BrainMagick:通过分析脑电活动来推断一个人正在听什么,并将其转化为语音。
由Facebook Research 研究的项目,该研究使用非侵入性的电子脑图(EEG)和磁脑图(MEG)技术来解码大脑波并将其转化为语音。这一研究成果已经发表在2023年的 Nature 上,而且项目是开源的。
该模型通过预测与相应大脑活动模式匹配的语音音频的表示来解码语音。该研究在准确性方面取得了显著的改进,特别是在使用MEG记录时,准确性高达73%。
这一成果对于那些因神经系统疾病而失去说话能力的人来说是一个巨大的希望,因为它为恢复他们的沟通能力提供了一条新途径。
工作原理:
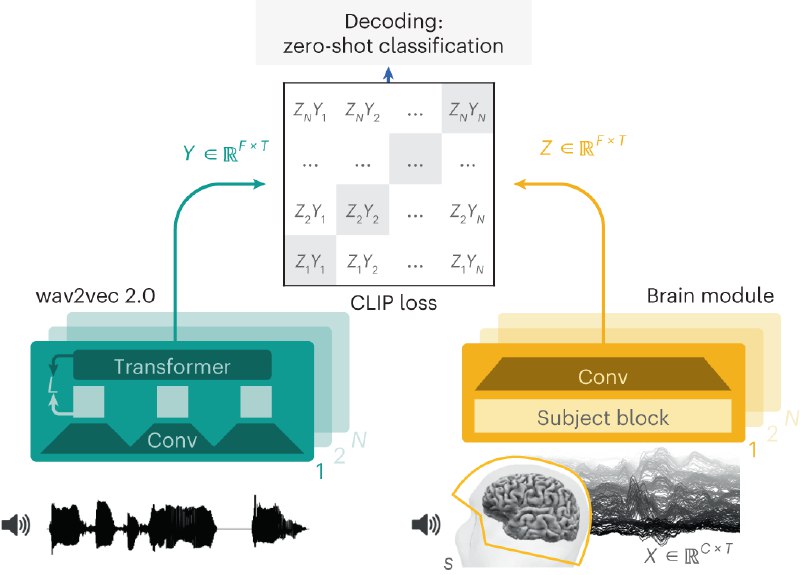
1、数据输入与表示: BrainMagick 使用两种类型的数据输入:一是脑电活动数据(EEG或MEG),二是与之相关的音频数据。这些音频数据通过Wav2Vec 2.0模型转换成特定的表示形式。
2、对比损失: 项目使用对比损失(Contrastive Loss)作为训练的目标函数。简单来说,对比损失试图最小化正样本(即与当前脑电活动匹配的音频)与脑电活动表示之间的距离,同时最大化负样本(即与当前脑电活动不匹配的音频)与脑电活动表示之间的距离。
3、多数据集验证: 该方法在4个不同的数据集上进行了验证,包括2个MEG数据集和2个EEG数据集。这些数据集涵盖了175名志愿者和超过160小时的脑电活动记录。
4、性能评估: 在Gwilliams数据集上,该方法达到了41%的top-1准确率。这意味着该模型能够在超过1300个未见过的候选句子中,准确地识别出受试者当前正在听哪个句子,以及该句子中的哪个单词。
在MEG记录的3秒语音片段中,模型能够从超过1500个可能的片段中识别出匹配的片段,准确率高达73%。
技术细节与实现:
依赖与环境: 项目推荐使用NVIDIA GPU进行训练,并且具体列出了所需的软件包和环境设置步骤。
数据预处理与缓存: 项目代码中包含了数据预处理的步骤,包括潜在的下采样和低/高通滤波等。为了提高效率,最耗时的计算被缓存起来。
配置与实验管理: 项目使用Hydra进行配置管理,并使用Dora进行实验的启动和管理。
Nature报道 |
项目地址 |
paper
Nature
Decoding speech perception from non-invasive brain recordings
Nature Machine Intelligence - Deep learning can help develop non-invasive technology for decoding speech from brain activity, which could improve the lives of patients with brain injuries....