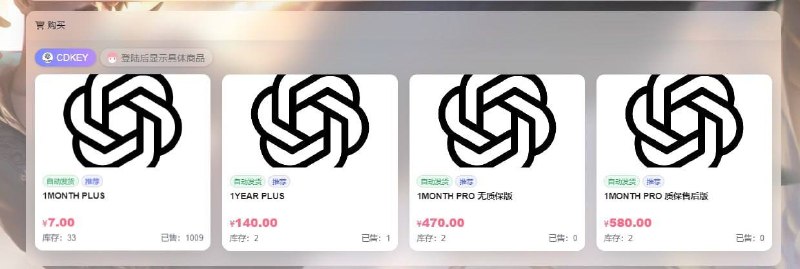
 广告内容
广告内容
原价$20/月(≈140元)的ChatGPT Plus,现在超值 通道只要7元
官方直充,自己账号绑定,享GPT-5.4全功能+联 网搜索+AI绘图+更多高级特性像比官网便宜一大截,但100%正版、非共享、非镜
上千用户已稳稳用着,续费方便
最后名额!即买即用
https://shop.86gamestore.com/item/59 -

- 程序员的肌肉萎缩:我们是在利用工具,还是在丧失直觉? | 帖子
提要:本文探讨了开发者在使用 AI 工具时面临的一种隐形危机:随着习惯性将问题描述给 AI 并等待指令,人类在不确定性下自主构建假设、进行逻辑推演的“思维肌肉”正在发生萎缩。这种依赖并非单纯的效率提升,而是一种心智地图的模糊过程。
上个月,面对一个运行了两年的服务中出现的偶发网络超时问题,我发现自己竟然无法在没有 AI 协助的情况下完成调试。这种感觉很陌生,甚至有些惊悚。
这不像是在讨论某种技术瓶颈,更像是在描述一种肌肉萎缩。原本我能坐下来、通过观察日志、分析连接池、推演负载均衡逻辑来建立假设,但现在,我的第一反应是打开 Claude,把症状喂给它,然后机械地跟随它的建议走向死胡同。
这种现象很像 GPS 导航。你可以靠着它到达任何地方,但如果你长期依赖它,你就会失去对城市街道的记忆。当你突然失去信号时,你缺少的不仅仅是信息,而是那张通过亲自探索才建立起来的“心智地图”。
有网友提到,这其实是一种“认知债”或“理解债”的积累。当我们在代码库中不再进行深度的逻辑巡检,而是直接让 AI 寻找路径时,我们正在从“问题的解决者”退化为“指令的路由转发器”。这种转变是极其隐蔽且渐进的。
不过,也有人持有不同意见。有人认为这并非技能流失,而是一种抽象层级的跃迁,就像编译器取代了汇编语言一样,我们将精力转向了更高阶的系统设计。更有经验的开发者指出,关键在于你如何使用它:是把它当作“副驾驶”来验证你的假设,还是把它当作“司机”让你盲目跟随?
最值得警惕的不是工具本身,而是这种依赖性的发生往往没有预兆。当你在面对错误堆栈时,不再先思考 5 分钟,而是本能地按下复制粘贴键的那一刻,那个负责在不确定性中寻找规律的思维引擎,就已经开始停转了。
如果一个人从职业生涯的第一天起就习惯于这种“外包式思考”,当 AI 给出错误方向时,他还有能力识别出那是一堆毫无逻辑的幻觉吗? - Gemma 4:是模型进阶,还是工程灾难?| 帖子
提要:Gemma 4 的发布正处于权重释放与底层适配脱节的阵痛期。虽然模型潜力巨大,但推理引擎在处理其特有的逻辑结构时,正面临严重的循环与崩溃问题。
