黑洞资源笔记
-
- 别让 AI,废掉你的编程内功 | blog

快速阅读:LLM 降低了开发门槛,却也带来了技能萎缩的风险。当编写代码变成一种低成本的指令任务,唯有通过刻意练习保持底层深度的人,才能在大量“批量化垃圾”中建立差异化优势。
代码生产正在进入大规模流水线时代。这种转变由三种力量驱动:社交媒体对交付速度的狂热、模型性能持续进化的确定性,以及人类天生的惰性。既然可以通过指令直接获取可运行的结果,谁还会愿意去忍受那种由于思考底层逻辑带来的痛苦?
这种趋势正在重塑工程师的生态位。当技能门槛降低,原本属于“键盘巫师”的领地正被大量具备业务逻辑的人群挤占。如果仅仅满足于做一个 Prompt Monkey,竞争对手将不再是其他开发者,而是产品经理、设计师甚至前任管理者。
有观点认为,这其实是建立技术护城河的绝佳时机。就像工业革命初期的铁匠,当拖拉机取代了耕犁,懂得处理复杂机械结构的人反而更具价值。未来的竞争力在于成为“T型”人才:在软件工程之外,叠加物理、材料或算法等深层领域的专业知识。代码正逐渐退化为一种应用工具,真正的难点在于解决领域内的本质问题。
当 AI 生成的代码充斥着看似正确却逻辑隐晦的缺陷时,谁能一眼看出其中的架构风险?技术底层的深度,决定了你在面对 Agentic Engineering 时,是驾驶者,还是被其驱动的零件。 -

- 软件工程师转 AI 工程师:不是转行,是基于工程底蕴的进化 | Google Drive

从软件工程师(SWE)转型为 AI 工程师,不是一次推倒重来的“转行”,而是一次基于工程底蕴的“进化”。
