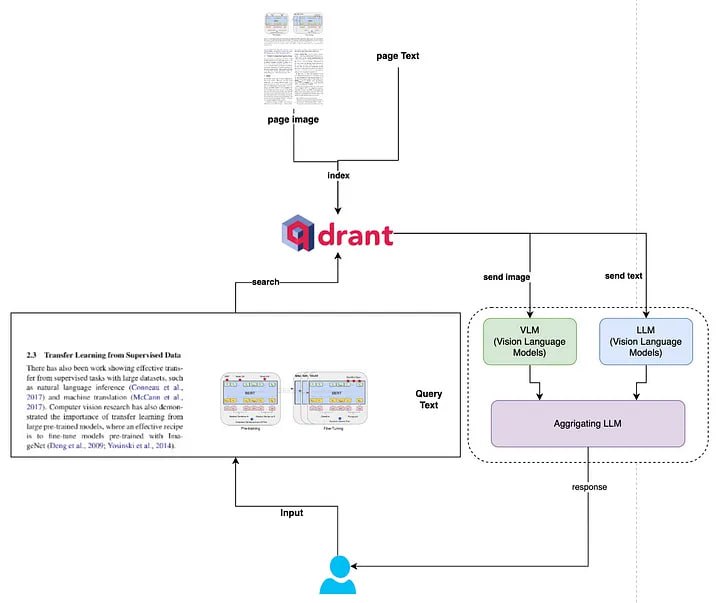
- 传统 RAG 只处理文本内容, 而这个系统同时处理文本和图像
- 对 PDF 文档的每一页同时提取文本和图像信息
- 使用 Qdrant 向量数据库存储文本和图像的双重向量表示
技术实现细节:
- 文本处理: 使用文本嵌入模型处理提取的文本
- 图像处理: 使用 CLIP 模型处理页面图像
- 向量存储: Qdrant 支持每个文档存储多个向量
- 视觉分析: 集成了 OpenAI 的视觉语言模型
查询处理流程:
- 接收用户查询
- 使用向量相似度检索最相关的前 3 个结果
- 将查询和检索到的图像传递给视觉语言模型
- 聚合文本检索和视觉分析的结果
- 生成综合的回答
主要优势:
- 可以"理解"文档的视觉布局和格式
- 提供更丰富的上下文信息
- 能够处理图表、图像等非文本内容
- 回答更准确, 并能提供视觉证据支持