从工具到结果:AI如何重写服务业的竞争规则 |
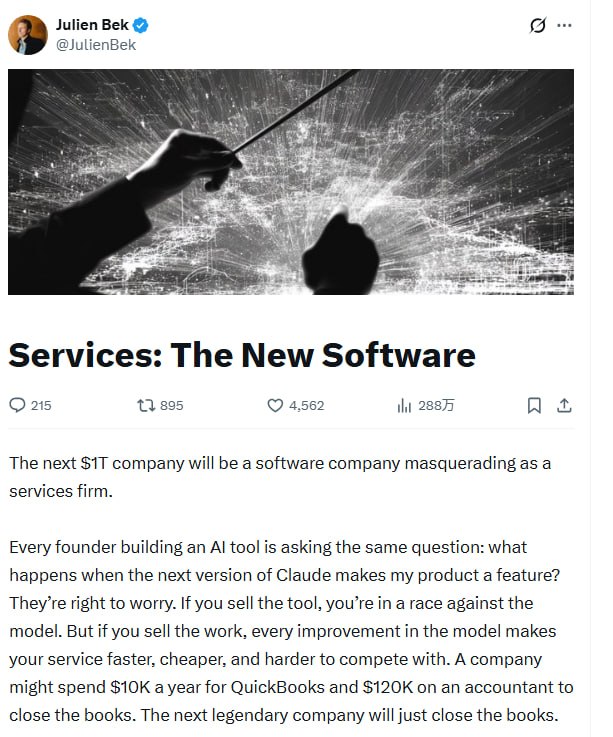
推文AI正在把软件公司变成服务公司。卖工具的在和模型赛跑,卖结果的每次模型升级都让自己更强。外包业务是最佳切入点,因为预算现成、边界清晰、替换阻力最小。
每个做AI工具的创业者都在问同一个问题:下一版Claude出来,我的产品会不会变成一个功能?
这个担心是对的。
卖工具,你在和模型厂商赛跑。卖结果,模型每次升级都在帮你降本提速。一家公司可能每年花一万美元买QuickBooks,花十二万美元雇一个会计关账。下一个伟大的公司,直接把账关掉。
+ 智能与判断
软件工程师的工作,大部分是智能活,小部分是判断活。把需求翻译成代码、写测试、修bug,规则很复杂,但终究是规则。判断不一样,判断需要品味和本能,是在大量失败里沉淀出来的东西。
一年前,大多数Cursor用户把AI当成补全工具。今天,超过一半的任务由智能体发起,不再是人类。软件工程在所有职业的AI工具使用中占比过半,其他所有类别还在个位数。原因很简单:软件工程以智能活为主,AI已经能独立完成大部分,把判断留给人类。
这个临界点,软件工程业最先越过。其他每个行业都会跟上来。
+ 副驾驶与自动驾驶
副驾驶卖工具,自动驾驶卖结果。
早期的逻辑很清楚:模型还不够强,就先给专业人士一个工具,让他们自己决定怎么用。Harvey卖给律所,Rogo卖给投行。专业人士是客户,工具让他们更高效,输出结果由他们负责。
现在不一样了。模型足够聪明,某些领域最好的切入姿态就是自动驾驶。Crosby卖给需要起草NDA的公司,不是卖给外部律师。WithCoverage卖给需要保险的CFO,不是卖给经纪人。客户直接买结果。
任何领域里,智能活占比越高,自动驾驶赢的时间就越早。
+ 外包是楔子
软件预算和服务预算的比例大约是一比六。自动驾驶的真实市场,是一个行业里所有劳动力支出,内部的和外包的加在一起。
但起点应该在外包已经成熟的地方。
一个任务已经被外包,说明三件事:公司接受这件事可以在外部完成;预算科目清晰,可以直接替换;买家已经在购买结果,不是购买时间。用AI原生服务商替换外包合同,是供应商切换。替换内部人员,是组织重组。阻力完全不同。
外包的智能活是楔子,内部的判断活是长期市场。
+ 机会在哪里
Sequoia把各行业的服务市场按智能-判断比例和外包程度做了一张地图。
几个机会值得单独说:
保险经纪(1400-2000亿美元),最大的市场。标准商业险高度标准化,经纪人的价值本质上是比价和填表,纯智能活。分销极度碎片化,没有单一巨头控制客户关系。
会计和审计(500-800亿美元外包),美国五年内流失了约34万名会计,75%的注册会计师接近退休,人才供给结构性短缺,反而让这个行业比其他任何行业都更愿意接受AI。
医疗收入周期(500-800亿美元),人们听到“医疗”就以为是判断活,但账单层几乎是纯智能活。医疗编码是把临床记录翻译成约七万个标准化ICD-10代码,规则复杂但终究是规则。
管理咨询(3000-4000亿美元),市场最大,但判断活占比也最高。有意思的问题是:AI能不能把咨询拆开,数据收集和基准分析自动化,战略建议留给人类?最佳竞争者还不明朗。
+ 真正的困境
2025年增长最快的AI公司是副驾驶。2026年,很多会尝试转成自动驾驶。他们有产品,有客户关系。问题是,卖结果意味着把自己的客户从这件事里切走。这正是纯自动驾驶公司的机会。
创新者窘境的经典形态:你最了解客户需要什么,但你最没办法给他们想要的那个版本。