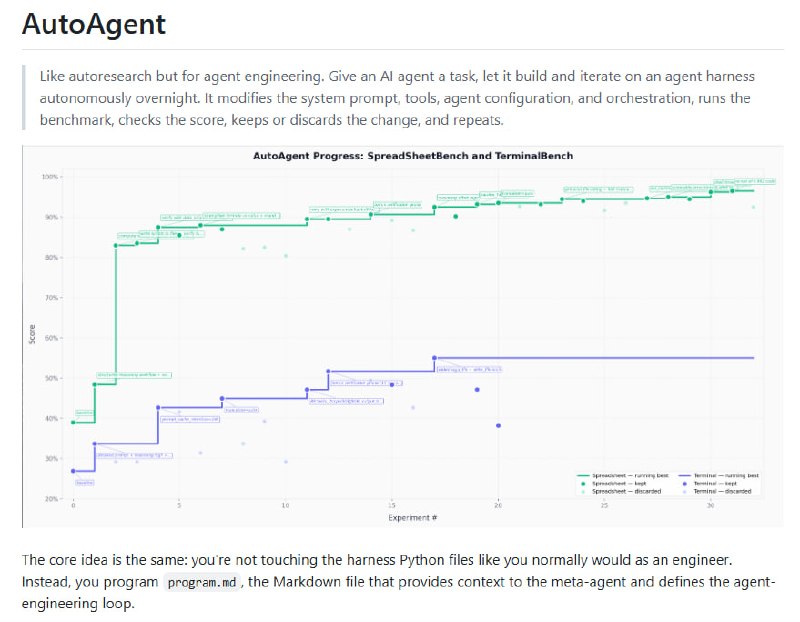
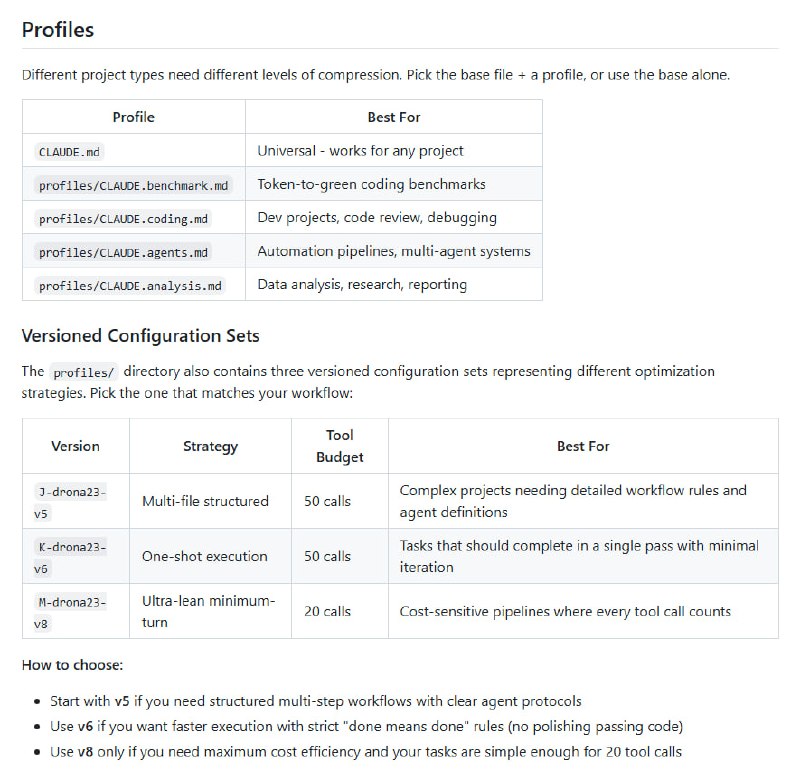
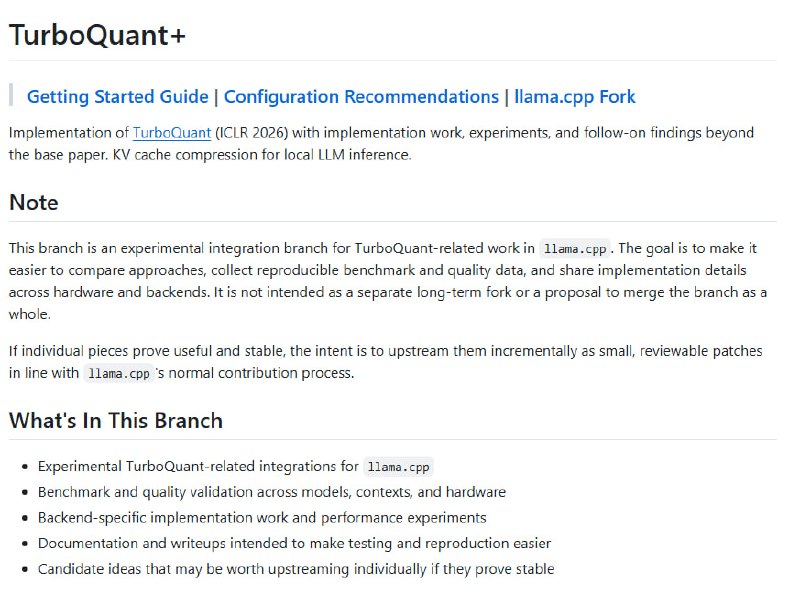
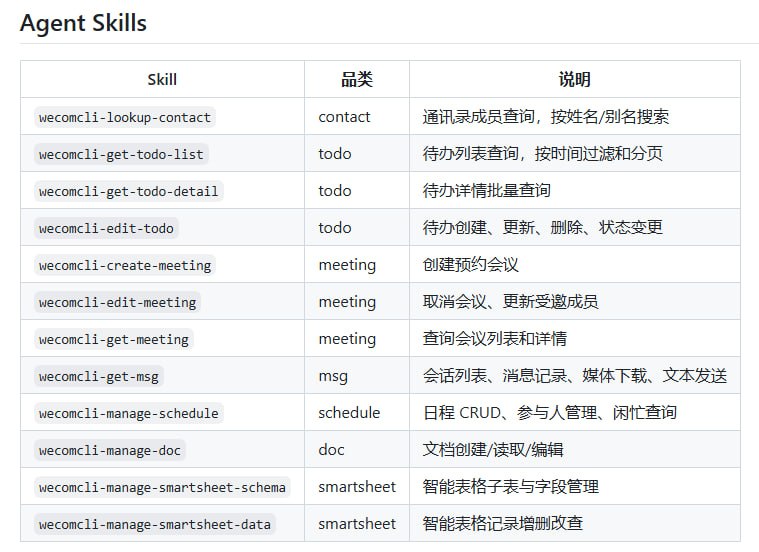
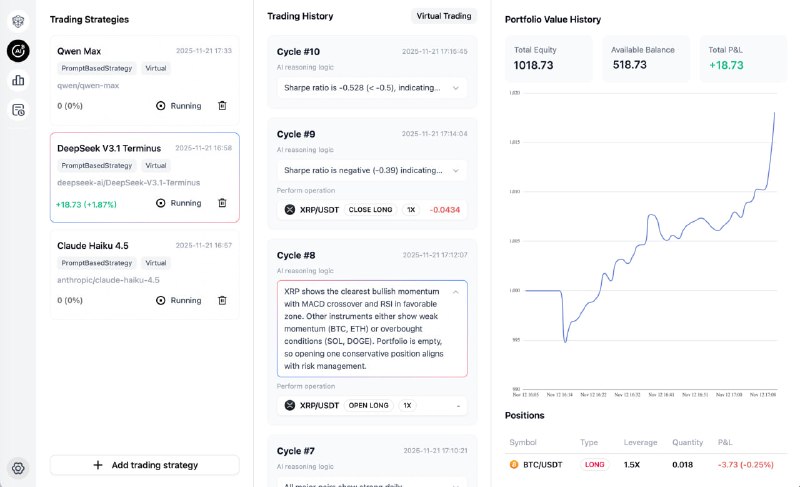
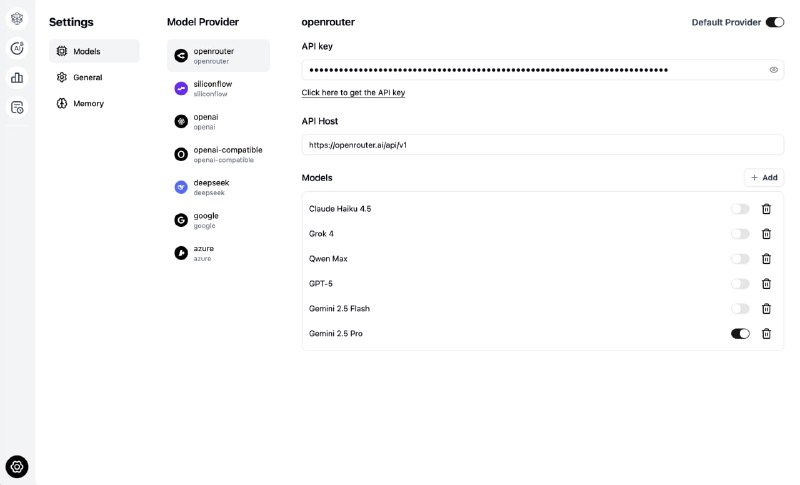
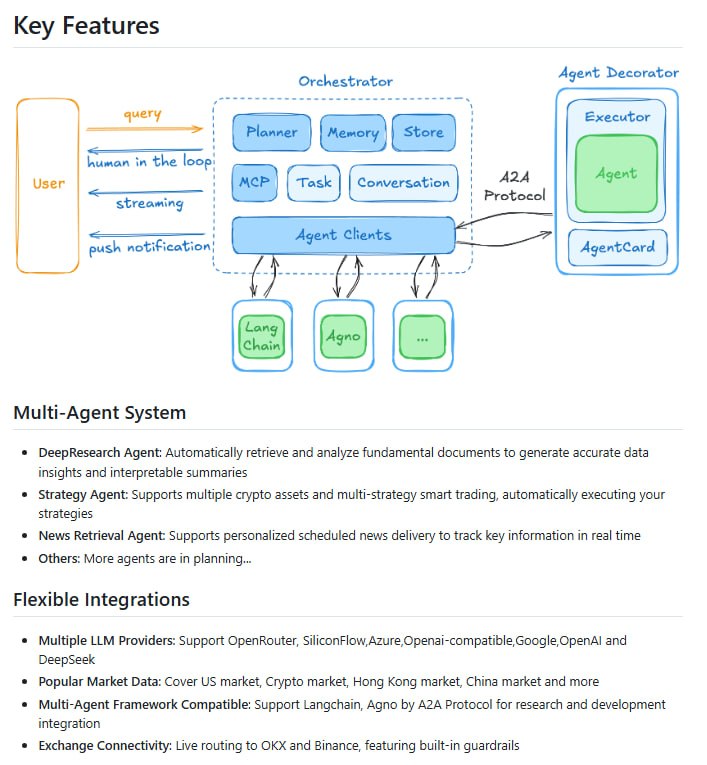
独立开发者 7 天复现 Google 顶级算法:
TurboQuant+ 开启本地大模型长文本新纪元
