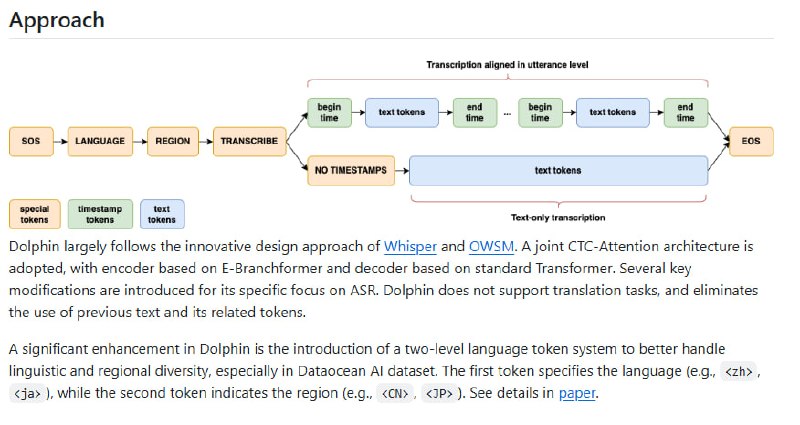
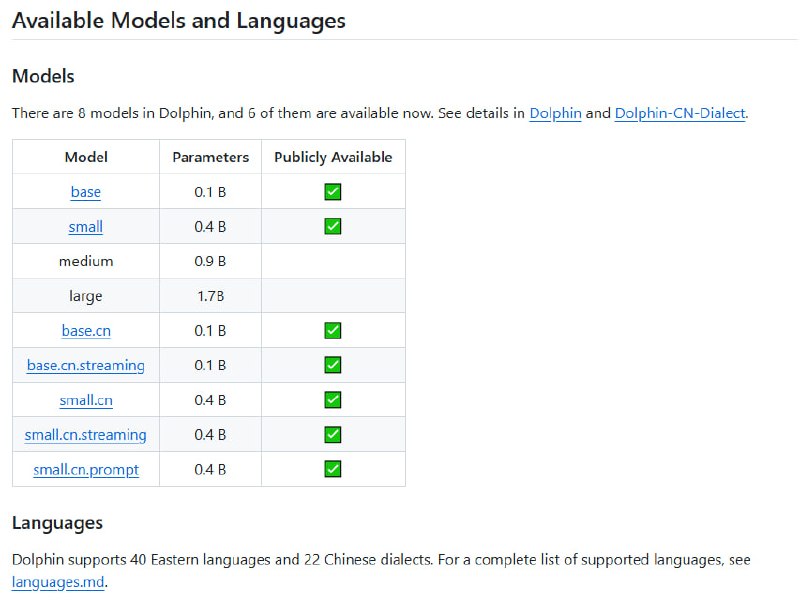
Dolphin 是 DataoceanAI 与清华大学联合研发的多语种、多任务语音识别模型。它支持东亚、南亚、东南亚及中东 40 种东方语言,以及 22 种中国方言,训练数据超过 21 万小时,可同时完成语音识别、语音活动检测、分段和语种识别。
项目提供 base、small、medium、large 等不同规模模型,以及针对中文方言优化的 small.cn、small.cn.prompt 等变体,支持词级时间戳预测与热词偏置功能。安装后仅需一条命令即可在命令行或 Python 中快速调用。
代码与模型权重均采用 Apache-2.0 许可开源,欢迎开发者与研究者下载使用。