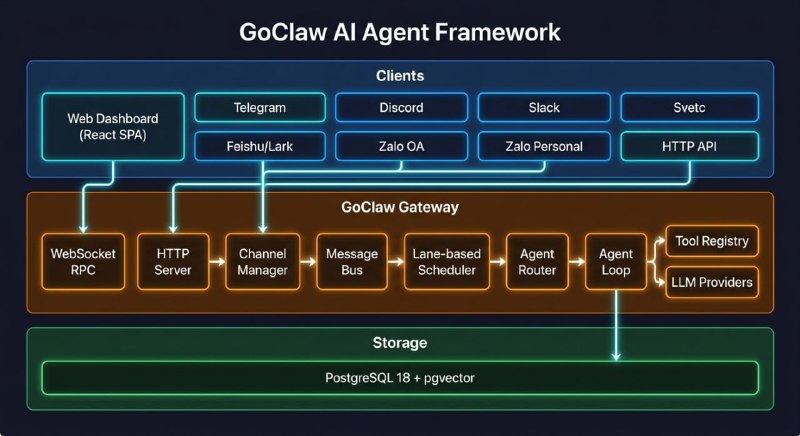
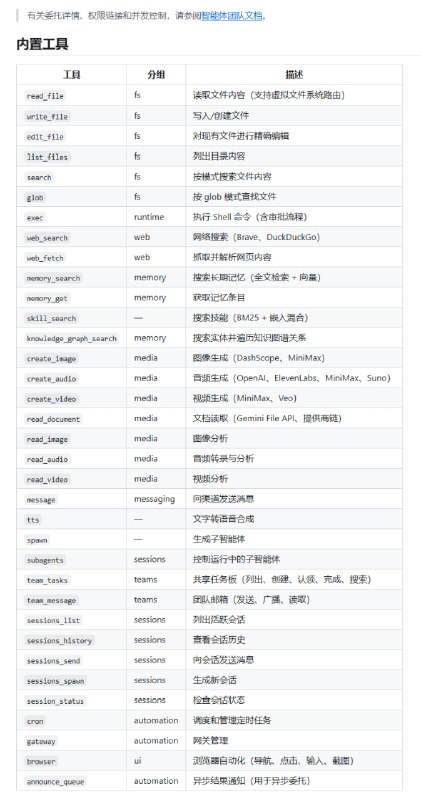
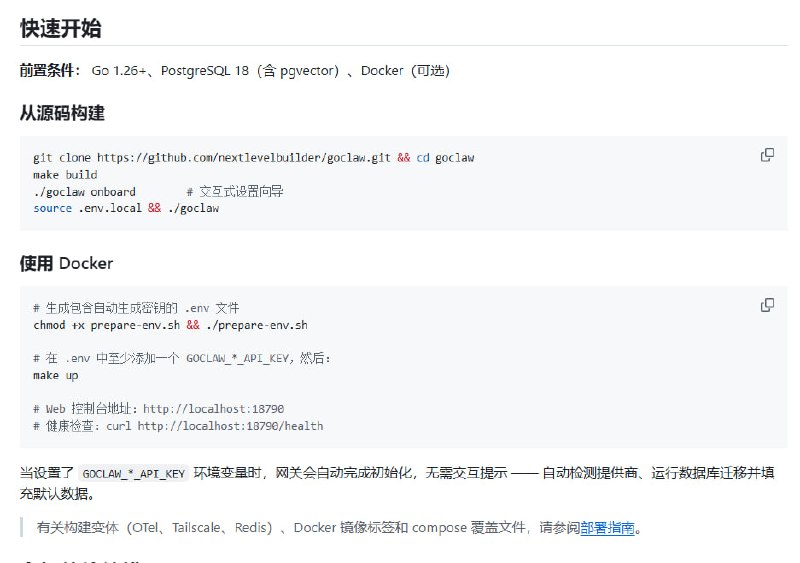
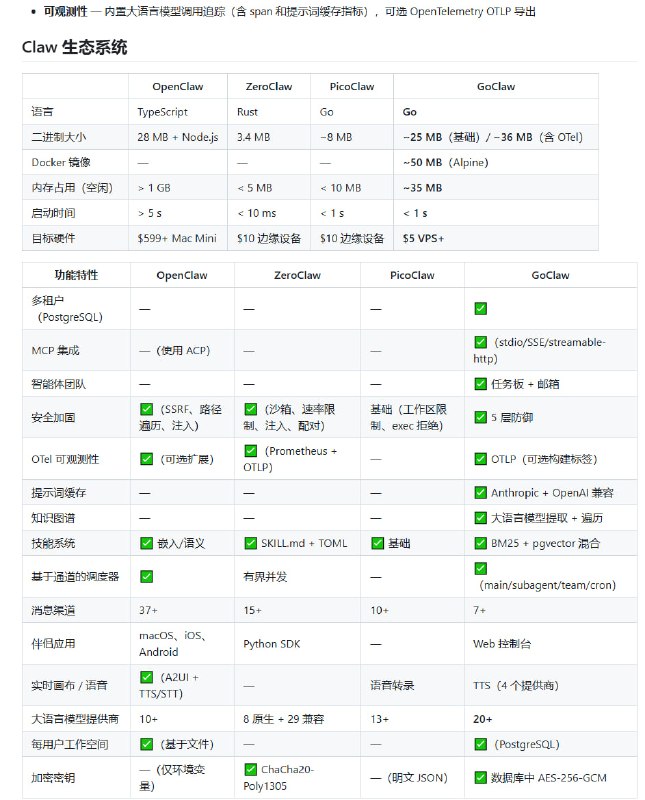
从大厂 L8 顶尖工程师到独立开发者,这不仅是职业路径的切换,更是一场关于自我驱动与时代机遇的深刻实验。前 Meta、微软、Atlassian 资深工程师 Kun Chen 近期分享了他离开大厂“舒适区”后的思考与 AMA 问答,以下是核心观点的深度复盘。|
帖子大厂高阶工程师的真实挑战
在 Meta 和微软等公司担任 L8 职位时,面临的挑战往往不在于技术本身,而在于复杂系统的治理:
1. 权力的平衡与放手:在高层职位,必须学会区分“必须亲自参与”与“必须授权出去”的决策。专注于高影响力决策,容忍次要决策可能出现的偏差。
2. 时间防御系统:当每天收到 100 多条协作请求时,即使是礼貌的回绝也会耗费数小时。建立一套优先级过滤系统,是保持核心产出的唯一方法。
3. 利益相关者博弈:大型项目往往涉及多方利益。对于性格内向的技术人来说,在复杂的职场关系中导航是极大的内耗,这也是许多人选择独立开发的原因之一。
职业成长的底层逻辑
