从对话框到生产力引擎:深度拆解 Claude 的四个进化阶梯 |
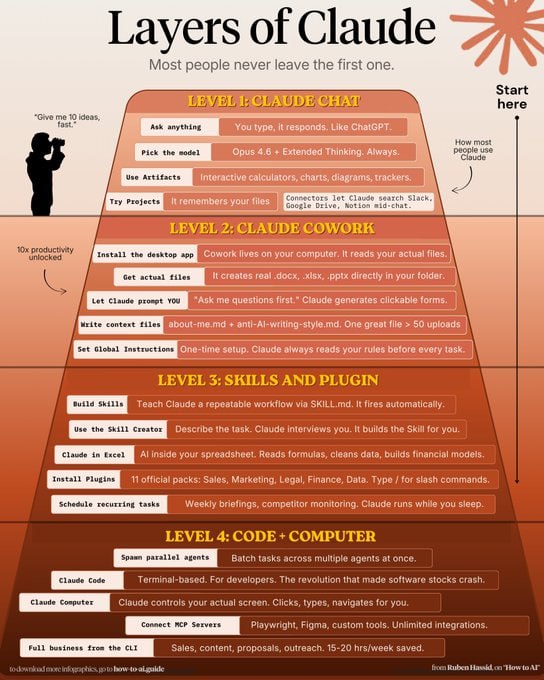
帖子大多数人对 Claude 的认知仍停留在“更好用的聊天机器人”,但这仅仅是冰山一角。Anthropic 正在构建的不是一个问答工具,而是一套完整的数字劳动力体系。根据 Ruben Hassid 总结的“Claude 层次论”,我们可以将 AI 的应用深度分为四个阶段。
+ 第一层:基础对话(Claude Chat)
这是 90% 用户的停留地。在这个阶段,你把它当作加强版的搜索引擎或文案助手。
- 核心逻辑:即时输入,即时反馈。
- 进阶技巧:始终选择 Opus 4.6 + Extended Thinking 模式以获取深度推理;善用 Artifacts 功能,让 AI 直接生成可交互的图表、代码原型和计算器,实现视觉化输出。
- 局限性:缺乏长期记忆,每次对话都是“初次见面”。
+ 第二层:协同办公(Claude Cowork)
当 AI 开始读取你的本地文件并理解你的个人偏好时,它才真正成为你的“数字同事”。
- 核心逻辑:建立个人上下文(Context)。
- 关键动作:安装桌面端应用,让 Claude 直接读取并生成 .docx 或 .xlsx 文件。
- 深度思考:与其不断上传文件,不如编写一份高质量的“全局指令”(Global Instructions)和“背景文件”(如 about-me.md)。一份精准的背景定义,胜过 50 次重复的 Prompt 调优。让 AI 适应你的风格,而不是你每次去迁就它。
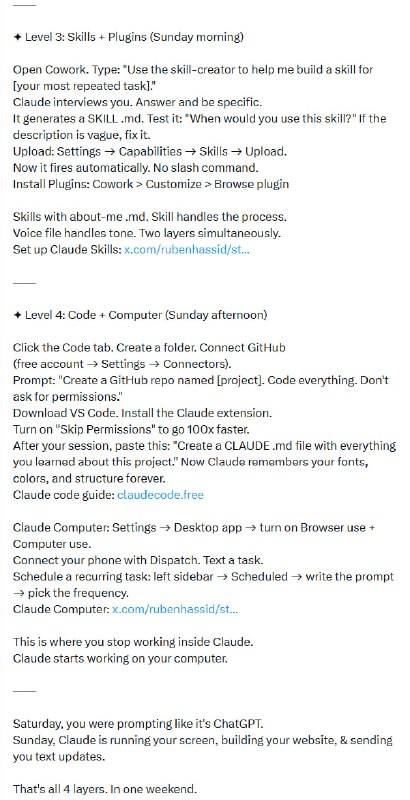
+ 第三层:技能与插件(Skills and Plugin)
这一层级实现了从“单次任务”到“自动化工作流”的跨越。
- 核心逻辑:教给 AI 确定性的技能。
- 关键动作:通过
SKILL.md 定义可重复的工作流,让 Claude 在特定场景下自动触发预设动作。
- 行业集成:利用 Excel 插件直接在表格内进行数据清洗和建模;使用官方提供的营销、法律、金融等 11 个专业插件包。
- 启发:真正的效率不在于你跑得有多快,而在于你构建了多少个可以“边睡觉边运行”的自动化闭环。
+ 第四层:代码与计算机控制(Code + Computer)
这是目前 AI 的最高形态:从“建议者”变为“执行者”。
- 核心逻辑:接管硬件与环境。
- 关键能力:Claude Computer 允许 AI 直接控制屏幕、点击和导航;通过 MCP(Model Context Protocol)连接 Playwright 或 Figma 等专业工具。
- 终极形态:在 CLI(命令行界面)中运行整个业务。通过并行智能体(Parallel Agents)批量处理销售、提案和外发任务。
AI 的竞争已经从“模型参数”转向了“环境接入能力”。一个人能否在未来胜出,取决于他能为 AI 提供多少高质量的上下文,以及敢于交付多少控制权。
从“给我写一段话”到“帮我运行这个业务”,这中间隔着的不是技术门槛,而是思维的鸿沟。不要只把 Claude 当成一个说话好听的秘书,要把它当成一个可以无限扩展的数字大脑。