Lamhot Siagian 在其最新的 2026 职业转型指南中明确指出:AI 时代的下半场,市场不再需要只会调用 API 的 demo 制造者,而是在寻找能将不确定性的 AI 转化为确定性产品的工程专家。
以下是这份指南的核心洞察与深度行动建议:
1. 范式转移:从确定性到概率性
传统软件工程的核心是“确定性”:给定输入 A,通过逻辑 B,必然得到输出 C。但 AI 系统是概率性的,输出具有随机性和上下文敏感性。
软件工程师的真正优势不在于重新学习微积分,而在于将成熟的工程直觉引入这个混沌领域。你过去处理边缘情况、设计监控指标、优化系统可靠性的经验,正是 AI 进入生产环境最稀缺的资源。
2. 核心能力栈:五层演进模型
转型并非漫无目的的学习,而应遵循清晰的层级:
- 基础层:精进 Python 深度,理解异步处理与服务化思维。
- 原理层:不一定要能手推公式,但必须理解模型如何学习、如何评估以及在哪里会失效。
- 生成式 AI 层:掌握 Embedding、向量数据库与 RAG(检索增强生成)的架构设计。
- 工程系统层:这是 SWE 的主场。关注编排(Orchestration)、数据库集成与云端部署。
- 应用层:通过构建 Agent(智能体)系统和决策引擎,将技术转化为商业价值。
3. 避开“教程陷阱”,构建差异化作品集
不要再在简历里写“泰坦尼克号生存预测”或简单的聊天机器人 demo 了。
2026 年的雇主希望看到的是:
- 能够处理 5 亿级文档嵌入的 RAG 系统。
- 带有自我修复能力的智能体工作流。
- 包含完整评估框架(Evaluation Harness)的项目,证明你能客观衡量 AI 的好坏。
4. 简历策略:翻译你的工程资产
