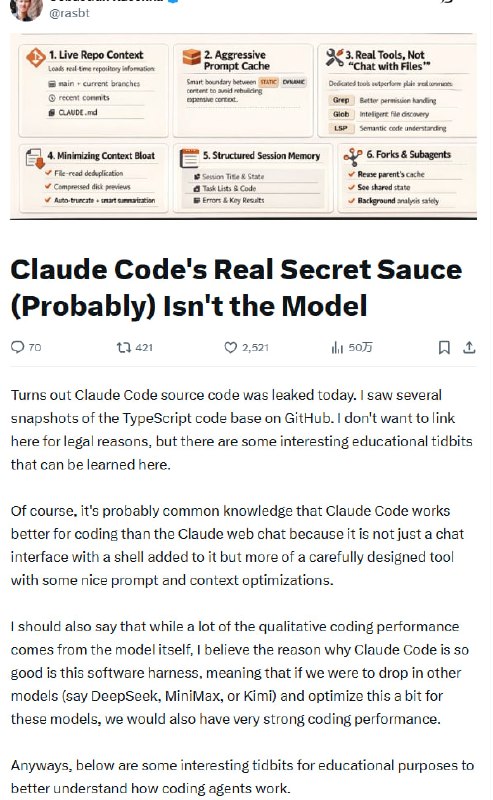
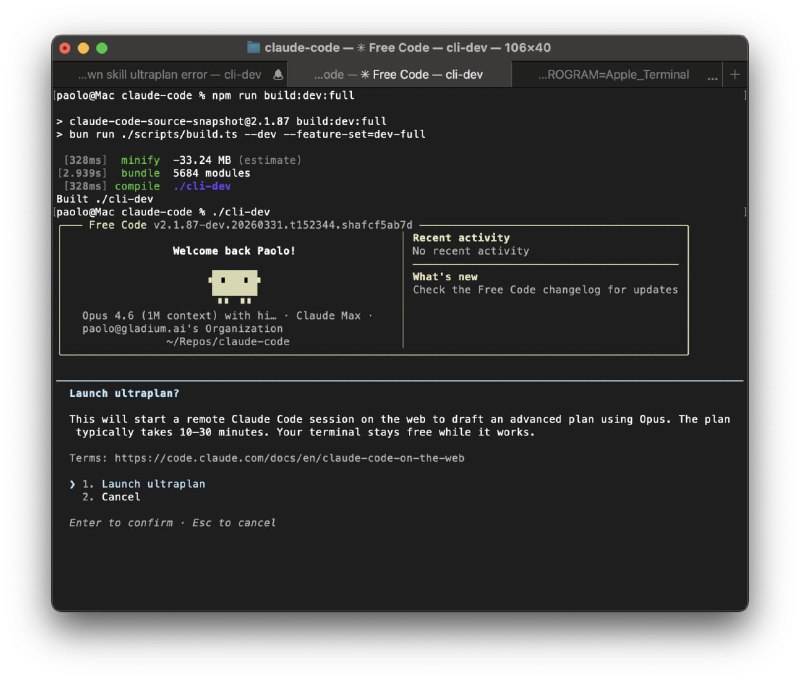
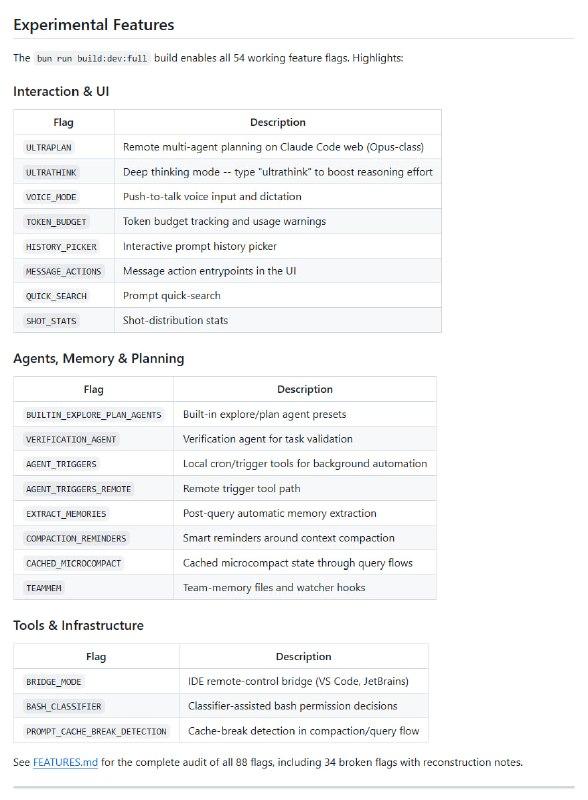
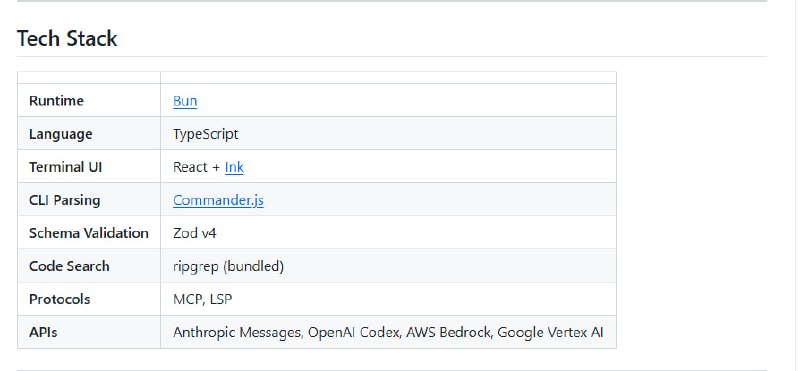
AI一人公司年入150万,但门槛比你想的高得多
杭州创业者武培文用AI智能体替代90%执行工作,一人公司年营收150万、月成本仅3000元。这个故事真实,但他背后是8年跨境营销经验和Meta硅谷团队的履历,AI放大的是他本来就有的东西。
武培文给自己的AI团队起了名字:Minion负责抓竞品数据,Sage做投放策略,Quill生成多语种文案,还有个执行体处理客户沟通。他自己只做决策和验收。月成本3000元,净利润率超65%,日均接单8到10单,客单价3000到5000美元。
这个数字在网上引起广泛讨论,很多人问的第一个问题是:我能复制吗?
