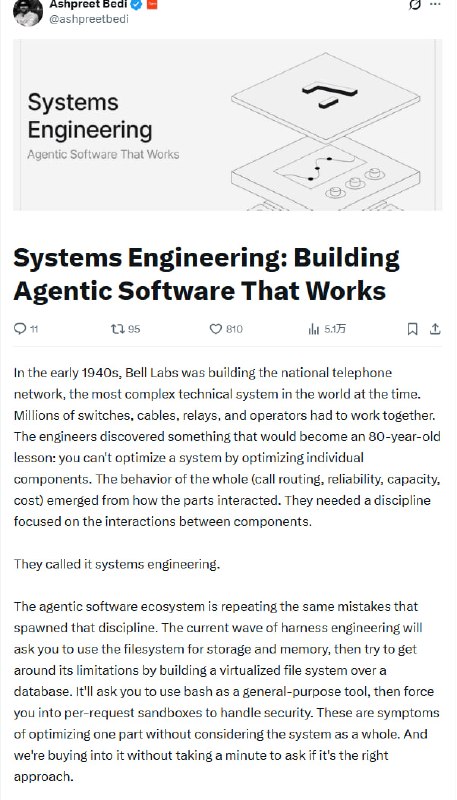
智能体软件不是提示词堆叠:一场面向 Agent 的系统工程实践 |
推文构建智能体软件(Agentic Software)不应仅仅是“提示词工程”的堆叠,而是一场严谨的系统工程实践。Ashpreet Bedi 通过复盘贝尔实验室构建电话网络的历史教训,指出当前 AI 开发中“过度优化局部、忽视系统整体”的误区。
+ 真正的智能体软件是“业务逻辑被 Agent 替换”的常规软件,它必须在五个核心层面上实现协同:
1. 智能体工程(Agent Engineering)
这是系统的“大脑”。除了模型选择,更关键的是定义确定性的执行流、工具配置和上下文管理。智能体的行为在可预测时应保持确定,在不可预测时应保持可观测。
2. 数据工程(Data Engineering)
上下文即数据。记忆、存储和知识库必须遵循成熟的数据工程原则:设计良好的 Schema、结构化查询以及高效的读写流水线。Agent 的能力上限取决于它获取数据的质量,而非模型参数。
3. 安全工程(Security Engineering)
安全必须由系统强制执行,而非靠提示词约束。“只读权限”应该是数据库连接层面的配置,而不是告诉 Agent “请不要修改数据”。必须通过 JWT 验证、RBAC(基于角色的访问控制)和请求隔离,防止数据越权。
4. 接口工程(Interface Engineering)
Agent 会出现在 REST API、Slack、终端等多个表面。挑战在于如何将不同的身份系统(如 Slack 用户 ID 与产品内部 ID)统一映射,确保权限控制在所有入口保持一致。
5. 基础设施工程(Infrastructure Engineering)
95% 的工作与传统服务无异(容器化、云部署、横向扩展)。剩下的 5% 在于应对 Agent 的特性:更长的请求耗时、流式响应(SSE/WebSockets)以及主动触发的任务。
+ 系统工程的实践:Dash 项目
为了证明这一理念,Agno 团队开源了 Dash —— 一个具备自我学习能力的 SQL 数据智能体。它展示了系统工程如何解决实际问题:
- 六层上下文增强:Dash 不直接写 SQL,而是结合表元数据、业务规则、历史查询模式、机构知识、错误学习记录和运行时 Schema 检查。
- 自我进化闭环:当 Agent 执行 SQL 报错时,它会诊断修复并记录“学习心得”。第 100 次查询比第 1 次更准,不是因为模型变强了,而是数据层进化了。
- 架构级安全:分析师 Agent 连接的是只读引擎,工程师 Agent 只能写入特定的 dash Schema。这种物理隔离确保了即便模型“幻觉”产生恶意指令,系统也会在底层将其拦截。
当我们从系统视角审视软件时,许多争论(如 MCP vs CLI)会变得显而易见。不要给 Agent 不受限的权限,要给它定义清晰、边界明确的工具;不要把记忆存在散乱的文件里,要存入数据库。
系统工程不是为了增加复杂性,而是为了让各个组件在交互中产生超越个体的可靠性。