不要把自己定位成“AI 新手”,而要定位成“具备 AI 能力的高级工程师”。
- 将“调试经验”翻译为“模型评估与指标设计能力”。
- 将“CI/CD 经验”翻译为“持续评估与 AI 质量保证能力”。
- 将“系统设计”翻译为“端到端 AI 工作流编排”。
5. 深度思考:工程化是 AI 的最后公里
现在的 AI 行业正从“模型中心”转向“系统中心”。模型本身正在商品化,真正的护城河在于如何围绕模型构建一个鲁棒的系统。
启示:
- AI 工程师的价值,不在于模型跑通的那一刻,而在于模型出错时,你有一套系统能接住它。
- 别被数学公式吓倒,AI 的本质是数据流的重新编排。
- 优秀的 AI 工程师,是那个能在概率的荒野上,筑起确定性围墙的人。
如果你正在寻找一份实操性极强的 24 周学习计划,这份指南提供了从数学基础到 MLOps 监控的全路径覆盖。 -
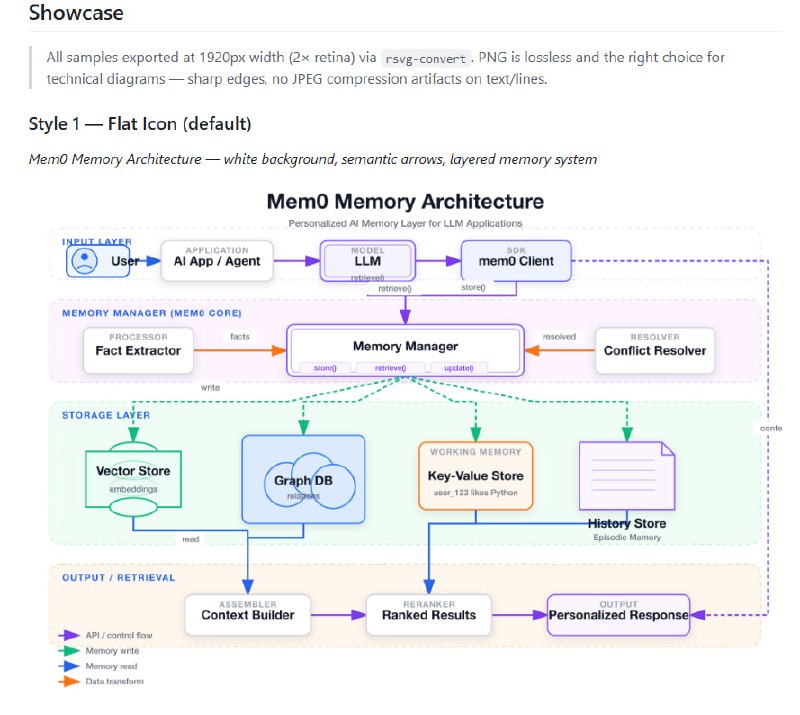
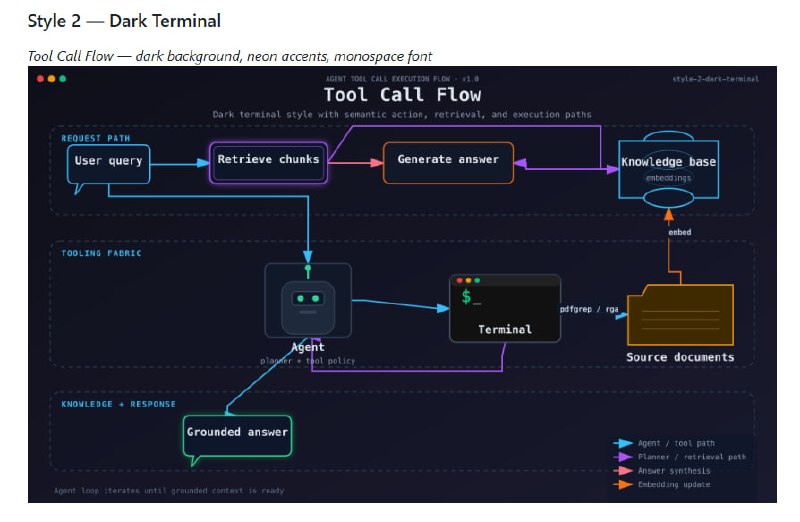
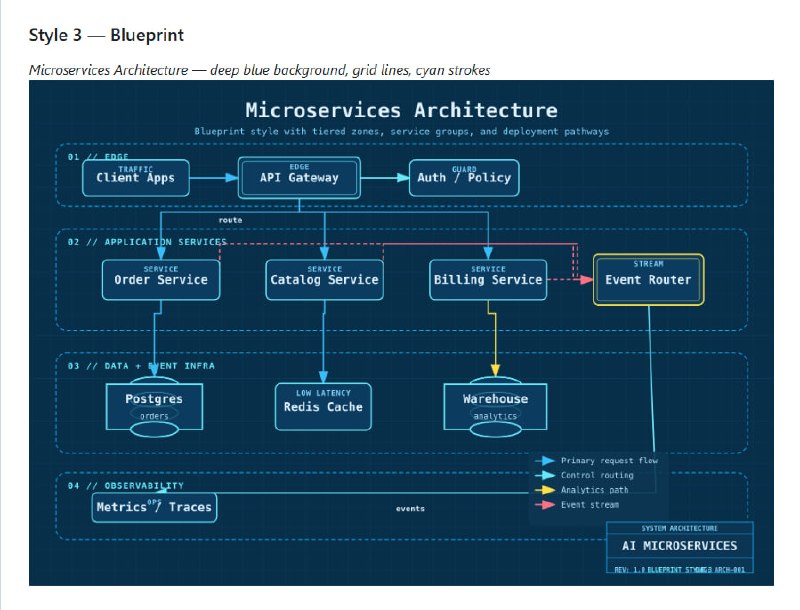
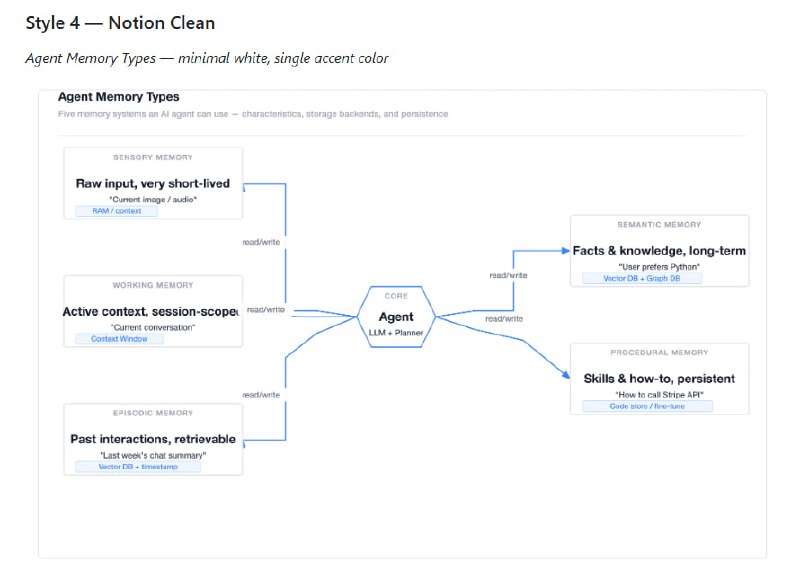
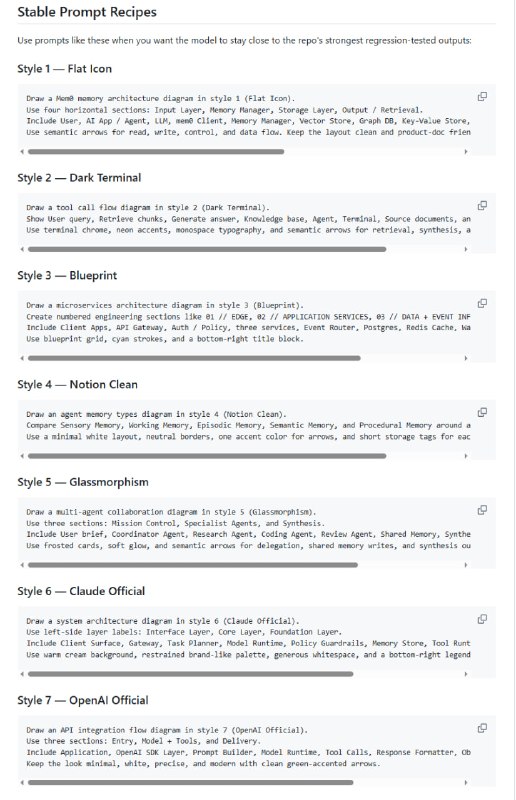
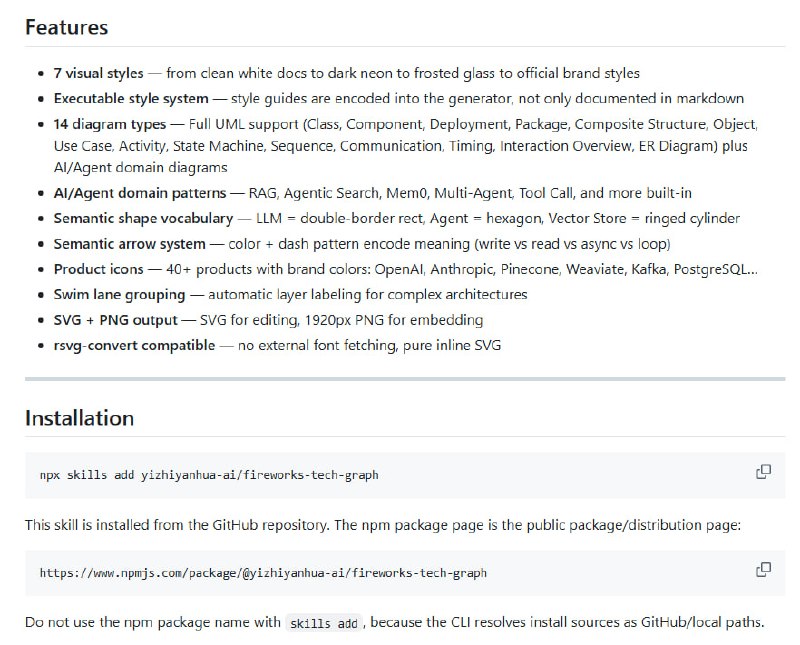
- AI 调试新思路:别硬堆算力,先建立单点真理来源 | 帖子
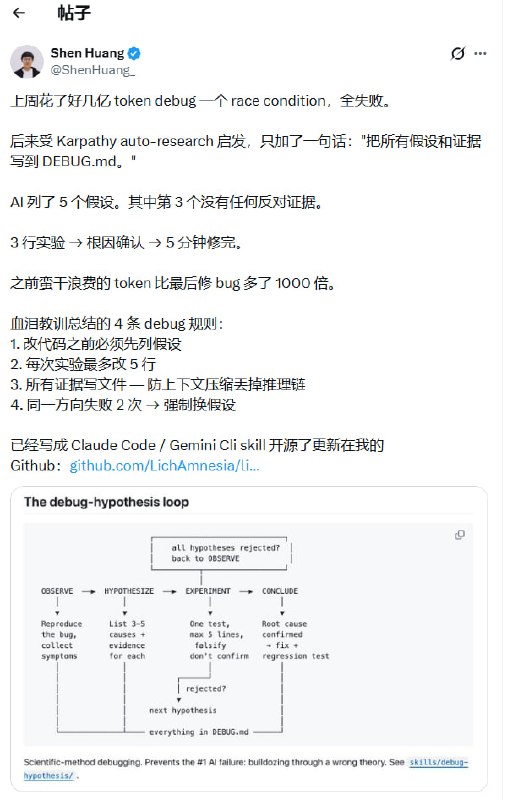
