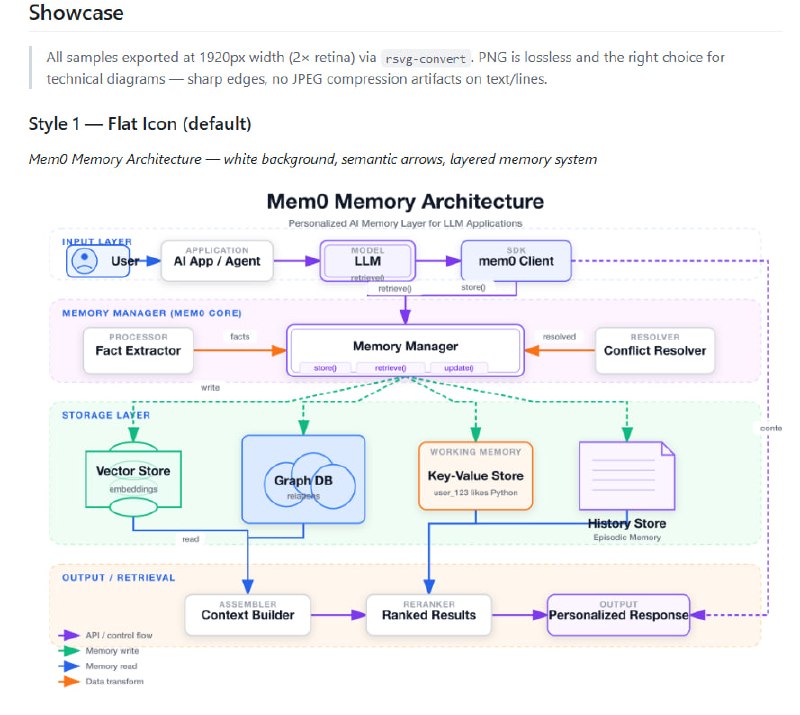
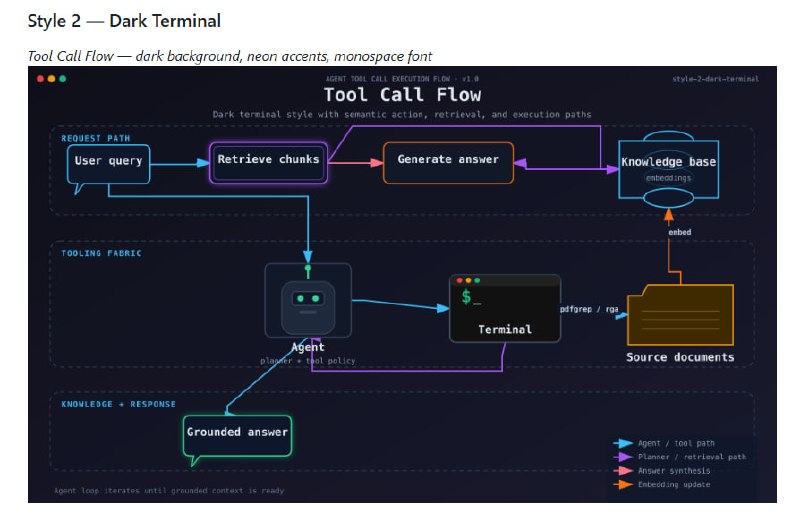
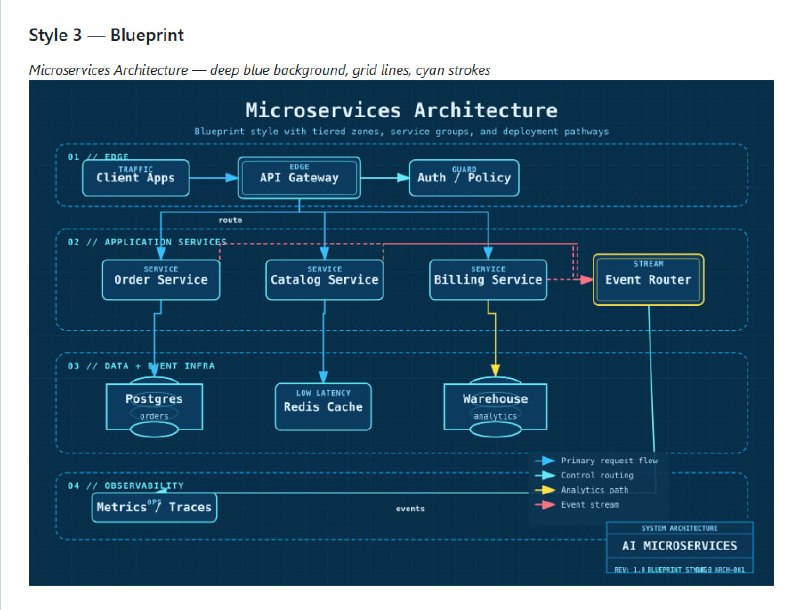
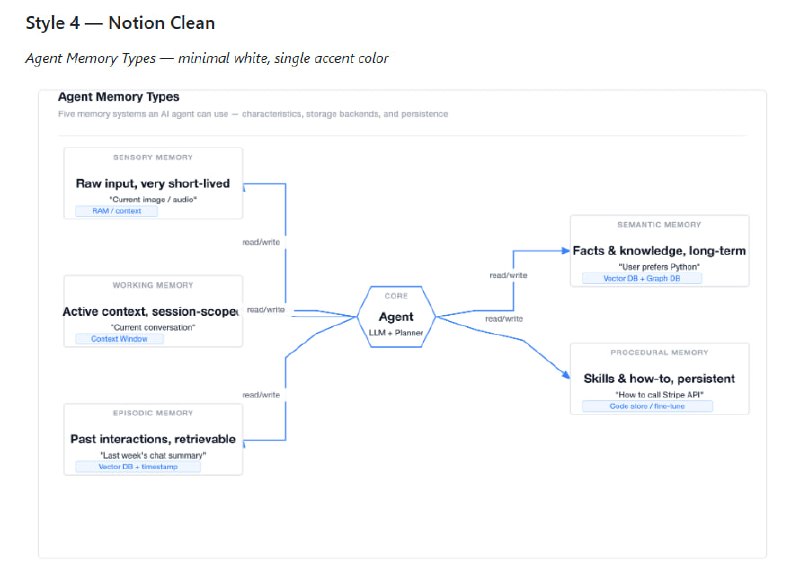
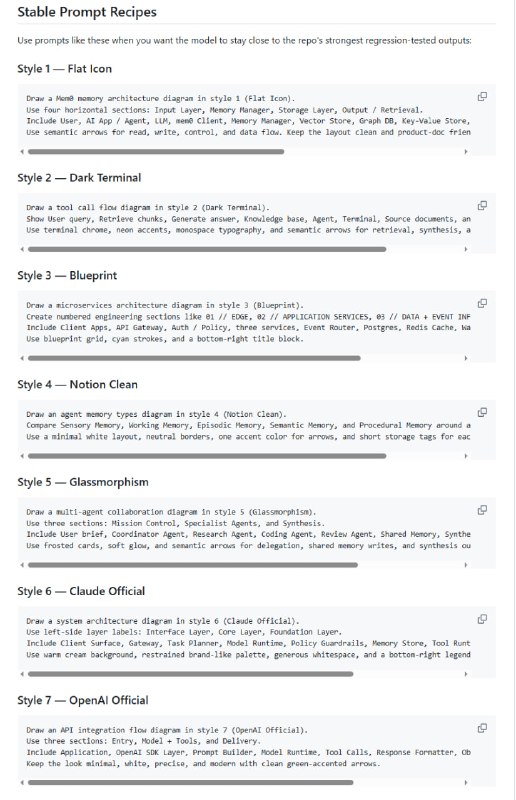
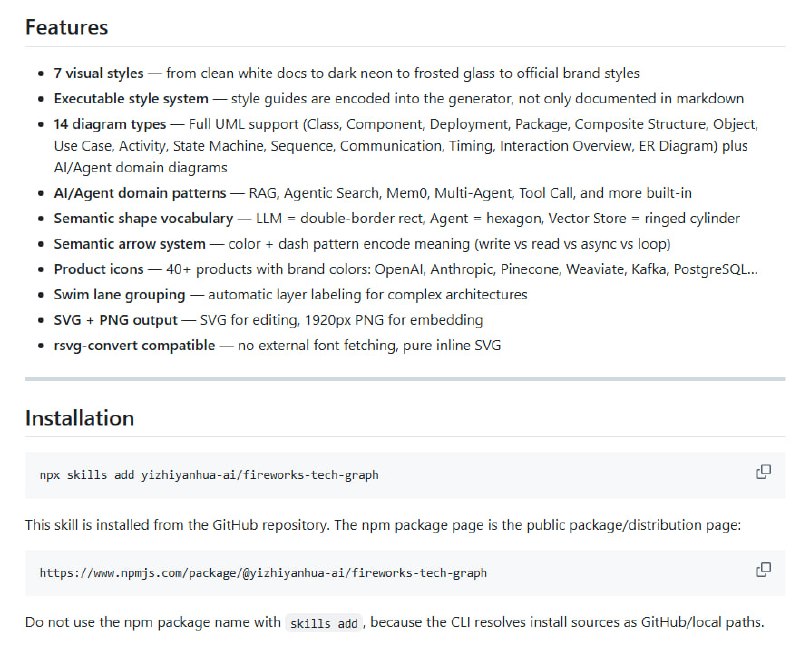
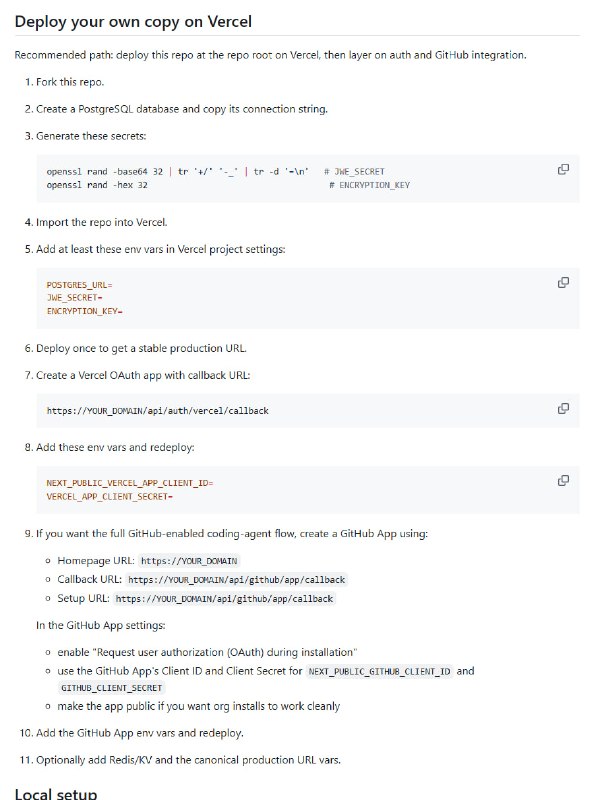
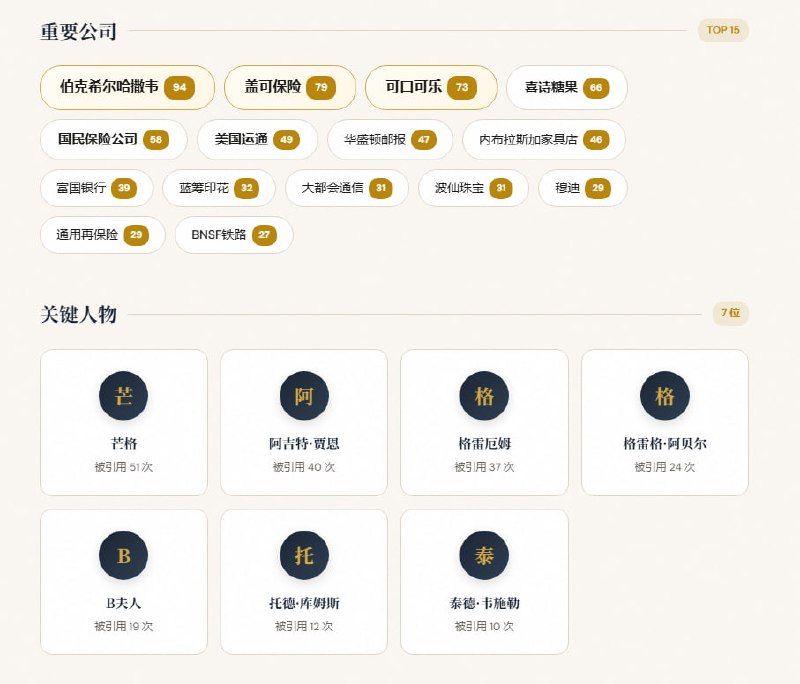