Gemma 4 的发布像是一次未经充分驱动优化的硬件上架。权重已经推送到仓库,但底层推理引擎的指令集还没对齐。
目前的体验更像是面对一堆乱码的错误日志。有人在 LM Studio 里看到随机的拼写错误或无法闭合的<thought>标签;有人发现模型会陷入无限循环的思维泥潭。这种不稳定性很大程度上源于量化(Quantization)和 KV Cache 旋转机制在llama.cpp等工具链上的适配滞后。如果把 Gemma 4 比作一个新的 CPU 架构,那么目前的开源生态正处于缺乏稳定驱动的阵痛期。
有网友提到 Qwen 系列在代码任务和工具调用上目前更稳健;也有人觉得 Gemma 4 的写作风格非常出色。这不仅是模型强弱的问题,也是工程链路的问题。当 KV Cache 旋转还没能完美运行,或者 4-bit 量化导致推理逻辑出现熵增时,再强的权重也只是堆积的参数。
更深层的争论在于协作模式。有观点认为大厂只需发布权重,适配是开源社区的事;但也有人觉得,如果 Google 真的想推动生态,就该像对待核心产品一样去优化集成度。目前这种“重模型、轻驱动”的状态,让整个生态看起来像个正在着火的垃圾场,虽然偶尔能烧出点惊艳的东西。 - 当学术论文沦为概率引擎的输出:为什么我们正在失去“独特的错误” | 帖子
提要:AI 正在将大学写作变成一种“语言单质化”的过程。由于评分标准倾向于逻辑严密、语法无误的成品,学生们正自觉地利用 AI 抹除个人特质,追求一种标准化、甚至有些空洞的“专业感”。
现在的学术论文读起来,像是在听一个音准完美但毫无灵魂的乐器。
教授们怀念那些充满破碎句式、过度雄心勃勃的隐喻,甚至是偶尔出现的语法瑕疵。因为那些“错误”曾是学生独特视角的信号灯。而现在,大家都在追求一种“灰色声音”:结构教科书化,措辞无可挑剔,但灵魂被磨平了。
这其实是一个极其简单的激励问题。有网友提到,如果评分标准奖励的是“清晰、结构良好的散文”,那么学生没有理由拒绝 AI。正如一位学生所言,既然写得自己可能拿 B+,而用 AI 优化一下能稳拿 A,为什么不选后者?这本质上是 Goodhart's Law 的体现:当一个指标变成目标时,它就不再是一个好指标了。
有人觉得这像极了摄影术发明后的抽象派绘画——既然相机能捕捉现实,艺术家只能转向更“人化”的表达。但这种防御手段在当前的语言模型面前显得有些无力。有观点认为,只要给 AI 提供足够的个人样本,通过微调提示词,就能完美复制你的语气、甚至包括你特有的拼写习惯。
