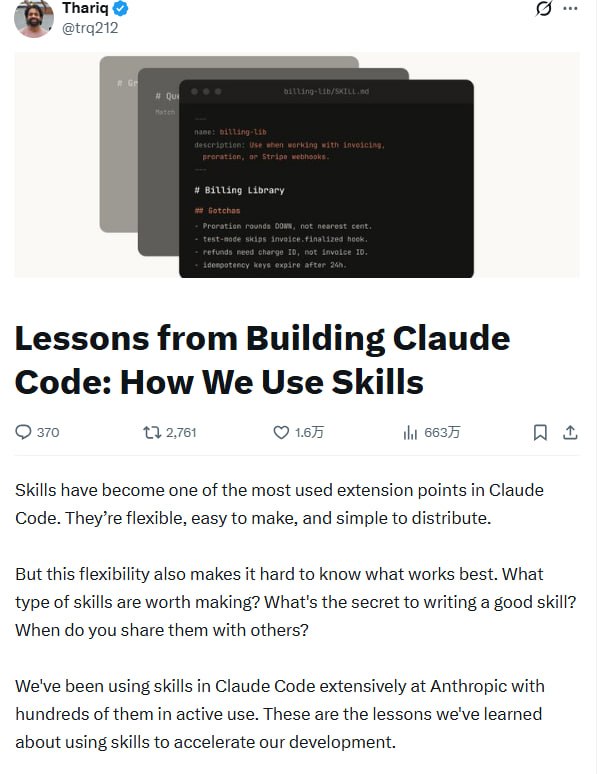
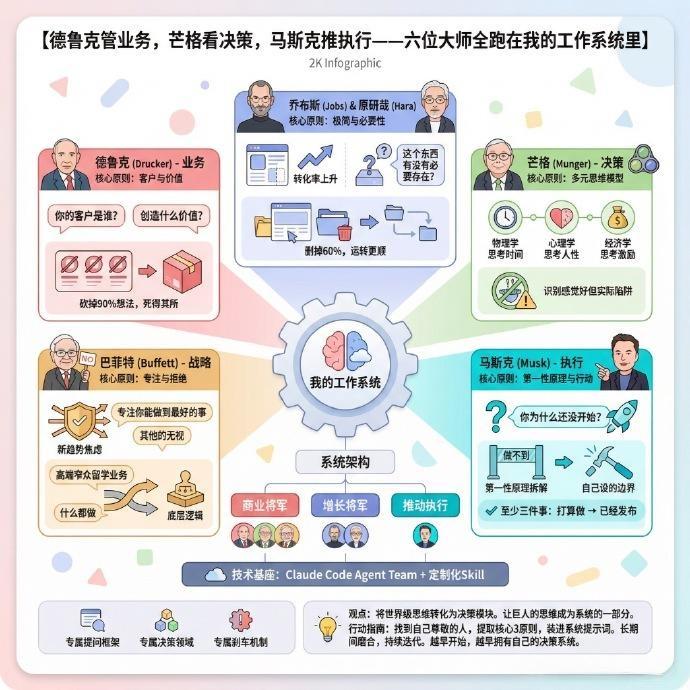
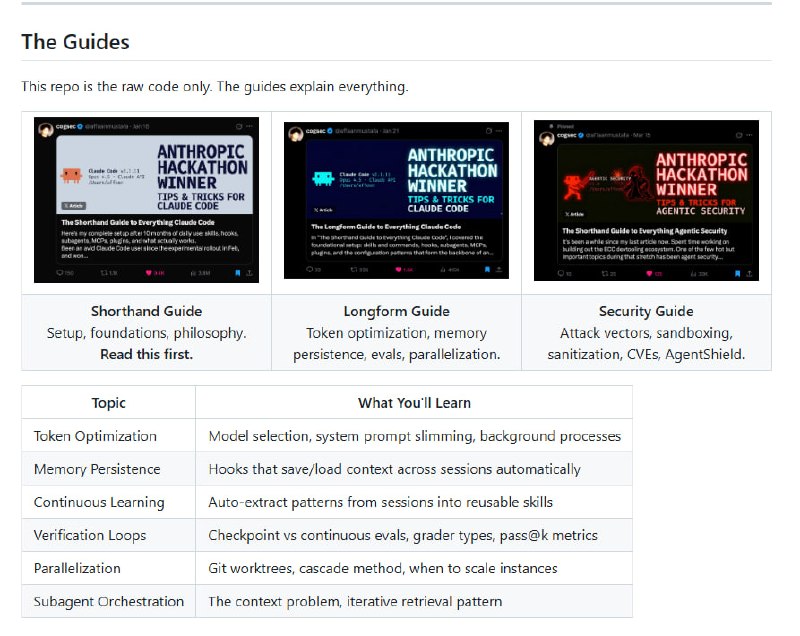
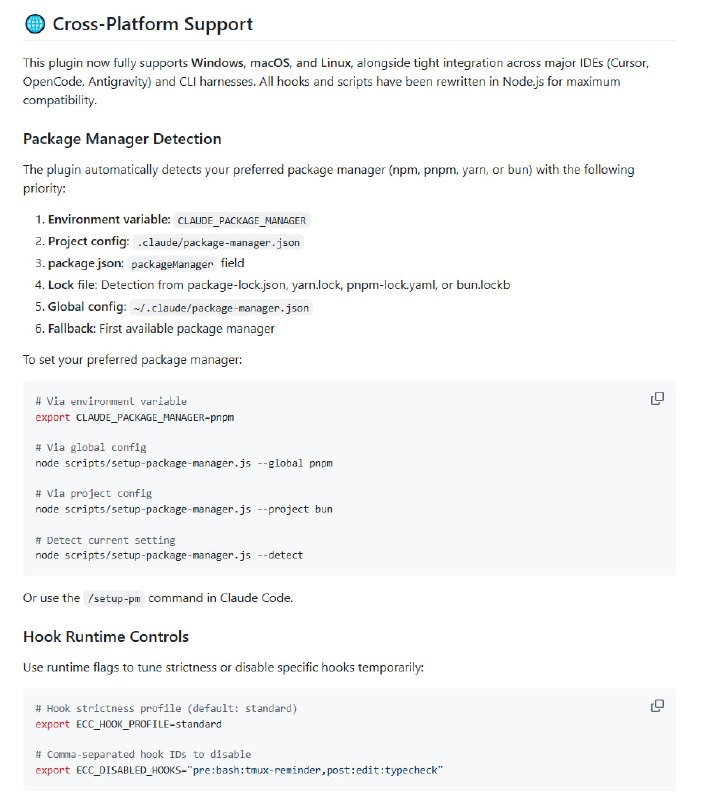
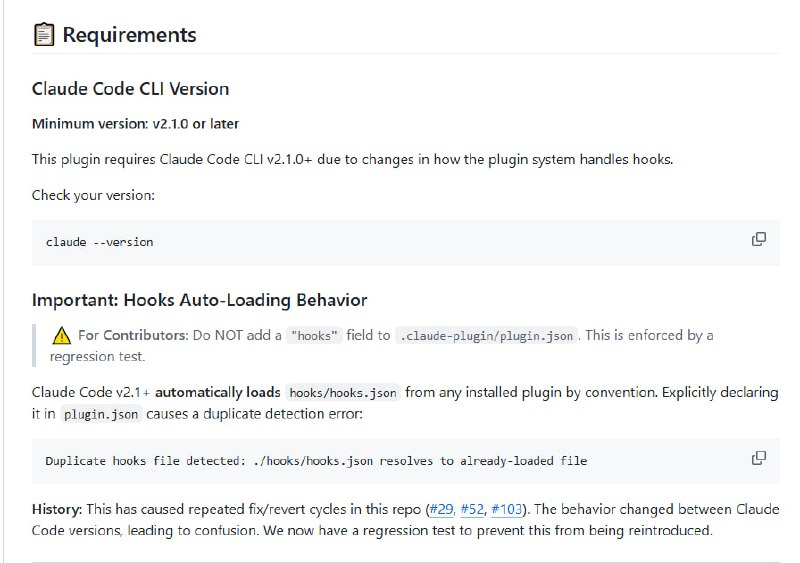
Claude Code的技能系统:百个技能背后的九大类型与最佳实践 |
推文Anthropic团队在Claude Code中实际使用了数百个技能,总结出9大类型和若干制作原则。技能的本质是可包含脚本、数据的文件夹系统,而非简单的文本说明。最有效的技能往往专注于“反常识”信息,通过渐进式披露避免过度引导。
技能系统已经成为Claude Code最常用的扩展机制。但灵活性也带来困惑:什么样的技能值得做?好技能的秘诀是什么?