大概率不能,至少不能直接复制。武培文在Meta硅谷团队待过,年薪超20万美元,跨境营销做了8年,90%的营收来自长期合作客户。他搭的那套自动化流程,核心不是会用AI工具,而是把行业认知拆解成了机器能执行的规则,比如“广告ROI低于1:3自动暂停”。这种规则只有真的在这个行当里摸爬滚打过的人才写得出来。
AI是放大器,不是起点。
有网友提到,真实体验是“身体自由但心力更累”,凌晨睡觉、决策孤独,所有风险一个人扛。一人公司不是一个人轻松赚团队的钱,是一个人把团队的活全干了,只是有些活交给了机器。
杭州的政策确实给了助力:免租金、创业基金、算力补贴,这些降低了试错成本。但政策铺的是路,能不能走下去,看的是你在这条路上原本积累了什么。
社交平台上涌现出大量“0基础AI年入百万”的课程,收费从几千到几万不等,部分已被警方通报为诈骗。幸存者偏差的问题在这里格外明显,你看到的是那个成功的人,看不到的是一百个调试失败、收益不及预期、最后悄悄放弃的人。
有意思的对比是中美路径的分化:美国方向是高研发投入加订阅制,OpenAI年亏损超90亿美元还在烧;中国方向是直接切产业端,降本增效,政策托底,场景化快速变现。武培文这个案例,恰好是后一条路走通的一个样本。
他的意义不在于“普通人也能年入150万”,而在于证明了一件事:当AI足够强,行业认知可以被工程化,然后让机器跑着。但工程化这件事本身,需要你先把认知攒够。
问题是,大多数人想跳过攒认知这一步。
杭州创业者武培文用AI智能体替代90%执行工作,一人公司年营收150万、月成本仅3000元。这个故事真实,但他背后是8年跨境营销经验和Meta硅谷团队的履历,AI放大的是他本来就有的东西。
武培文给自己的AI团队起了名字:Minion负责抓竞品数据,Sage做投放策略,Quill生成多语种文案,还有个执行体处理客户沟通。他自己只做决策和验收。月成本3000元,净利润率超65%,日均接单8到10单,客单价3000到5000美元。
这个数字在网上引起广泛讨论,很多人问的第一个问题是:我能复制吗?
大概率不能,至少不能直接复制。武培文在Meta硅谷团队待过,年薪超20万美元,跨境营销做了8年,90%的营收来自长期合作客户。他搭的那套自动化流程,核心不是会用AI工具,而是把行业认知拆解成了机器能执行的规则,比如“广告ROI低于1:3自动暂停”。这种规则只有真的在这个行当里摸爬滚打过的人才写得出来。
AI是放大器,不是起点。
有网友提到,真实体验是“身体自由但心力更累”,凌晨睡觉、决策孤独,所有风险一个人扛。一人公司不是一个人轻松赚团队的钱,是一个人把团队的活全干了,只是有些活交给了机器。
杭州的政策确实给了助力:免租金、创业基金、算力补贴,这些降低了试错成本。但政策铺的是路,能不能走下去,看的是你在这条路上原本积累了什么。
社交平台上涌现出大量“0基础AI年入百万”的课程,收费从几千到几万不等,部分已被警方通报为诈骗。幸存者偏差的问题在这里格外明显,你看到的是那个成功的人,看不到的是一百个调试失败、收益不及预期、最后悄悄放弃的人。
有意思的对比是中美路径的分化:美国方向是高研发投入加订阅制,OpenAI年亏损超90亿美元还在烧;中国方向是直接切产业端,降本增效,政策托底,场景化快速变现。武培文这个案例,恰好是后一条路走通的一个样本。
他的意义不在于“普通人也能年入150万”,而在于证明了一件事:当AI足够强,行业认知可以被工程化,然后让机器跑着。但工程化这件事本身,需要你先把认知攒够。
问题是,大多数人想跳过攒认知这一步。