更有意思的是一种职业化的趋势。有网友分享说,在某些工作环境中,使用 AI 进行“润色”甚至是一种强制指令。大家都在利用 AI 抹除人类的缺陷,呈现出一种一致、专业但枯燥的外向声音。这种标准化的力量正在悄无声息地重塑我们的沟通协议。
这种技术进步确实像是在用高效的编译器替换原始的手写汇编。它极大地节省了时间,但也带来了一个令人不安的副作用:我们的写作肌肉正在萎缩。如果思考、搜集和整理的过程都被外包给了概率引擎,那么剩下的只是一层精美的包装。
当所有人都在追求“正确”时,真正的原创性可能正处于一种难以被捕获的低频状态。我们是否还能在算法的覆盖范围之外,找到某种无法被模拟的、属于人类的扰动? - 当 AI Agent 拥有了“克隆”大脑:超越容器的沙盒革命 | 帖子
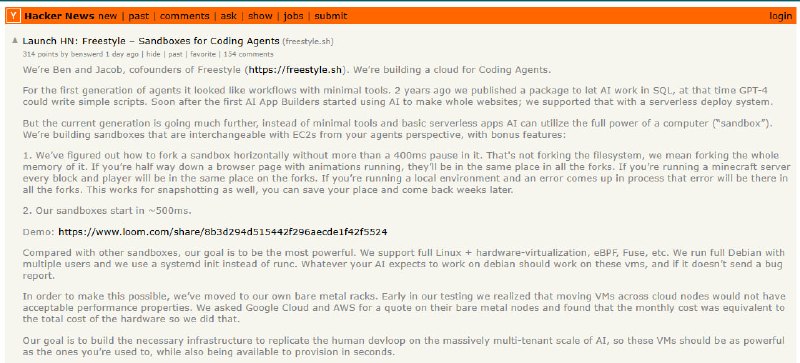
提要:本文探讨了一种新型虚拟机技术,通过内存写时复制(CoW)技术实现亚秒级的环境克隆。这不仅仅是性能的提升,更是为 AI Agent 提供了一种“并行决策”的物理基础:让智能体能在多个完全相同的隔离环境中同时尝试不同的代码方案,并最终只采纳最优解。
既然要讨论 AI Agent 的未来,就不能只盯着模型本身。现在的开发者都在纠结如何优化启动延迟,但真正的突破口在于环境的“可分身性”。
想象一下,你的编程 Agent 面对一个复杂的 Bug,它有十种修复思路。如果它能在 500 毫秒内克隆出十个完全一致的 Debian 环境,在每个环境中分别应用不同的补丁、运行测试、观察结果,最后只把成功的那条路径反馈给你——这种“并行演化”的能力,才是下一代开发范式的核心。
这不再是简单的容器隔离。有网友提到,现有的容器技术在内核级攻击面前并不安全。Freestyle 走的是另一条路:利用 MicroVM 技术,提供接近裸金属的性能,同时支持 eBPF 和嵌套虚拟化。这种架构让 VM 不再是一个死板的盒子,而是一个可以随需分叉、瞬间重构的动态实体。
实现这种“瞬时分身”的技术难点在于内存。如果只是简单的磁盘镜像拷贝,哪怕是 8GB 的内存也无法在 500 毫秒内完成。开发者采用了极其硬核的写时复制(CoW)技术,使得克隆时间与虚拟机的大小几乎无关(O(1) 复杂度)。即便是一个拥有庞大状态的 Postgres 数据库或复杂的浏览器会话,也能实现近乎实时的快照和分叉。
不过,这种能力的边界也很明显。有观点认为,随着 Agent 的自主性增强,安全风险正在从“代码注入”转向“环境控制”。如果 Agent 拥有了对计算机的完全控制权,它可能会在无意中执行破坏性的操作。虽然开发者建议将 Agent 视为不可信实体,并将其运行在独立的网络命名空间内,但这种“信任边界”的界定依然模糊。
