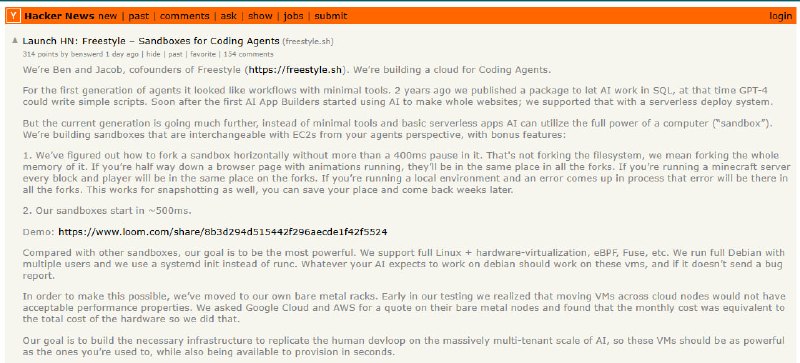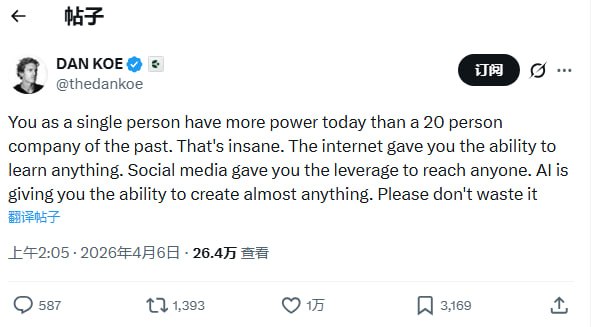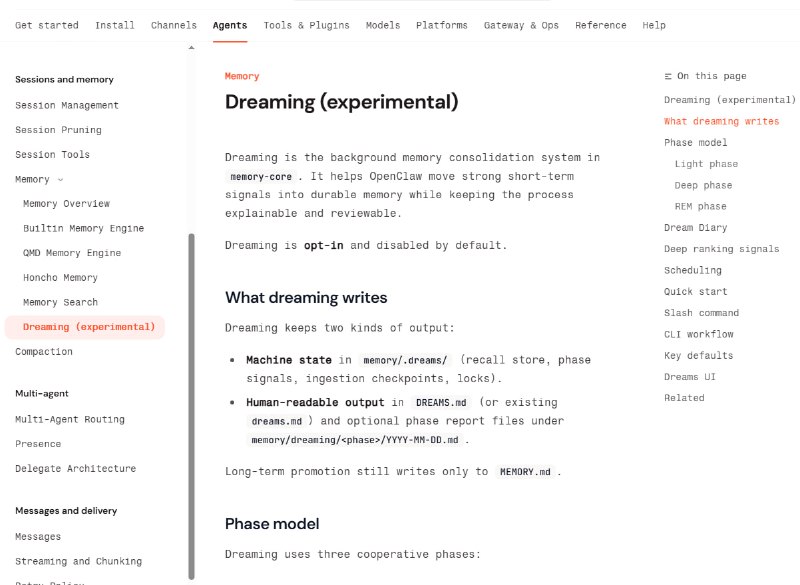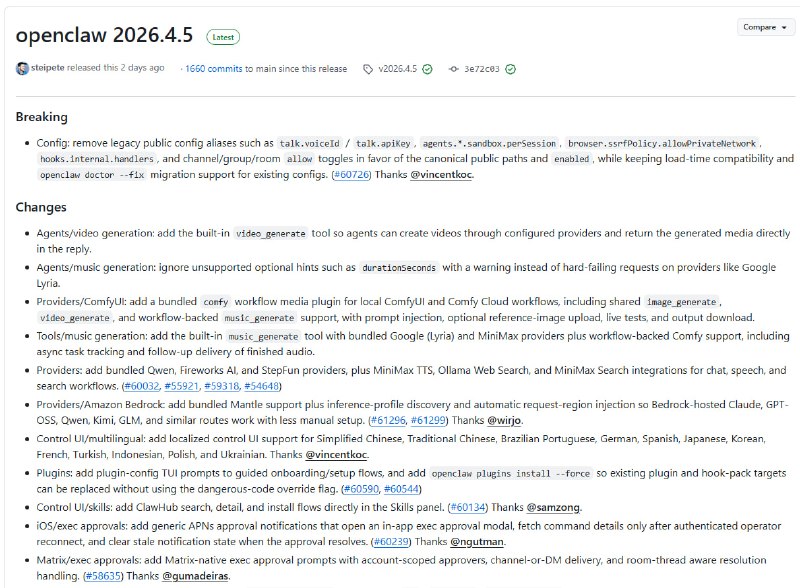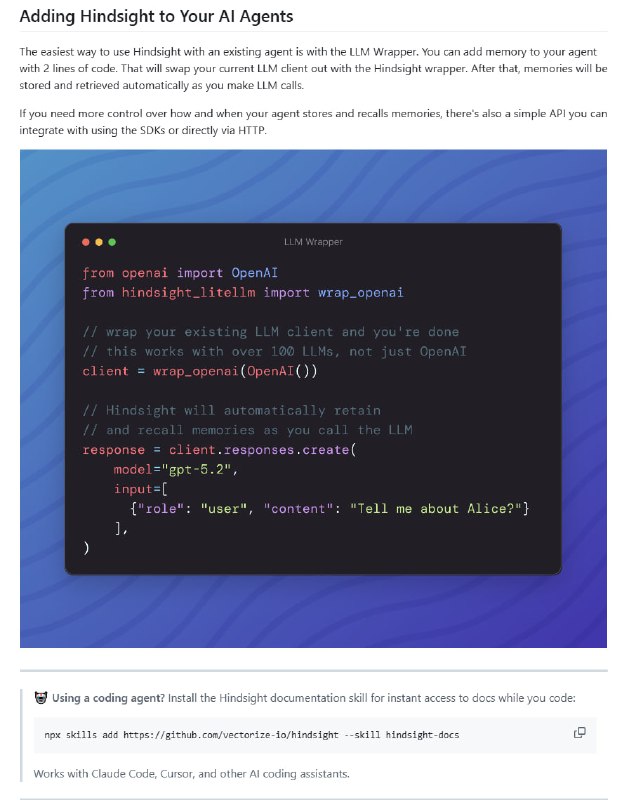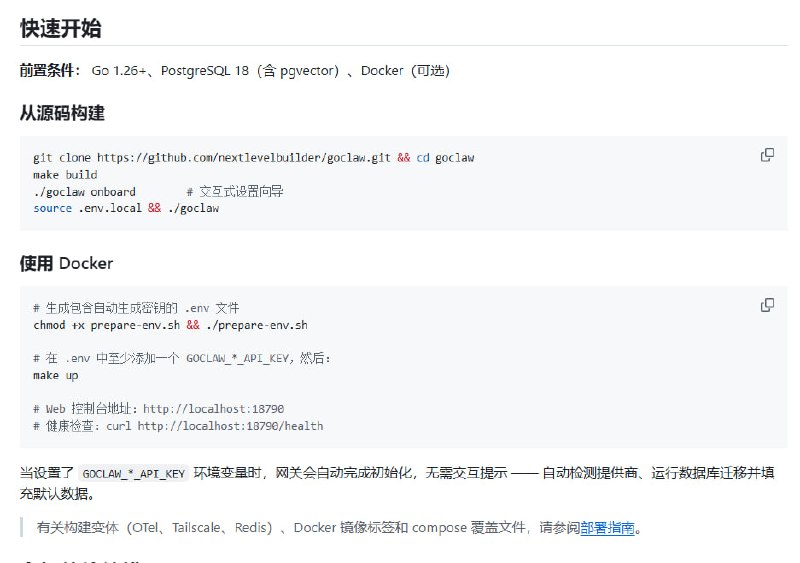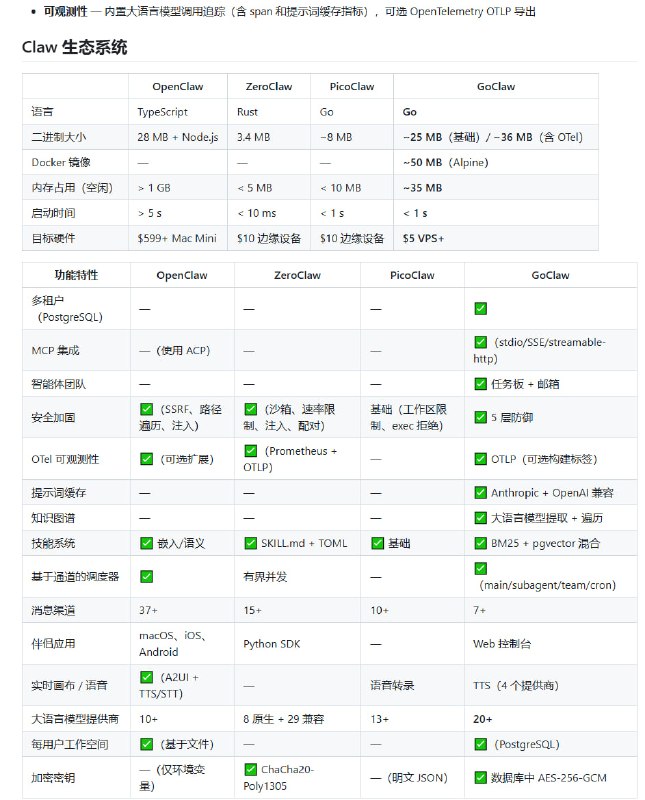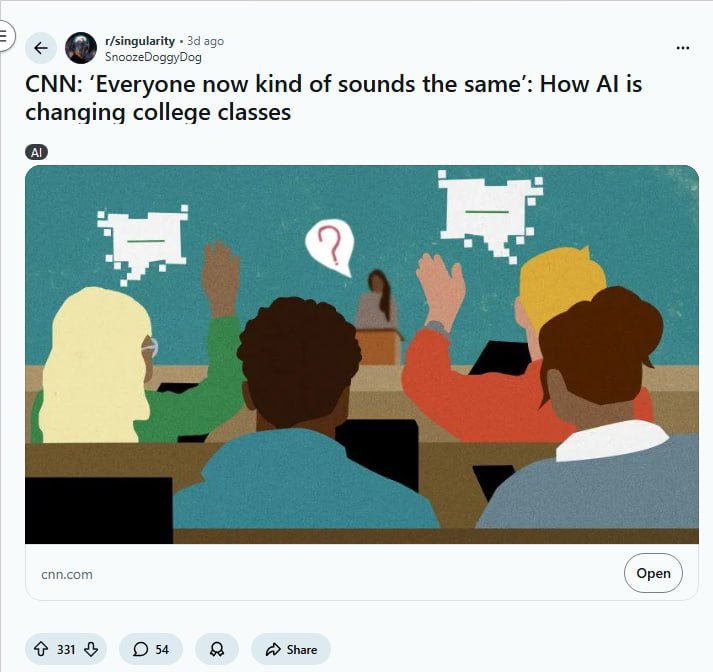
提要:AI 正在将大学写作变成一种“语言单质化”的过程。由于评分标准倾向于逻辑严密、语法无误的成品,学生们正自觉地利用 AI 抹除个人特质,追求一种标准化、甚至有些空洞的“专业感”。
