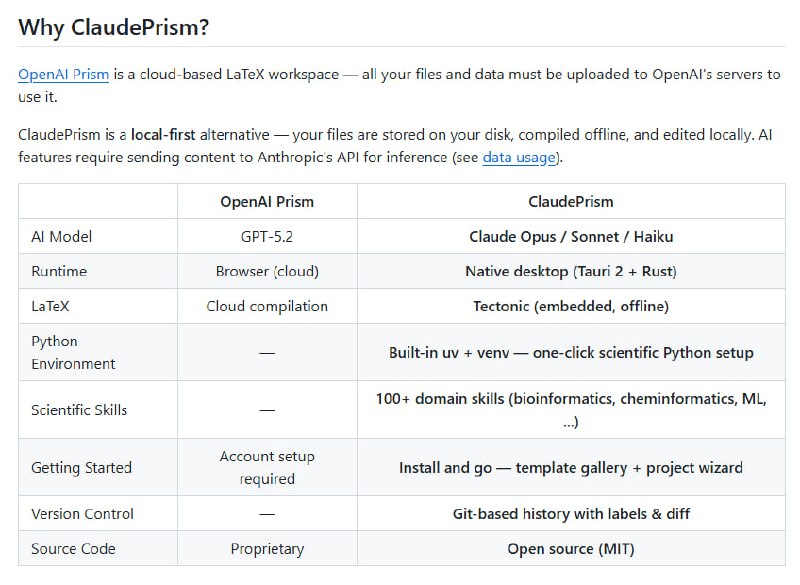
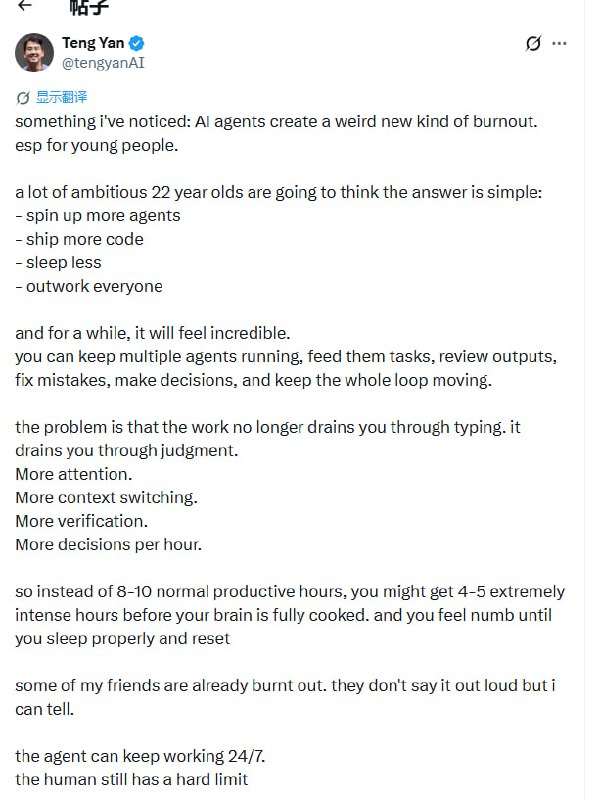
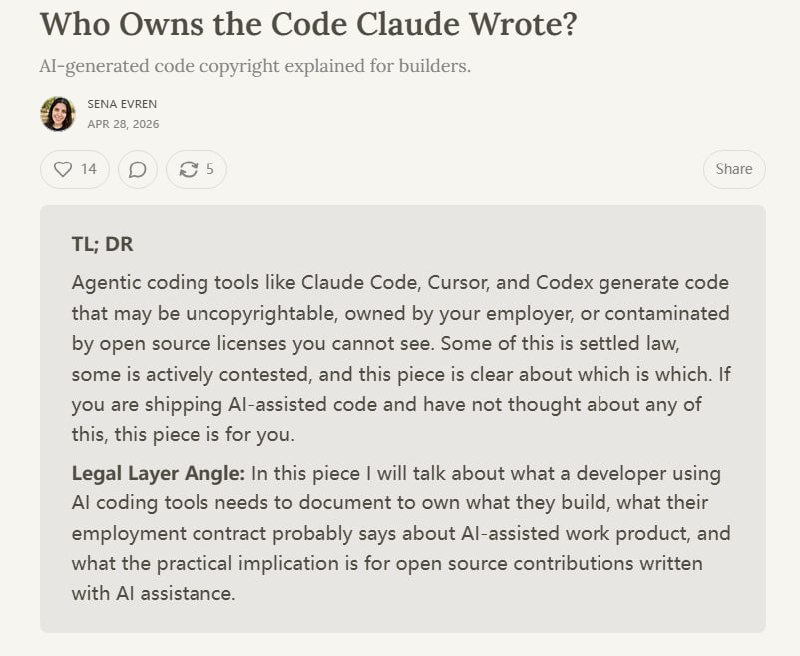
给 Claude Code 接上「整个代码库」的语义搜索 |
claude-context大模型 context window 再大,也有上限。真正的工程项目动辄几十万行代码,没法一次性全塞进去。Zilliz 开源的 claude-context 解决的就是这个问题:把你的代码库向量化存进数据库,让 Claude Code 在需要时按语义检索相关代码片段——而不是每次都把整个目录加载进 context。
1. 核心机制
代码不是以文件为单位存储,而是先用 AST(抽象语法树)做智能分块,再通过 OpenAI embedding 模型向量化,存入 Milvus / Zilliz Cloud 向量数据库。
检索时用的是混合搜索:BM25 关键词匹配 + 向量语义搜索,两种方式的结果合并排序,相关性比单纯向量搜索准。
官方测评数据:在同等检索质量下,减少约 40% 的 token 消耗。代码库越大,节省越明显。
2. 增量索引
用 Merkle Tree 跟踪文件变化,只重新索引改动的文件,不需要每次全量跑一遍。
3. 安装方式极简
对 Claude Code 来说,加完claude-context 之后,在 Claude Code 里直接说「Index this codebase」,等索引完成,就可以用自然语言检索了:「找所有处理用户认证的函数」。
4. 兼容范围
不只 Claude Code,Cursor、Codex CLI、Gemini CLI、Windsurf、VS Code、Cline 全都支持,都是改 MCP 配置文件,几行 JSON 搞定。
支持的编程语言:TypeScript、Python、Java、Go、Rust、C++、C Sharp、Ruby、Swift 等主流语言。
Embedding 也可以换:除了 OpenAI,还支持 VoyageAI(voyage-code-3,代码搜索效果更好)、Ollama 本地模型、Gemini。
5. 本质上
Claude Code 默认的代码理解方式是:你告诉它看哪里,它看哪里。这个工具把它升级成:你问它一个问题,它自己去整个代码库里找相关的部分,带上来给你用。
对于中大型项目,这个差距很明显——不用再手动 (at)file 指定文件,不用担心忘了哪个关键模块,Agent 的自主性和准确性都会提升。