通过引入外部文档记录假设与证据,可以有效防止 AI 在长上下文压缩中丢失推理链。这种方法能将耗费数亿 Token 的无效尝试,转化为分钟级的根因定位。
有时候,解决问题的关键不在于增加计算量,而在于建立一个“外部存储层”。
最近有个很有意思的案例:有人为了调试一个竞态条件(Race Condition),消耗了数亿 Token 却颗粒无收。直到引入了一个简单的指令——要求 AI 把所有假设和证据写进 `DEBUG.md`。结果 AI 列出五个假设,发现第三个没有任何反对证据,随后仅通过三次实验就锁定了根因。
这本质上是在为 Agent 的推理过程做“持久化”。
现在的长上下文模型看似能记住一切,但实际上存在严重的上下文压缩问题。当对话轮次过多,中间的逻辑链条会像被挤压的内存一样发生信息丢失。把证据写在文件里,就是给 AI 提供了一个不可篡改的、具备强一致性的“单点真理来源”。
有网友提到,这种做法其实是在手动实现原本应该由自动化测试框架(Harness)完成的工作。好的系统应该能自动判断哪些中间推理需要持久化,而不是靠人去写规则提醒它。
这里总结了四条极具实操性的调试准则:
首先,改代码前必须先列假设。不要直接进入指令流水线,先在逻辑层完成预判。
其次,每次实验的改动量要极小。虽然有人觉得“最多改 5 行”太死板,但追求“外科手术式”的微创改动,能让因果关系变得极其清晰。
第三,强制要求将证据写入文件。这是防止推理链断裂的唯一手段。
最后,如果同一个方向失败两次,必须强制切换假设。
有观点认为,AI 给出的往往不是答案,而是一面镜子。它照出的是我们假设中的盲点。当我们在面对复杂 Bug 时,习惯性地想通过增加 Token 投入来“硬刚”,这其实是一种低效的暴力破解。