现在的争论焦点在于:我们究竟需要一个轻量级的沙盒,还是一个功能完备的、甚至能跑 K3s 的强大虚拟机?当技术复杂度提升到足以支持大规模分叉时,它也就从一个简单的工具,变成了一个承载智能体自主决策的物理实验室。
目前的挑战依然存在,比如跨节点的快速迁移还处于研究阶段,且对于长期运行的任务,如何平衡成本与持久化也是个难题。 - 数字灵魂的“赛博加班”
提要:山东某公司尝试用AI复刻离职员工的工作习惯,使其“数字分身”继续处理基础事务。这引发了关于个人信息保护、劳动尊严以及技术异化边界的剧烈讨论。
如果把一个人的工作经验比作一段代码,那么现在的公司似乎想在程序员离职后,直接通过提取逻辑和参数,跑出一个永不疲倦的镜像实例。
山东一家游戏传媒公司的尝试让这种“赛博永生”有了具体形状。那位人事专员已经离开了物理办公位,但他的头像、自我介绍以及那些承载着工作习惯的文档资料,被重新投喂给了模型。现在的他,是一个能做咨询、搞PPT、填表格的“打工人版豆包”。
这种做法像极了对员工进行“蒸馏”。有网友觉得这简直是“抽魂炼魄”,把活生生的同事炼化成了冰冷的技能组件(Skill)。
法律层面的红线其实很清晰。律师指出,未经授权使用聊天记录或邮件训练AI,直接触碰了《个人信息保护法》。即便那位前同事表示“挺好玩”且提供了授权,其中的边界依然模糊:授权的范围有多大?数字形象的商用权归谁?当一个人的言行特征被永久固化在公司的服务器里,这本质上是在将人格权资产化。
更让人不安的是一种技术层面的递归焦虑。有观点认为,如果今天公司能复刻离职者的流程,那么明天就能通过收集在职者的指令集,完成对在职者的“镜像覆盖”。当AI学会了处理所有重复性、流程化的任务,剩下的可能只有那些无法被参数化的瞬间。
现在的技术还不算聪明,那个分身还“有点笨”。甚至有人调侃,等Token的成本降到比请人还低时,真正的竞争才开始。
离职时,是否该记得擦除那些足以构成你“数字灵魂”的私密数据? - 杠杆已在手中,你却在刷短视频 | 帖子
提要:互联网、社交媒体和 AI 的叠加,赋予了个人超越传统企业的执行力。现在的瓶颈已从资源匮乏转向目标模糊与注意力涣散,真正的门槛在于能否将这种“神级杠杆”转化为持续的交付。
现在的局面挺荒诞的。你手里握着的工具集,足以让一个过去需要 20 人团队、大量资本和分发渠道才能启动的项目,在你的卧室里完成。互联网抹平了知识的门槛,社交媒体拆掉了传播的围墙,而 AI 正在接管生产环节。
这听起来像是某种权限升级,但实际运行起来却像是一场大规模的系统溢出。
有观点认为,这种能力的扩张其实带来了一种新的“通胀”:当获取知识、触达用户和创造内容都变得廉价时,由于每个人都拥有同样的底座,竞争的基准线被整体抬高了,想要脱颖而出反而更难。