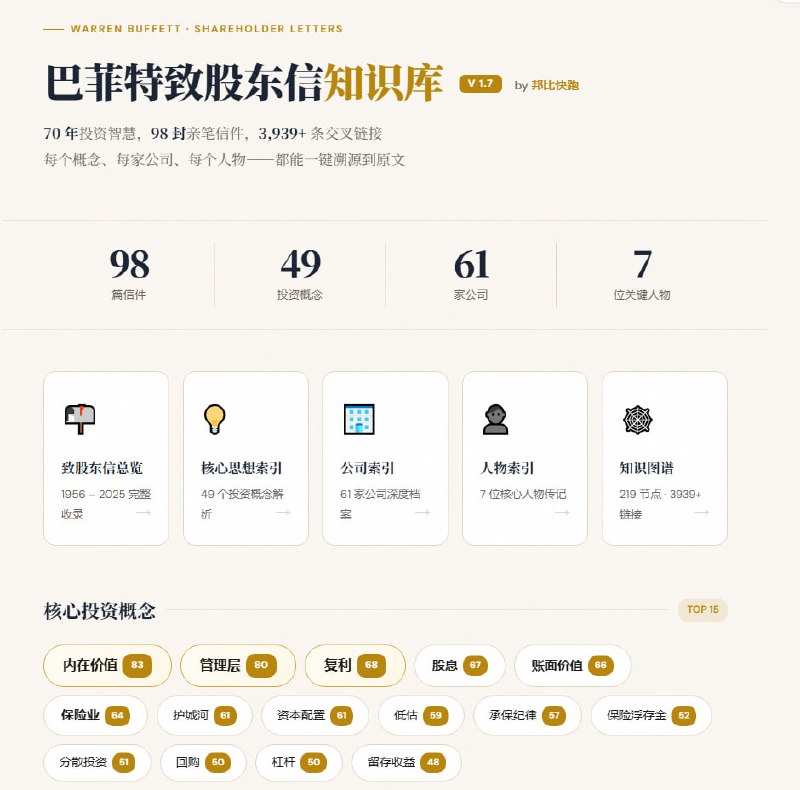
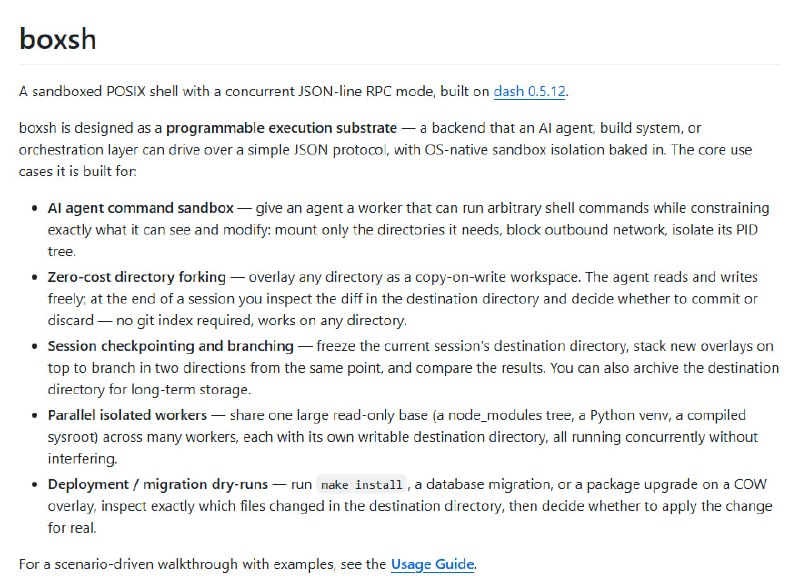
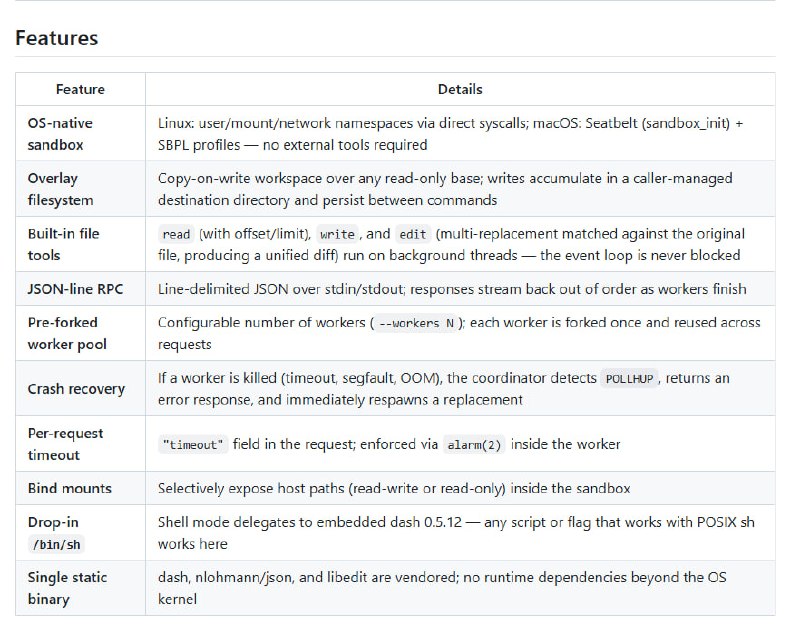
从软件工程师(SWE)转型为 AI 工程师,不是一次推倒重来的“转行”,而是一次基于工程底蕴的“进化”。
Lamhot Siagian 在其最新的 2026 职业转型指南中明确指出:AI 时代的下半场,市场不再需要只会调用 API 的 demo 制造者,而是在寻找能将不确定性的 AI 转化为确定性产品的工程专家。
以下是这份指南的核心洞察与深度行动建议:
1. 范式转移:从确定性到概率性