Google 在 ICLR 2026 论文中提出的 TurboQuant 算法曾引发内存行业震动,但官方至今未释出代码。独立开发者 Tom Turney 凭借数学功底,在 Claude 的辅助下仅用 7 天便完成了从理论到工程的跨越,且性能超越了 Google 的官方承诺。
+ 工程奇迹的 7 天演进
- 第 1-3 天:构建核心算法,通过 141 项测试,完成 Python 原型开发。
- 第 3-5 天:将代码移植至 llama.cpp,并手写 Metal GPU 内核。
- 第 5-7 天:极致性能调优,将吞吐量从 739 提升至 2747 tok/s,实现 3.7 倍速跃升。
+ 超越原著的深度优化
Tom 并未止步于复现,他在原论文基础上增加了多项原创研究:
- Sparse V(稀疏 V 解码):在长文本语境下跳过 90% 的 Value 向量解压,显著降低计算开销。
- 非对称 K/V 压缩:保持 Key 向量的高精度以确保注意力路由准确,同时对 Value 向量进行更激进的压缩。
- 时间衰减压缩:自动降低旧 Token 的存储精度,进一步释放内存。
+ 实测性能与意义
在 MacBook M5 Max 上,该项目实现了 4.6 倍的 KV Cache 压缩,使得 35B 规模的模型能在消费级硬件上流畅运行长文本。这不仅是工程上的暴力美学,更是对“大厂发布论文,小团队实现商业化”这一现状的有力回应。
+ 深度思考:AI 时代的工程杠杆
过去从论文发布到工业级实现往往需要数年,如今在 AI 辅助工具和开源社区的加持下,这个周期被缩短到了一个周末。大厂负责定义未来的边界,而拥有强大行动力的个体正在负责交付未来。当沟通成本消失,个体的杠杆率正达到前所未有的高度。
- 大厂发布的是路线图,但总得有人把车造出来。
- 研发实验室在为建设者预览未来,而建设者在废墟上直接交付生产力。
- AI 辅助开发的本质,是坍缩了“理解论文”与“交付代码”之间的鸿沟。