Kun 认为,保持竞争力的秘诀在于“好奇心驱动”而非“任务驱动”:
- 衡量成长的唯一标准:问自己“这个月我做到了哪些上个月还不会做的事情?”
- 走出舒适区:每一次感到成长停滞时的跳槽或转型,长远来看都是巨大的收益。
- 技能优先级的重构:在 AI 时代,与其死磕 DSA 刷题,不如优先掌握系统设计、Agent 编排以及“构建真正有用产品”的能力。
独立开发者的生存哲学
离开大厂并非完全基于理性的财务计算,而是一种感性的追随:
- 财务与理性的博弈:从预期财务回报看,留在顶尖大厂永远是更稳妥的选择。选择独立开发是听从内心的召唤,而非精密的算计。
- 市场前置思维:开发者最容易犯的错误是先写代码再想营销。正确的做法是先与潜在客户交流,根据需求构建产品。
- 为什么是现在:AI 引发的工业革命提供了前所未有的构建效率,加上足够的财务缓冲和家庭状态的稳定,构成了“离职创业”的黄金窗口。
对 AI 与未来的洞察
- 游戏行业变革:AI 将大幅降低制作成本,并催生出真正具有智能 NPC 和动态剧情的生成式内容。
- 个人生产力栈:Kun 倾向于使用极客感十足的工具组合,包括 Claude Code、Neovim、Tmux 和 Wezterm,并倾向于根据需求构建自己的定制化工具。
- 组织形态实验:目前他享受 Solo 状态,旨在探索一个人在 AI 加持下,生产力的边界究竟在哪里。