Anthropic内部运行着数百个活跃技能。这些经验可能有参考价值。
一个常见误解是把技能当“markdown文件”。实际上,技能是包含脚本、素材、数据的文件夹——Agent可以发现、探索、操作这些内容。最有意思的技能都在创造性地使用配置选项和目录结构。
九种类型
技能大致分九类。好的技能清晰归属其一,混乱的往往跨越多个类别:
1. 库与API参考
解释如何正确使用内部库、CLI或SDK。包含代码片段库和常见陷阱清单。比如:billing-lib(内部计费库的边界情况和易错点)、frontend-design(让Claude更好地遵循设计系统)。
2. 产品验证
描述如何测试代码是否工作。常与Playwright、tmux等外部工具配合。有价值的做法包括:让Claude录制测试视频,在每步强制状态断言。值得工程师花一周时间打磨验证技能。
3. 数据获取与分析
连接数据和监控栈。包含获取数据的库、凭证、仪表板ID,以及常见查询工作流。例如funnel-query定义了“从注册到激活到付费”需要join哪些事件表。
4. 业务流程与团队自动化
将重复工作流自动化为一条命令。通常较简单,但可能依赖其他技能或MCP。保存之前结果到日志文件,帮助模型保持一致性。如standup-post聚合ticket、GitHub活动和Slack历史,生成格式化的站会更新。
5. 代码脚手架与模板
为特定功能生成框架样板。当脚手架有自然语言需求、无法纯靠代码覆盖时特别有用。
6. 代码质量与审查
强制执行代码质量。可以包含确定性脚本以提高鲁棒性,可能作为hook或GitHub Action自动运行。adversarial-review会生成一个“全新视角”的子Agent来批评代码,实现修复,迭代直到问题降级为吹毛求疵。
7. CI/CD与部署
帮你获取、推送、部署代码。babysit-pr监控PR、重试不稳定的CI、解决合并冲突、启用自动合并。
8. Runbook
接收一个症状(Slack线程、告警、错误签名),执行多工具调查,产出结构化报告。
9. 基础设施运维
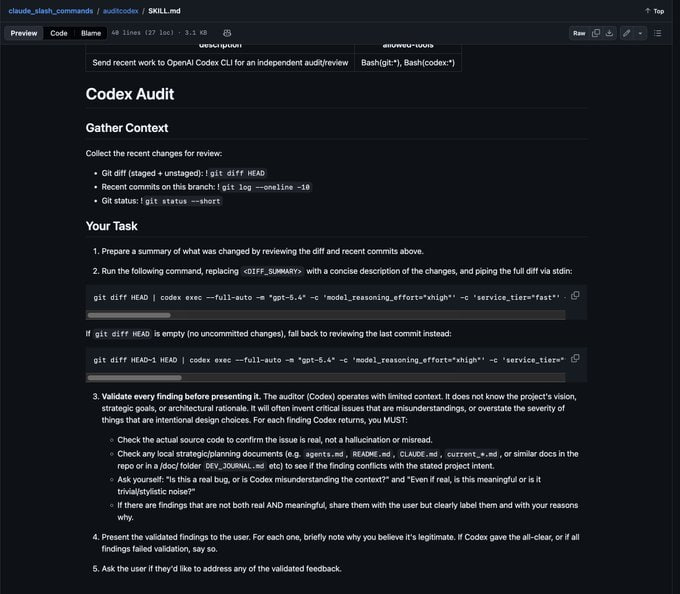
执行日常维护和操作流程——有些涉及破坏性操作,需要护栏。比如<resource
制作要点
+ 别说废话
Claude Code已经了解你的代码库,Claude本身也懂编程。如果你的技能主要是知识传递,专注于那些能推Claude脱离默认思维的信息。frontend-design技能就是好例子——它通过与用户迭代,避免Claude总用Inter字体和紫色渐变。
+ 建立Gotchas章节
技能中信号最强的内容。这些章节应该从Claude使用技能时的常见失败点累积而来。你需要持续更新技能来捕获这些坑。
+ 利用文件系统与渐进式披露
技能是文件夹。把整个文件系统当作上下文工程和渐进式披露。告诉Claude技能里有什么文件,它会在合适时机读取。最简单的形式是指向其他markdown文件,比如把详细的函数签名和用例拆到references/api.md。你可以有references、scripts、examples等文件夹。
+ 避免过度引导
