黑洞资源笔记
-
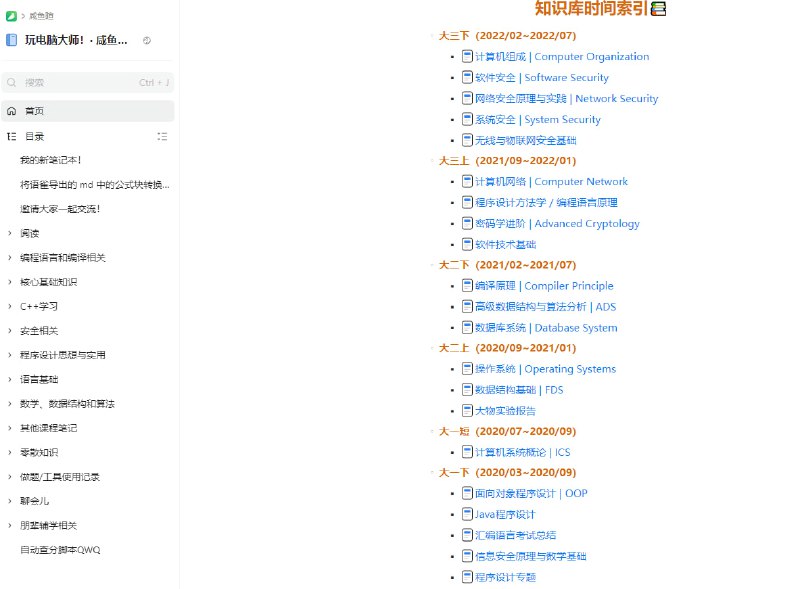
- FMEngine 是一个用于训练非常大的基础模型的实用程序库。目前,FMEngine 支持两个模型系列:GPT-NeoX和LLama。
fmengine 的目标是提供一个:
●用于训练基础模型的人体工程学界面。它对于初学者来说足够容易使用,而且还为高级用户提供足够的灵活性来定制他们的培训。
●内置高效优化。FMEngine 配备Flash Attention和各种融合操作来加速训练。
●使用预构建的 docker 和奇异性/apptainer 容器进行HPC 友好安装。FMEngine主要是在Slurm集群上设计和测试的,提供了在 Slurm 集群上运行 FMEngine 的入门脚本。
●与现有框架和工具兼容,特别是HuggingFace。由于 FMEngine 是使用DeepSpeed构建的,因此它也兼容所有 DeepSpeed 功能。 - Runtime Speech Recognizer:适用于虚幻引擎(Unreal Engine)的跨平台、实时、离线语音识别插件,基于OpenAI 的 Whisper 语音识别引擎。
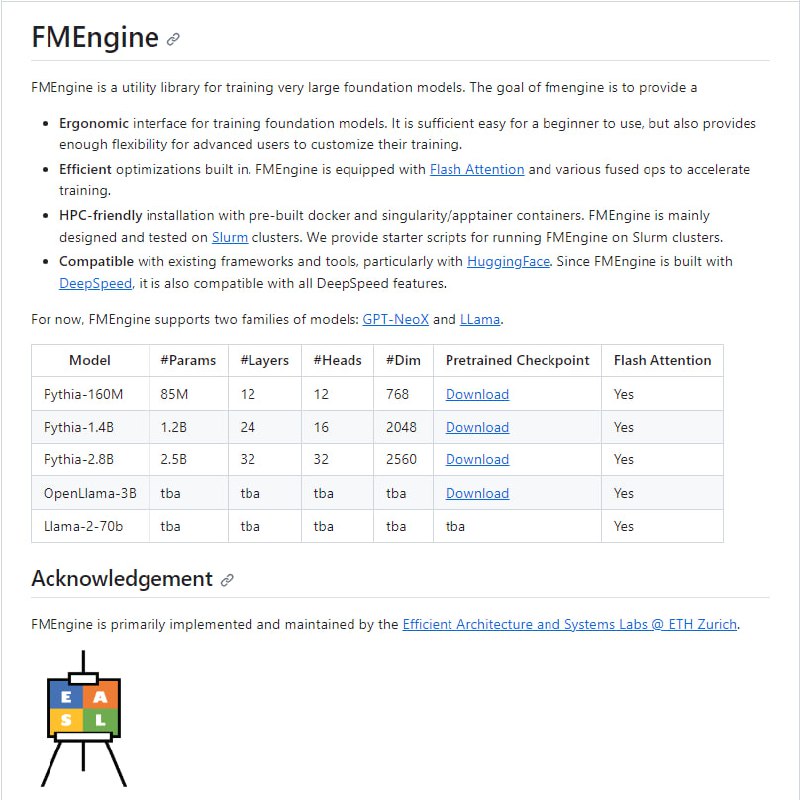
主要特征
识别速度快
提供纯英文和多语言模型,多语言支持100种语言
提供不同型号大小(从 75 Mb 到 2.9 Gb)
在编辑器中自动下载语言模型
任选将已识别的语音翻译成英语
可定制的属性
在设置中轻松选择模型尺寸和语言
没有静态库或外部依赖项
跨平台兼容性 - Prediction-powered inference (PPI) 是使用机器学习进行统计严谨的科学发现的框架。

给定少量带有黄金标准标签的数据和大量未标记的数据,预测驱动的推理可以估计总体参数,例如平均结果、中值结果、线性和逻辑回归系数。
预测驱动的推理既可用于对这些量进行更好的点估计,也可用于更严格的置信区间和更强大的 p 值。这些方法既适用于独立同分布设置,也适用于某些类别的分布变化。 - Crumb:一种高级、函数式、解释性、动态类型、通用的编程语言,具有简洁的语法和详细的标准库