现在的学术论文读起来,像是在听一个音准完美但毫无灵魂的乐器。
教授们怀念那些充满破碎句式、过度雄心勃勃的隐喻,甚至是偶尔出现的语法瑕疵。因为那些“错误”曾是学生独特视角的信号灯。而现在,大家都在追求一种“灰色声音”:结构教科书化,措辞无可挑剔,但灵魂被磨平了。
这其实是一个极其简单的激励问题。有网友提到,如果评分标准奖励的是“清晰、结构良好的散文”,那么学生没有理由拒绝 AI。正如一位学生所言,既然写得自己可能拿 B+,而用 AI 优化一下能稳拿 A,为什么不选后者?这本质上是 Goodhart's Law 的体现:当一个指标变成目标时,它就不再是一个好指标了。
有人觉得这像极了摄影术发明后的抽象派绘画——既然相机能捕捉现实,艺术家只能转向更“人化”的表达。但这种防御手段在当前的语言模型面前显得有些无力。有观点认为,只要给 AI 提供足够的个人样本,通过微调提示词,就能完美复制你的语气、甚至包括你特有的拼写习惯。
更有意思的是一种职业化的趋势。有网友分享说,在某些工作环境中,使用 AI 进行“润色”甚至是一种强制指令。大家都在利用 AI 抹除人类的缺陷,呈现出一种一致、专业但枯燥的外向声音。这种标准化的力量正在悄无声息地重塑我们的沟通协议。
这种技术进步确实像是在用高效的编译器替换原始的手写汇编。它极大地节省了时间,但也带来了一个令人不安的副作用:我们的写作肌肉正在萎缩。如果思考、搜集和整理的过程都被外包给了概率引擎,那么剩下的只是一层精美的包装。
当所有人都在追求“正确”时,真正的原创性可能正处于一种难以被捕获的低频状态。我们是否还能在算法的覆盖范围之外,找到某种无法被模拟的、属于人类的扰动?