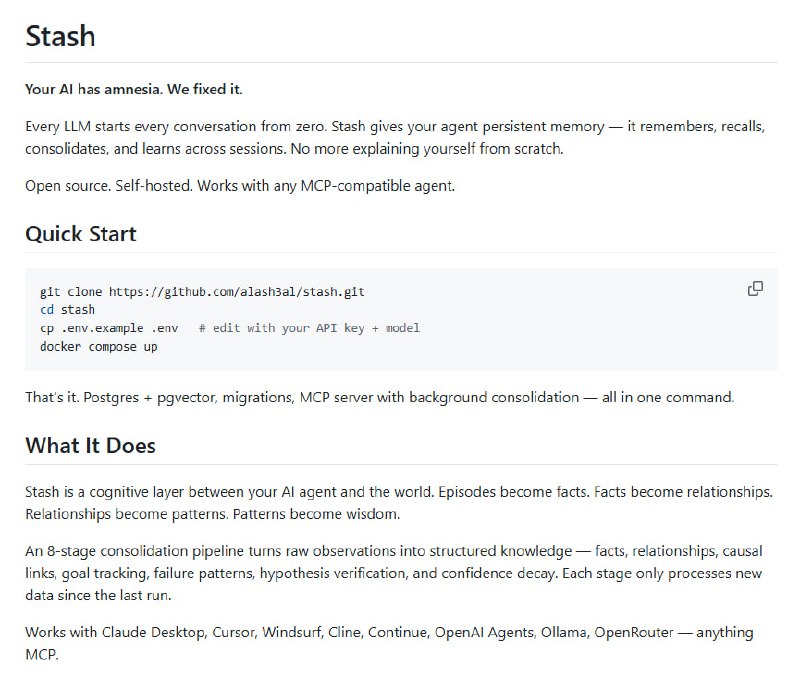
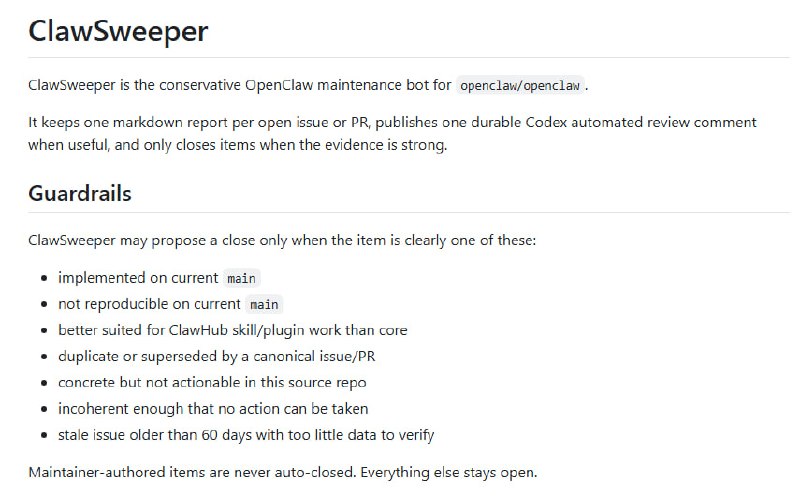
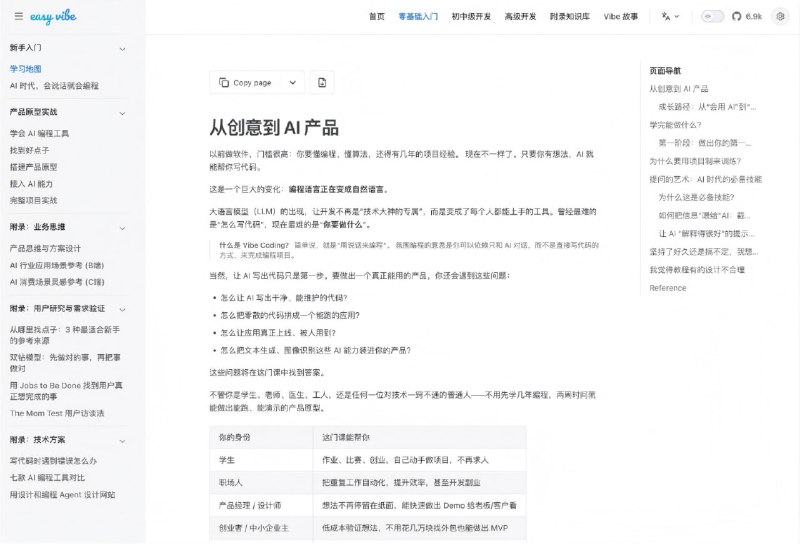
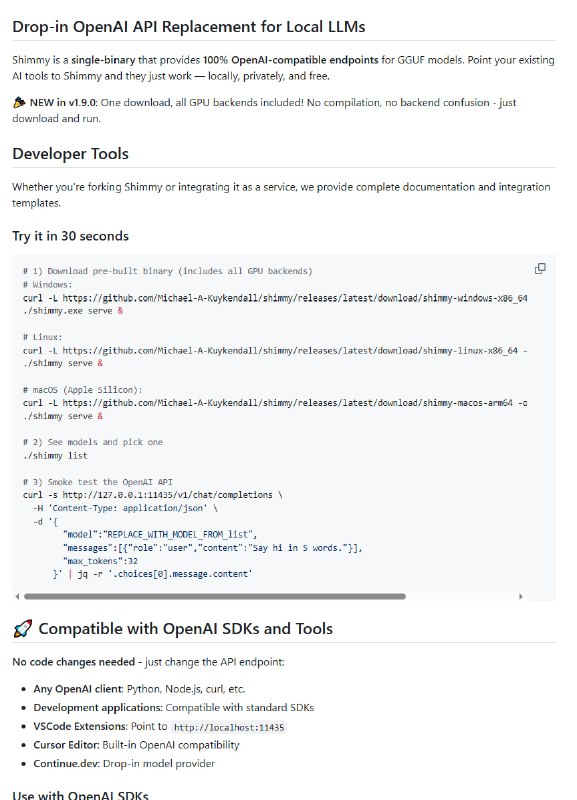
AI 正在将“语言的流畅度”与“真实的理解”剥离。如果教育的目标仅仅是产出完美的文本,我们正在面临一场大规模的认知替代,而非真正的学习。
当 LLM 能够瞬间生成逻辑自洽、文采斐然的论文时,一个危险的错觉产生了:语言的熟练运用等同于思想的深度。
这本质上是一种“认知外包”。如果一个人只是在复述、在搬运 AI 生成的结论,他其实并没有真正拥有这些知识,他只是充当了一个数据传输层。这就像是在看别人打篮球,看再多视频也无法产生肌肉记忆。
有观点认为,真正的理解来自于与现实的摩擦。就像 John Stuart Mill 所言,仅仅记住立场是不够的,你必须在被质疑的过程中,通过积极的辩护来完善自己的认知。AI 提供的不是这种摩擦,而是一种廉价的、无痛的模拟。
这种模拟正在让教育变得“空心化”。如果教学只关注结果的交付,学生就会习惯于通过“询问正确的问题”来获得“正确的答案”。但这并非在思考,而是在运行预设的脚本。
有网友提到,记忆力其实是被低估的。记忆不是为了死记硬背,而是为了增加大脑的“构建块”数量。没有这些底层逻辑的内化,所谓的创造力不过是无米之炊。
面对这种趋势,我们需要的不是禁止 AI,而是增加“认知摩擦”。
与其写一份完美的报告,不如进行一场面对面的口头辩论;与其追求产出的效率,不如强迫自己去处理那些模糊、不确定且难以被模型总结的现实问题。
教育的终点不应是产出高质量的文本,而是培养出能够对真理负责、能够独立判断的人。