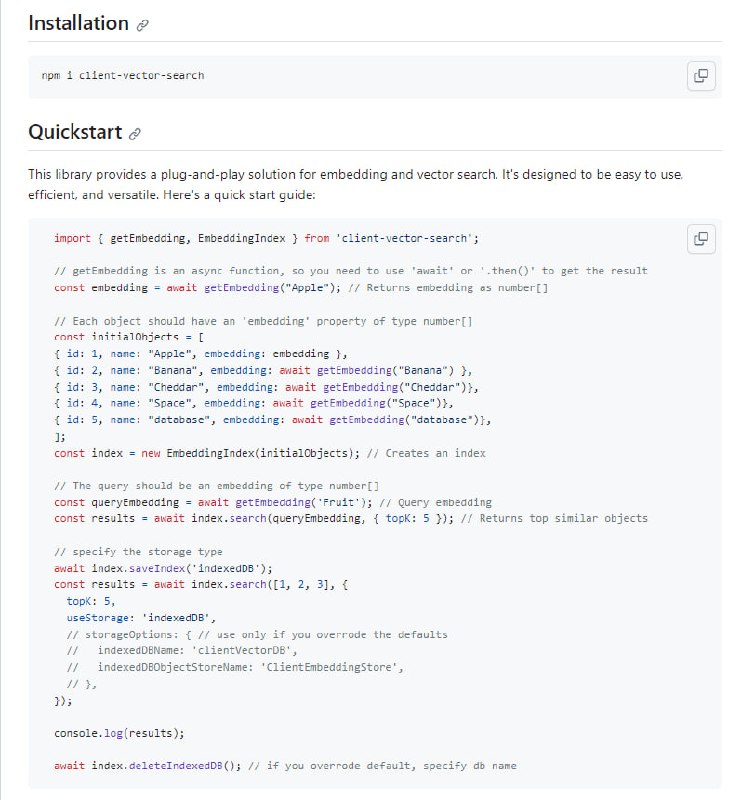
- client-vector-search:嵌入式、可搜索和可缓存的客户端向量搜索库,目标是构建一个超级简单、快速的向量搜索,可处理数百到数千个向量。约 1k 个向量涵盖了 99% 的用例。适用于浏览器和服务器端。
-
- 智能自动化二进制漏洞分析工具
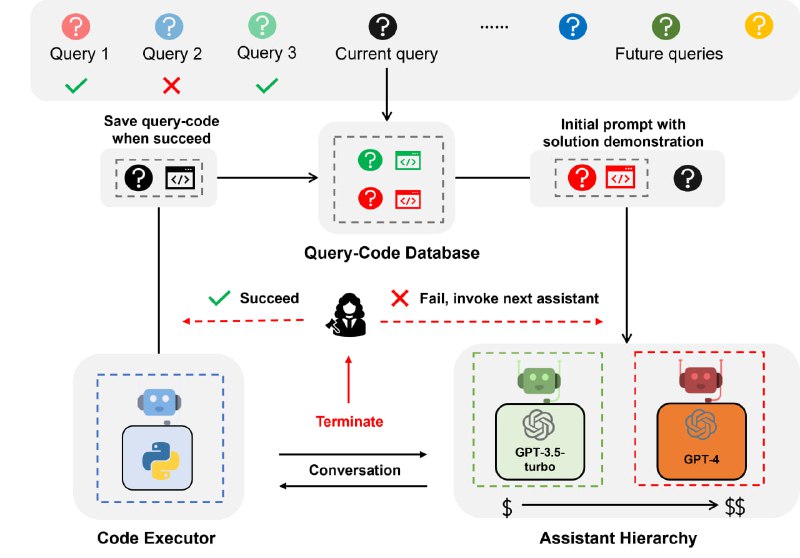
Callisto是一款智能自动化二进制漏洞分析工具。其目的是自动反编译提供的二进制文件并迭代伪代码输出,查找该伪 C 代码中潜在的安全漏洞。Ghidra 的无头反编译器驱动二进制反编译和分析部分。伪代码分析最初由Semgrep SAST 工具执行,然后传输到GPT-3.5-Turbo,以验证 Semgrep 的发现以及潜在的其他漏洞识别。
该工具的预期目的是协助二进制分析和零日漏洞发现。输出旨在帮助研究人员识别二进制文件中潜在的感兴趣区域或易受攻击的组件,然后可以进行动态测试以进行验证和利用。它当然不会捕获所有内容,但使用 Semgrep 对 GPT-3.5 进行双重验证旨在减少误报并允许对程序进行更深入的分析。
对于那些希望将该工具用作快速无头反编译器的人来说,output.c创建的文件将包含从二进制文件中提取的所有伪代码。这可以插入您自己的 SAST 工具或手动分析。
Callisto | #工具 -
-
-


- Zig是一个命令式、通用、静态类型、编译的系统编程语言。 以“强健性、最佳性以及可维护性”为核心理念。 它支持编译时泛型与反射、交叉编译以及手动存储器管理。 目标为改进C语言,同时参考从Rust 和其他语言。Zig 有许多低端程序设计的功能,例如紧致结构、任意大小的整数以及多指针类型。

《学习 Zig》系列教程最初由 Karl Seguin 编写,该教程行文流畅,讲述的脉络由浅入深,深入浅出,是入门 Zig 非常不错的选择。因此,Zig 中文社区将其翻译成中文,便于在中文用户内阅读与传播。 -
- 谷歌将于 2024 年初取消 Gmail 的基本 HTML 视图,之后,Gmail 会自动更改为标准视图。| 相关链接
-
- Open X-Embodiment:迄今为止最大的开源机器人数据集

