黑洞资源笔记
-
- 给 Claude Code 接上「整个代码库」的语义搜索 | claude-context
大模型 context window 再大,也有上限。真正的工程项目动辄几十万行代码,没法一次性全塞进去。Zilliz 开源的 claude-context 解决的就是这个问题:把你的代码库向量化存进数据库,让 Claude Code 在需要时按语义检索相关代码片段——而不是每次都把整个目录加载进 context。
1. 核心机制
代码不是以文件为单位存储,而是先用 AST(抽象语法树)做智能分块,再通过 OpenAI embedding 模型向量化,存入 Milvus / Zilliz Cloud 向量数据库。
检索时用的是混合搜索:BM25 关键词匹配 + 向量语义搜索,两种方式的结果合并排序,相关性比单纯向量搜索准。
官方测评数据:在同等检索质量下,减少约 40% 的 token 消耗。代码库越大,节省越明显。
2. 增量索引
用 Merkle Tree 跟踪文件变化,只重新索引改动的文件,不需要每次全量跑一遍。
3. 安装方式极简
对 Claude Code 来说,加完claude-context 之后,在 Claude Code 里直接说「Index this codebase」,等索引完成,就可以用自然语言检索了:「找所有处理用户认证的函数」。
4. 兼容范围
不只 Claude Code,Cursor、Codex CLI、Gemini CLI、Windsurf、VS Code、Cline 全都支持,都是改 MCP 配置文件,几行 JSON 搞定。
支持的编程语言:TypeScript、Python、Java、Go、Rust、C++、C Sharp、Ruby、Swift 等主流语言。
Embedding 也可以换:除了 OpenAI,还支持 VoyageAI(voyage-code-3,代码搜索效果更好)、Ollama 本地模型、Gemini。
5. 本质上
Claude Code 默认的代码理解方式是:你告诉它看哪里,它看哪里。这个工具把它升级成:你问它一个问题,它自己去整个代码库里找相关的部分,带上来给你用。
对于中大型项目,这个差距很明显——不用再手动 (at)file 指定文件,不用担心忘了哪个关键模块,Agent 的自主性和准确性都会提升。 -



- 《逻辑学简短入门》牛津通识读本的重译版 | #电子书
Graham Priest 的 Logic: A Very Short Introduction 是牛津通识系列中的一本。该书在众多逻辑学入门书中独树一帜,并不试图完整介绍逻辑学的理论,而是通过一些哲学难题或逻辑谜题引入解决这些问题的逻辑理论和方法,在介绍逻辑知识的同时展示逻辑可以如何来用。
译者wxflogic发现之前的翻译有些术语不太准确,所以重新翻译了一下。 - clawd.rip:claude翻车史,记录了claude的每一次翻车事故。

- Matt Pocock 的 skills 在 GitHub Trending 榜上突然爆发——短短一天内新增超过 5600 颗 Star,总 Star 数突破 3 万,成功登顶。
Matt 是一个 TypeScript 课程作者,最近一年多在教开发者如何真正用好 AI 编程。他最近在 AI Engineer 上的演讲被放了出来,反响不错。应该是这个演讲让他的 skills 翻红。
Matt Pocock 认为:软件工程基本功在 AI 时代比以往任何时候都更重要。
Matt 把 AI 编程中常见的问题归纳为六个失败模式(见评论区),他的 Skills 仓库里的每一个工具,基本上都对应其中一个,很多论据则来自软件工程领域的一些书籍和概念。
这些技能不是孤立工具,它们可以构成一套完整的工作流。
github | youtube:link1 link2 - warp开源,并得到了OpenAI 的赞助支持
-