真正的智能不在于无止境的计算,而在于能够像人类一样,在证据和假设之间建立起逻辑的边界。
如果实验的路径已经走到了死胡同,是不是该考虑给 Agent 换一个全新的搜索分支了? -
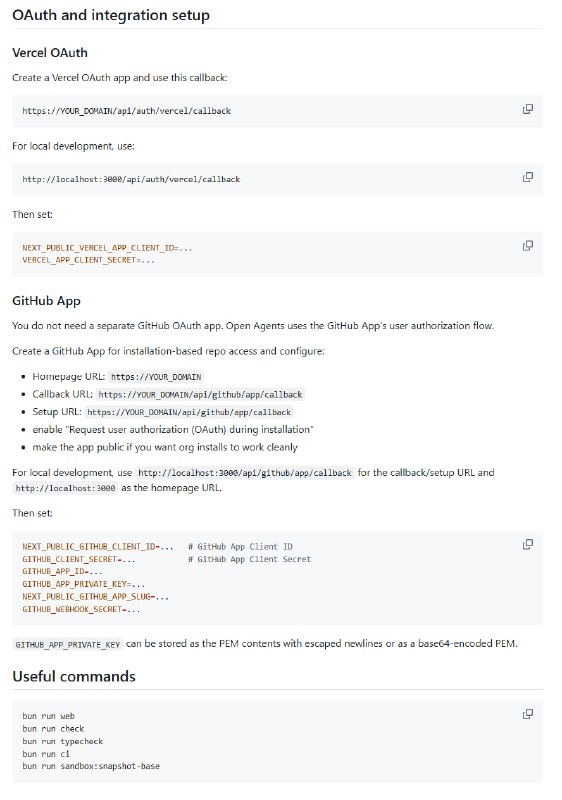
-


- Apple Silicon 上跑大语言模型,MLX 框架速度总觉得不够快,speculative decoding 方案又非无损,精度和加速两难。
dflash-mlx 带来 DFlash 无损推测解码,为 MLX 优化专属解决方案。
基于 Block Diffusion 论文,一次生成 16 个 token 验证,结合自定义 Metal 内核实现 tape-replay rollback 和长上下文 JIT SDPA,Qwen3.5-9B 最高 4.1x 加速,接受率 89%+。
主要功能:
- 无损 DFlash 推测解码,支持 Qwen3.5 系列(4B/9B/27B/35B);
- 自动 draft 模型解析,无需手动指定;
- 高精度 tape-replay rollback,保持长序列一致性;
- 长上下文优化(N>=1024),自定义 Metal 注意力内核;
- 流式输出,支持 CLI/Server 和 OpenAI 兼容客户端;
- 基准测试工具,一键对比 baseline vs DFlash 加速比。
pip install dflash-mlx 即装即用,完美适配 M 系列芯片,开发者/AI 爱好者必备。 - xchat 一个群组最多才能容纳481人?