传统软件工程的核心是“确定性”:给定输入 A,通过逻辑 B,必然得到输出 C。但 AI 系统是概率性的,输出具有随机性和上下文敏感性。
软件工程师的真正优势不在于重新学习微积分,而在于将成熟的工程直觉引入这个混沌领域。你过去处理边缘情况、设计监控指标、优化系统可靠性的经验,正是 AI 进入生产环境最稀缺的资源。
2. 核心能力栈:五层演进模型
转型并非漫无目的的学习,而应遵循清晰的层级:
- 基础层:精进 Python 深度,理解异步处理与服务化思维。
- 原理层:不一定要能手推公式,但必须理解模型如何学习、如何评估以及在哪里会失效。
- 生成式 AI 层:掌握 Embedding、向量数据库与 RAG(检索增强生成)的架构设计。
- 工程系统层:这是 SWE 的主场。关注编排(Orchestration)、数据库集成与云端部署。
- 应用层:通过构建 Agent(智能体)系统和决策引擎,将技术转化为商业价值。
3. 避开“教程陷阱”,构建差异化作品集
不要再在简历里写“泰坦尼克号生存预测”或简单的聊天机器人 demo 了。
2026 年的雇主希望看到的是:
- 能够处理 5 亿级文档嵌入的 RAG 系统。
- 带有自我修复能力的智能体工作流。
- 包含完整评估框架(Evaluation Harness)的项目,证明你能客观衡量 AI 的好坏。
4. 简历策略:翻译你的工程资产
不要把自己定位成“AI 新手”,而要定位成“具备 AI 能力的高级工程师”。
- 将“调试经验”翻译为“模型评估与指标设计能力”。
- 将“CI/CD 经验”翻译为“持续评估与 AI 质量保证能力”。
- 将“系统设计”翻译为“端到端 AI 工作流编排”。
5. 深度思考:工程化是 AI 的最后公里
现在的 AI 行业正从“模型中心”转向“系统中心”。模型本身正在商品化,真正的护城河在于如何围绕模型构建一个鲁棒的系统。
启示:
- AI 工程师的价值,不在于模型跑通的那一刻,而在于模型出错时,你有一套系统能接住它。
- 别被数学公式吓倒,AI 的本质是数据流的重新编排。
- 优秀的 AI 工程师,是那个能在概率的荒野上,筑起确定性围墙的人。
如果你正在寻找一份实操性极强的 24 周学习计划,这份指南提供了从数学基础到 MLOps 监控的全路径覆盖。