- 建筑设计经常需要昂贵的专业软件如AutoCAD或Revit,年费动辄数万美元,还得安装桌面客户端,跨平台协作麻烦重重。
Pascal Editor 把3D建筑设计全流程搬到浏览器,提供免费开源的完整解决方案。
基于React Three Fiber和WebGPU的高性能渲染,支持实时编辑建筑/楼层/墙体/区域,支持层叠/爆炸/独立视图显示,还内置撤销重做、几何系统生成和空间碰撞检测。
主要功能:
- 完整的节点层级:Site→Building→Level→Wall/Slab/Zone/Item,支持实时编辑和几何生成;
- GPU加速3D渲染,墙体倒角、CSG切割门窗、楼板多边形生成;
- 智能系统更新,仅重渲染脏节点,高效性能;
- 撤销/重做(Zundo)、IndexedDB持久化存储场景;
- 空间网格管理,支持物品放置验证和楼板高度计算;
- 工具系统:墙体绘制、区域创建、物品摆放、选择/变换工具。
支持Web浏览器直接运行,通过bun dev本地开发,14.6k星标,适合建筑师、设计师和初学者快速原型设计。 - AI 领域目前有两条职业路径:API Caller(只会调用 API,低杠杆、易被自动化,15 万刀薪资)和 Architect(能从零构建模型,高杠杆、50 万刀+ 薪资)。
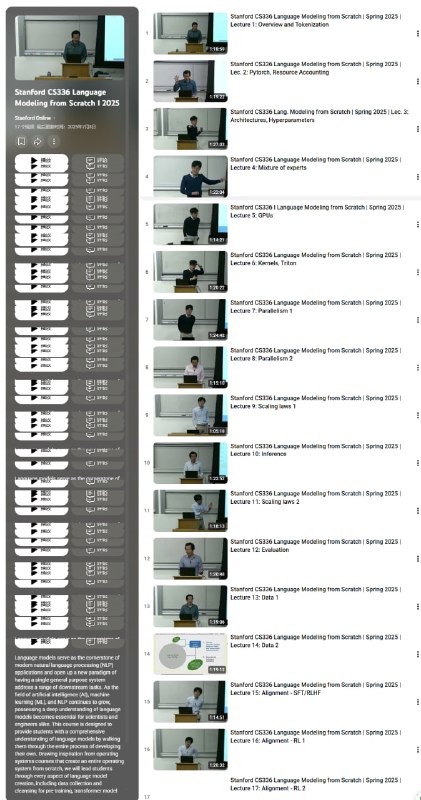
斯坦福 CS336《Language Modeling from Scratch》这份免费 17 讲视频课程,教你成为 Architect,从零打造语言模型。| #教程
课程纯干货、无废话:数据收集与清洗(Lec 13-14)、构建 Transformer & MoE(Lec 3-4)、加速优化(Lec 5-8:GPU、内核、并行)、推理部署(Lec 10)、对齐与 RL(Lec 15-17)
主要内容:
- 数据收集与精炼,确保训练集高质量;
- 从头构建 Transformer 和 MoE 架构;
- 性能优化:GPU 编程、自定义内核、并行计算;
- 高效推理引擎,实现实时部署;
- 对齐训练与 RL,提升模型智能与安全性;
- 完整从零到一的语言模型开发流程。
适合有编程基础的学习者,自学即可上手,助力 AI 工程师转型高薪 Architect。 -
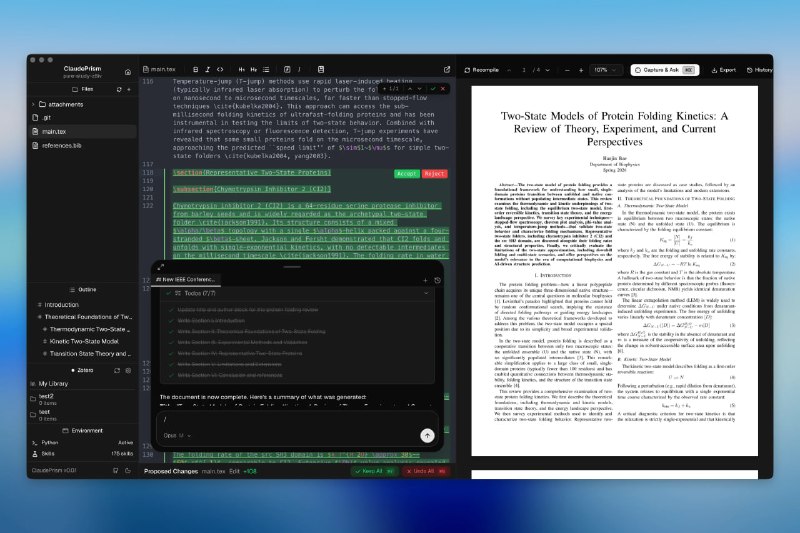
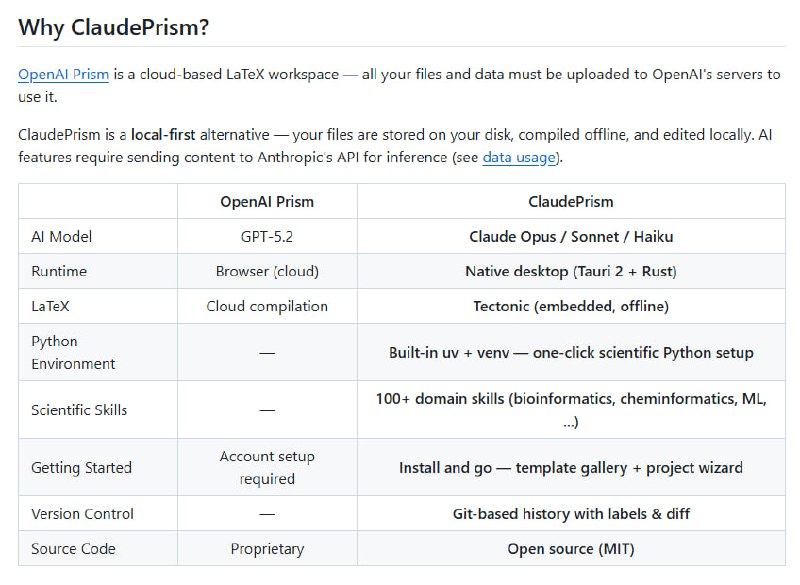
- 别再迷信 AI Agent 躺平工作:体力减负,脑力负荷翻倍 | 帖子
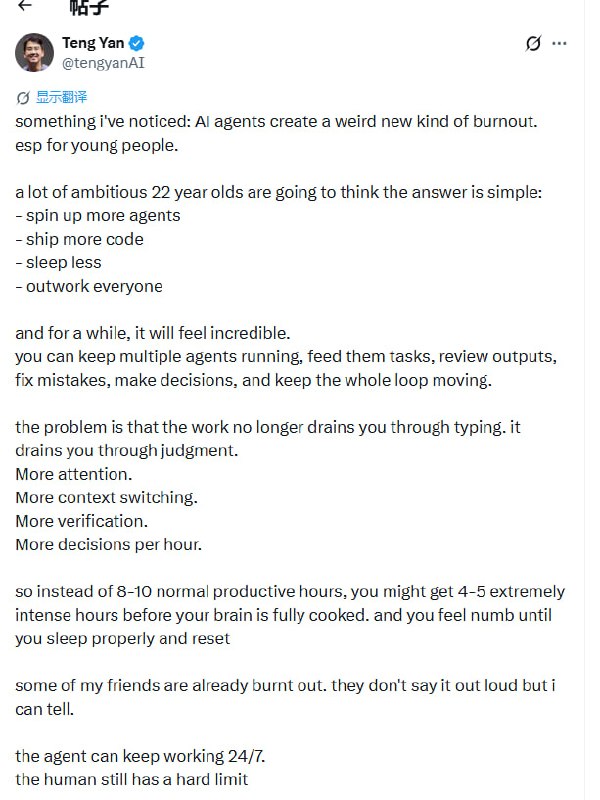
AI Agent 并没有真正减轻工作量,而是通过消除执行层面的体力消耗,将压力转移到了高频的决策与审核上。这种从“体力输出”向“判断力输出”的转变,正在制造一种新型的、更深层的精神倦怠。
很多人觉得有了 Agent 就能实现“睡后生产”,觉得只要多开几个智能体、多写点 Prompt、少睡会儿觉就能跑赢所有人。这种感觉在初期确实很爽,就像给原本单线程的 CPU 挂载了无数个协程。
但问题在于,工作的消耗逻辑变了。
以前的累是“肌肉记忆”式的,是敲键盘、写代码时的体力消耗,这种疲劳是有自然停顿点的。现在的累是“上下文切换”式的。Agent 可以 24/7 不间断地跑,但人类的判断力有硬上限。当执行被自动化后,瓶颈就从“写”变成了“审”。
你不再是那个搬砖的工人,而是一个被迫时刻待命的监工。
有网友提到,Agent 并没有消除压力,反而扩大了你必须负责的“责任面积”。你会陷入一种无止境的 Review Loop:Agent 几分钟就能生成一堆东西,你却得花几小时去仔细核对。这种高频的决策、验证和纠错,会迅速榨干你的认知带宽。
甚至有人感慨,Agent 的记忆问题其实就是人类的倦怠问题。Agent 每次启动都是全新的,而你得带着上一轮决策的疲惫、错误的残余和切换上下文的眩晕进入下一场战斗。
这种状态很像是在一台不断提速的跑步机上,你以为自己在利用杠杆,其实只是在被压缩的节奏里加速透支。
当生产力不再受限于“手速”,而受限于“脑速”时,真正的挑战变成了:在无限的自动化流水线面前,如何守住那点极其稀缺的判断力。 -

