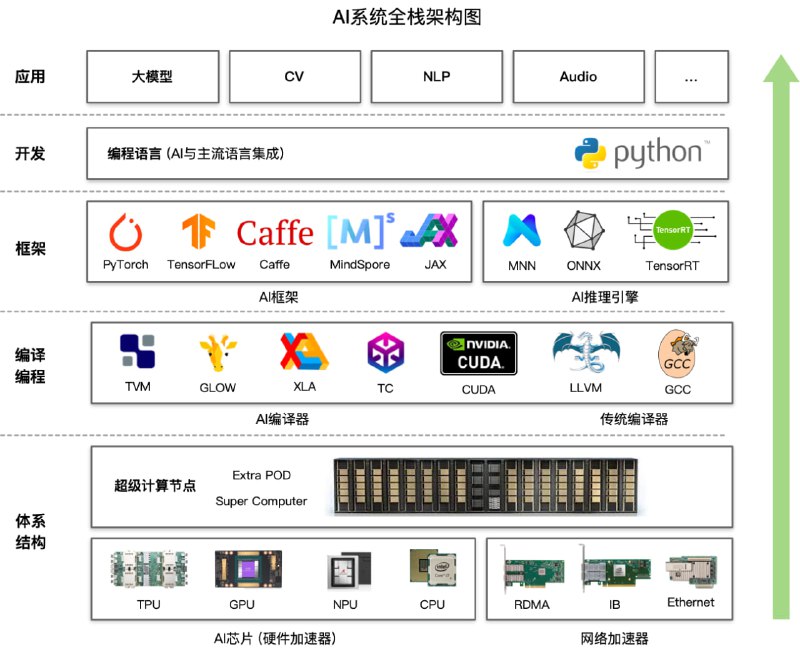
这个开源项目英文名字叫做 Deep Learning System 或者 AI System(AISys),中文名字叫做 深度学习系统 或者 AI系统。
本开源项目主要是探讨和学习人工智能、深度学习的系统设计,而整个系统是围绕着 ZOMI 在工作当中所积累、梳理、构建 AI 系统全栈的内容。
课程主要包括以下五大模块:
第一部分,AI基础知识和AI系统的全栈概述的AI系统概述,以及深度学习系统的系统性设计和方法论,主要是整体了解AI训练和推理全栈的体系结构内容。
第二部分,硬核篇介绍AI芯片,这里就很硬核了,从芯片基础到AI芯片的范围都会涉及,芯片设计需要考虑上面AI框架的前端、后端编译,而不是停留在天天喊着吊打英伟达,被现实打趴。
第三部分,进阶篇介绍AI编译器原理,将站在系统设计的角度,思考在设计现代机器学习系统中需要考虑的编译器问题,特别是中间表达乃至后端优化。
第四部分,实际应用推理系统,讲了太多原理身体太虚容易消化不良,还是得回归到业务本质,让行业、企业能够真正应用起来,而推理系统涉及一些核心算法和注意的事情也分享下。
第五部分,介绍AI框架核心技术,首先介绍任何一个AI框架都离不开的自动微分,通过自动微分功能后就会产生表示神经网络的图和算子,然后介绍AI框架前端的优化,还有最近很火的大模型分布式训练在AI框架中的关键技术。
第六部分,汇总篇介绍大模型,大模型是全栈的性能优化,通过最小的每一块AI芯片组成的AI集群,编译器使能到上层的AI框架,中间需要大量的集群并行、集群通信等算法在软硬件的支持。