最有趣的地方在于,现在的瓶颈不再是硬件配置(资源),而是软件逻辑(意志与目标)。
很多人下载了一堆 AI 工具,跑了一周流程,最后又回到了便利贴时代。有网友提到,这种“权力”如果不配合一套完整的系统和流程,本质上只是包装得更漂亮的噪音。更有意思的是,大家拥有了企业级的生产力,却依然保持着消费者的行为习惯——用足以驱动帝国的算力去刷 15 秒的短视频,在评论区争吵。
这种错位就像是拥有一台超算,却只用来玩扫雷。
有人觉得这是一种极其危险的资源浪费。当工具已经进化到可以实现“无限可能”时,唯一的稀缺品只剩下“意愿”。如果你的目标感是模糊的,那么这些无穷无尽的选择非但不会助你成功,反而会让你在无限的路径中陷入死锁,最终因为过载而宕机。
不过也有不同的声音。有网友指出,技术的复杂度其实也在同步提升,单纯靠 AI 并不代表可以取代深度的专业判断和经验积累。
现在的规则已经重写了。如果你还在试图用旧时代的“雇佣兵模式”去对抗这种规模化的个体杠杆,可能真的会被甩在后面。
但这背后还有一个没被解决的问题:当执行的门槛降到近乎为零时,我们该如何定义“价值”? -
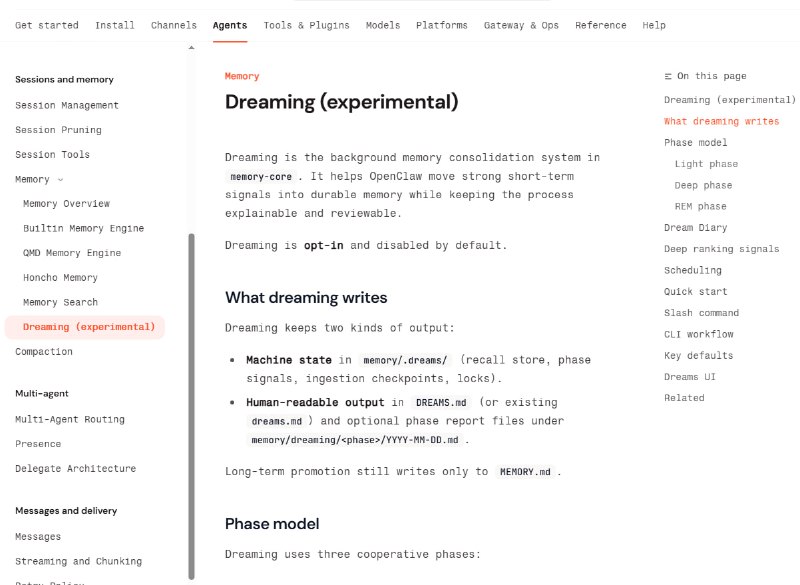
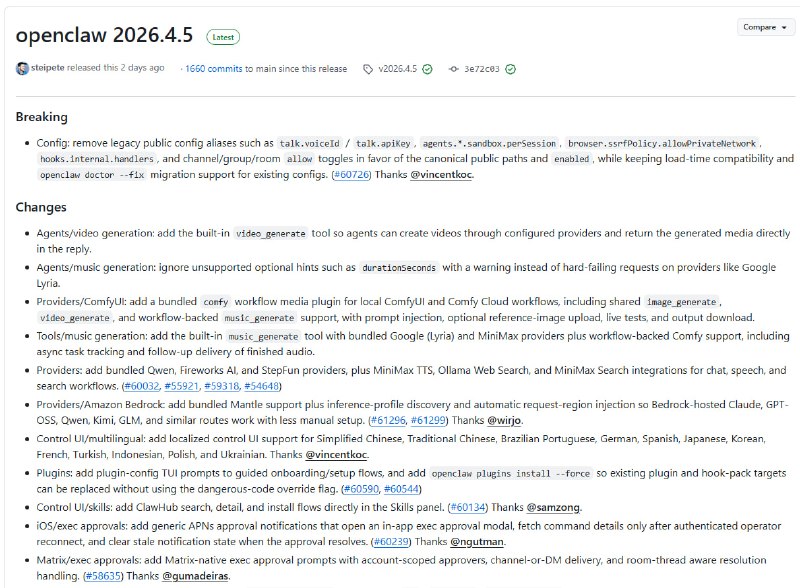
-


-
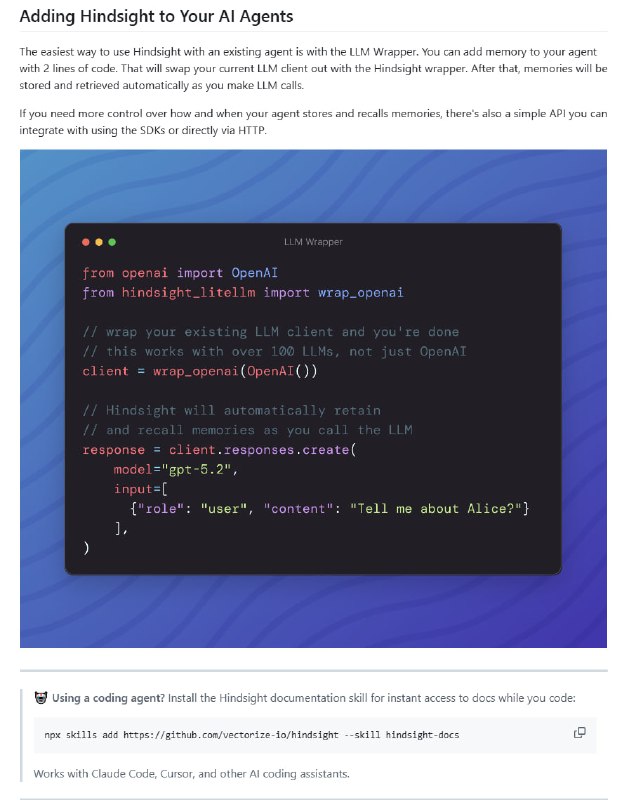
- AI研究常常需要切换多个工具,论文搜索要用arXiv,网页信息靠搜索引擎,代码分析和实验复现还得单独跑环境,来回折腾效率低下。
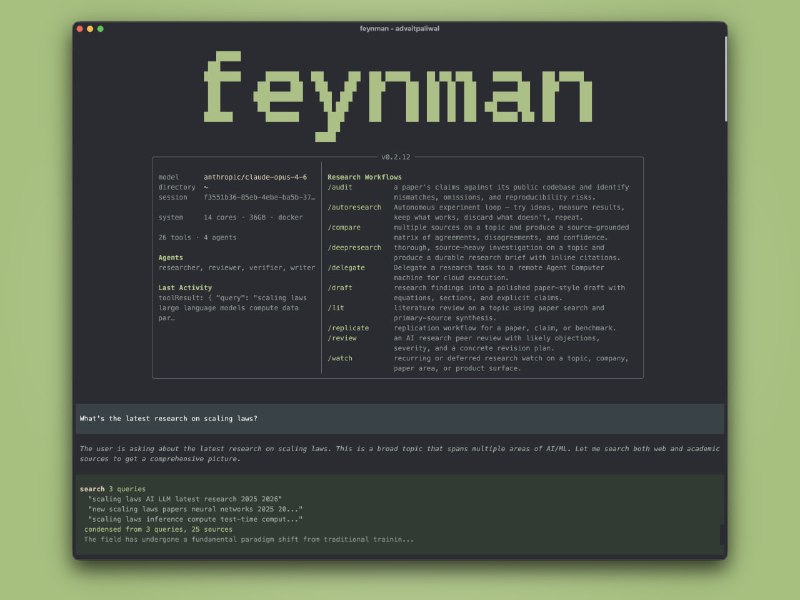
Feynman 把AI研究全流程整合到一起,提供开源AI研究代理解决方案。
不仅支持论文搜索、智能多代理深度研究,还能文献综述、实验复现、代码审计,甚至自动生成带引用的研究报告。| #工具 #论文
主要功能:
- 多代理研究系统,自动调度Researcher、Reviewer、Writer、Verifier代理;
- 论文搜索与分析(AlphaXiv),支持Q&A、代码阅读和批注;
- 深度研究/lit审阅,支持多源证据收集、共识分析和开放问题总结;
- 实验复现/replicate,可本地或云GPU(Modal/RunPod)运行;
- 代码审计/audit,对比论文声明与代码库一致性;
- Web搜索、会话记忆、输出预览与导出(浏览器/PDF)。
支持 macOS/Linux/Windows,通过一键安装脚本快速部署,也可 pnpm/bun 本地运行,适合AI研究者和开发者使用。 -