- 按量计费来袭,AI 订阅模式的经济骗局藏不住了 | blog

当前的AI订阅模式掩盖了极其恐怖的推理成本。当企业开始从“包月”转向“按量计费”时,这场由补贴驱动的泡沫正面临最严峻的经济学审判。
现在的AI订阅制,本质上是一场关于成本的集体失明。
如果把大模型比作电力,现在的厂商就像是在卖一种“包月无限用”的套餐,却对用户隐瞒了电费其实贵得离谱的事实。你以为每月20美元买到的是效率,实际上你是在用厂商的补贴在玩一场“赌博”。一旦厂商意识到,某些深度用户通过Agent进行长上下文编程时,单次对话消耗的Token成本可能高达十几美元,他们就会毫不犹豫地从“包月”转向“按量计费”。
GitHub Copilot 的变动只是个信号。
这背后的逻辑极其残酷:目前的AI商业模式建立在一个脆弱的假设之上——推理成本会像摩尔定律一样快速下降。但现实是,随着推理模型(Reasoning Models)变得越来越复杂,单次任务的算力消耗反而呈指数级增长。
有网友提到,这就像是Uber在补贴油价。如果Uber告诉你每月20美元可以无限打车,但实际上每加一升油都要你额外付钱,你还会觉得这生意划算吗?
更深层的危机在于基础设施的错配。像Oracle这样的大厂正在为OpenAI的宏伟蓝图抵押整个未来。如果OpenAI无法在未来几年内实现天文数字般的营收增长,这些耗资千亿、建立在债务之上的数据中心将变成吞噬现金的黑洞。
当所有的“先进性”都建立在对真实成本的掩盖之上,这种繁荣看起来更像是一场大型的财务工程。
当补贴退去,当账单不再模糊,我们究竟是在购买生产力,还是在为一场注定会破裂的幻觉支付溢价?