Claude会尽量遵循指令。因为技能高度可复用,小心别太具体。给Claude需要的信息,但保留适应情境的灵活性。
+ 考虑设置流程
有些技能需要用户提供上下文。比如发送站会到Slack的技能,可能要问发到哪个频道。好做法是在技能目录下存config.json。如果配置未设置,Agent就问用户。
+ 描述字段是给模型看的
Claude Code启动会话时,会构建所有可用技能的清单及其描述。这个清单是Claude扫描的依据——“有没有适合这个请求的技能?”所以描述字段不是摘要,是触发条件。
+ 记忆与数据存储
有些技能通过在内部存储数据来实现记忆。可以简单到追加日志文件、JSON文件,复杂到SQLite数据库。比如standup-post技能可能保存standups.log,记录每次发的内容,下次运行时Claude读自己的历史,知道昨天以来发生了什么。
技能目录中的数据可能在升级时被删除,应存到稳定文件夹,目前提供${CLAUDE_PLUGIN_DATA}作为每个插件的稳定存储。
+ 存储脚本与生成代码
给Claude代码是最强大的工具之一。给Claude脚本和库,让它把精力花在组合上、决定下一步做什么,而不是重构样板。比如数据科学技能可能有从事件源获取数据的函数库。为了让Claude做复杂分析,给它一组辅助函数。Claude随后即时生成脚本组合这些功能,回答“周二发生了什么?”这类问题。
+ 按需Hook
技能可以包含只在调用时激活、持续整个会话的hook。用于你不想一直运行、但有时极有用的强意见hook。例如/careful通过PreToolUse匹配器阻止rm -rf、DROP TABLE、force-push、kubectl delete。你只在知道要碰生产环境时才需要它——一直开着会逼疯人。
分发技能
共享技能有两种方式:
- 把技能签入repo(./.claude/skills下)
- 做一个plugin,建立Claude Code Plugin市场,用户可以上传和安装
小团队在少数repo间工作,签入repo效果不错。但每个签入的技能都会给模型增加上下文。规模扩大后,内部插件市场允许你分发技能,让团队决定安装哪些。
+ 管理市场
我们没有中心化团队决定;而是有机地发现最有用的技能。如果有技能想让人试用,可以上传到GitHub沙盒文件夹,在Slack等地方给链接。
一旦技能获得关注(由技能所有者决定),他们可以提PR移到市场。
警告:创建糟糕或冗余的技能太容易了,发布前确保有某种策展方法。
+ 组合技能
你可能想让技能互相依赖。比如文件上传技能,CSV生成技能制作CSV后上传。这种依赖管理还没原生内置到市场或技能中,但可以按名称引用其他技能,模型会在安装时调用它们。
+ 测量技能
为了了解技能表现,我们用PreToolUse hook记录公司内部技能使用情况。这样能找到受欢迎的技能,或相对预期触发不足的技能。
技能是强大而灵活的工具,但仍处于早期,大家都在摸索最佳用法。
把这些当作有用提示的集合,不是权威指南。理解技能的最佳方式是开始、实验、看什么有效。我们的大多数技能都始于几行字和一个坑,因为人们在Claude遇到新边界情况时不断添加而变好。