包含100多万条来自22个不同机器人平台的实机轨迹数据,汇集了全球34个机器人研究实验室的60个现有数据集。
基于该数据集训练了两个模型:1) RT-1,一个高效的基于Transformer的机器人控制架构;2) RT-2,一个大规模的视觉语言模型,通过自然语言Token输出机器人动作。
RT-1-X是在机器人数据混合上训练的RT-1模型。RT-2-X是在机器人数据混合上训练的RT-2模型。
结果显示,RT-1-X在分布内技能上的表现优于只在单个数据集上训练的原始方法;RT-2-X在新技能上的表现较RT-2提升了3倍,展现了更好的空间理解能力。
本项目由来自21个机构的研究人员合作完成,为探索通用的机器人策略奠定了基础,以实现机器人经验的有效迁移。 -
- Colab最新更新概览 | link
借助Colaboratory(简称Colab),可在浏览器中编写和执行Python代码,并且无需任何配置;,免费使用GPU; 轻松共享
- Colab新增了从Google表格智能粘贴数据的功能,可以自动生成代码将粘贴的数据转换为pd.DataFrame,省去了传统上要进行的额外步骤。
- Colab还可以从Pandas DataFrame自动生成图表,执行包含DataFrame的代码单元格后,会出现一个自动绘制图表的按钮。
- Colab Notebook现支持将代码单元格折叠并分组,可以给相关的代码单元格添加小标题,这能让Notebook更整洁有序。
- 新的文本编辑功能允许选择一个代码单元格然后直接编辑文本,无需转换为Markdown单元格。
- Colab实验室新增了一些功能让Notebook的协作更容易,如评论和任务列表。
- Colab Notebook编辑器现在支持语法高亮显示,可以选择不同的配色方案。编辑器还可以实时预览LaTeX数学表达式。
- Colab增加了新的Notebook设置,可以设置单元格间距、代码字体等使界面更符合个人喜好。
- Colab optimize运行时选项可以根据硬件情况自动选择运行时,提高Notebook的性能。
- Colab的Stable Diffusion支持扩展到更多用户,可以通过简单的代码进行图像生成。 -