
用大模型编译你的第二大脑 | 帖子
Karpathy分享了一套用LLM构建个人知识库的工作流,核心是把原始资料“编译”成结构化wiki,让LLM持续维护、查询和增强这个知识库,而不只是回答一次性问题。这套方法正在引发广泛讨论,不少人已独立摸索出了类似路径。
大多数人用LLM的方式,像是每次都重新烧开一壶水,用完就倒掉。Karpathy的做法是在烧水之前先挖一口井。
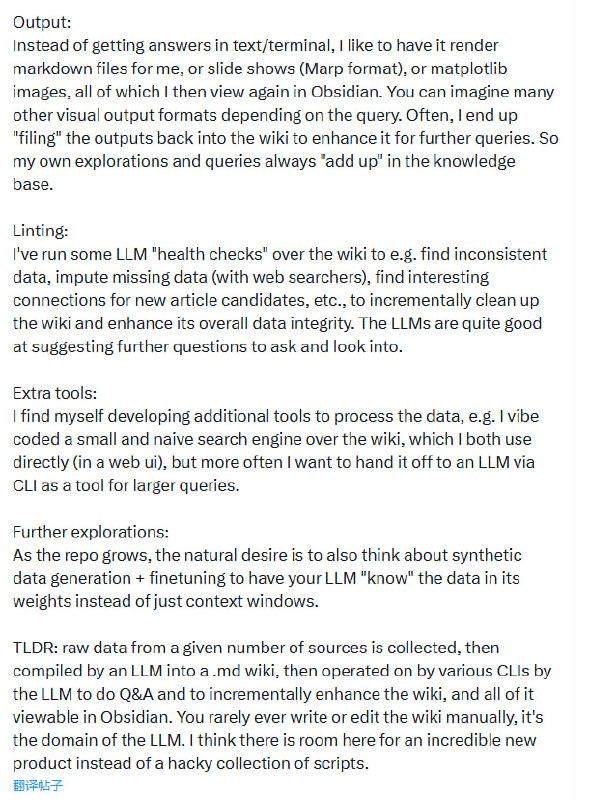
具体流程是这样:把论文、文章、代码库、图片等原始资料扔进raw/目录,让LLM把它们“编译”成一个wiki,也就是一堆.md文件,有摘要、有反向链接、有概念条目、有交叉引用。前端用Obsidian查看。重要的是,这个wiki几乎不需要你手动写一个字,全部由LLM维护。
当wiki积累到一定体量,比如100篇文章、40万字,你就可以对着它问复杂问题了。LLM会自己去检索、综合、给出答案,然后你可以把答案“归档”回wiki,下次查询的起点又高了一截。每一次探索都在给知识库加砖,而不是消耗完就散。
有观点认为,这套方案最有价值的地方,在于知识连接的可能性是指数级增长的。500条笔记,取任意4个主题做交叉推演,组合数达到620亿条路径。stoic哲学、SaaS定价、病毒式传播、育儿,LLM真的可以找到这条路径上某个有用的东西。
有意思的地方在于,Karpathy提到自己不需要复杂的RAG架构。LLM自动维护索引文件和摘要,在这个规模下读相关文档不费力气。那些准备好搭复杂向量数据库的人,可能先白忙了。
有网友提到,自己把9个月的编程会话全部导出成markdown,建了SQLite全文索引,现在可以直接说“那个音频桥接的问题我们是怎么解的”,几秒钟出来。没有向量数据库,没有embedding,只有markdown加grep。他说这套东西让他在9个月里造了50多个工具,涵盖全栈、OSINT管线、本地CUDA推理,还帮赛车店分析了ECU数据。
“每家公司都有一个raw/目录,只是从来没有人编译过它。”
Karpathy本人对这句话的反应是:说得对,就是这个。
这件事的终点可能是:向frontier LLM提一个问题,自动召唤一组LLM,临时构建一个wiki,lint一遍,循环几轮,生成完整报告。远不是.decode()能描述的事情。
至于这个工作流最终会长成一个产品,还是永远是每个人自己的一堆脚本,这个问题目前没有答案。Karpathy说“我觉得这里有空间做出一个了不起的产品”,但他自己还没动手。
Karpathy分享了一套用LLM构建个人知识库的工作流,核心是把原始资料“编译”成结构化wiki,让LLM持续维护、查询和增强这个知识库,而不只是回答一次性问题。这套方法正在引发广泛讨论,不少人已独立摸索出了类似路径。
大多数人用LLM的方式,像是每次都重新烧开一壶水,用完就倒掉。Karpathy的做法是在烧水之前先挖一口井。
具体流程是这样:把论文、文章、代码库、图片等原始资料扔进raw/目录,让LLM把它们“编译”成一个wiki,也就是一堆.md文件,有摘要、有反向链接、有概念条目、有交叉引用。前端用Obsidian查看。重要的是,这个wiki几乎不需要你手动写一个字,全部由LLM维护。
当wiki积累到一定体量,比如100篇文章、40万字,你就可以对着它问复杂问题了。LLM会自己去检索、综合、给出答案,然后你可以把答案“归档”回wiki,下次查询的起点又高了一截。每一次探索都在给知识库加砖,而不是消耗完就散。
有观点认为,这套方案最有价值的地方,在于知识连接的可能性是指数级增长的。500条笔记,取任意4个主题做交叉推演,组合数达到620亿条路径。stoic哲学、SaaS定价、病毒式传播、育儿,LLM真的可以找到这条路径上某个有用的东西。
有意思的地方在于,Karpathy提到自己不需要复杂的RAG架构。LLM自动维护索引文件和摘要,在这个规模下读相关文档不费力气。那些准备好搭复杂向量数据库的人,可能先白忙了。
有网友提到,自己把9个月的编程会话全部导出成markdown,建了SQLite全文索引,现在可以直接说“那个音频桥接的问题我们是怎么解的”,几秒钟出来。没有向量数据库,没有embedding,只有markdown加grep。他说这套东西让他在9个月里造了50多个工具,涵盖全栈、OSINT管线、本地CUDA推理,还帮赛车店分析了ECU数据。
“每家公司都有一个raw/目录,只是从来没有人编译过它。”
Karpathy本人对这句话的反应是:说得对,就是这个。
这件事的终点可能是:向frontier LLM提一个问题,自动召唤一组LLM,临时构建一个wiki,lint一遍,循环几轮,生成完整报告。远不是.decode()能描述的事情。
至于这个工作流最终会长成一个产品,还是永远是每个人自己的一堆脚本,这个问题目前没有答案。Karpathy说“我觉得这里有空间做出一个了不起的产品”,但他自己还没动手。