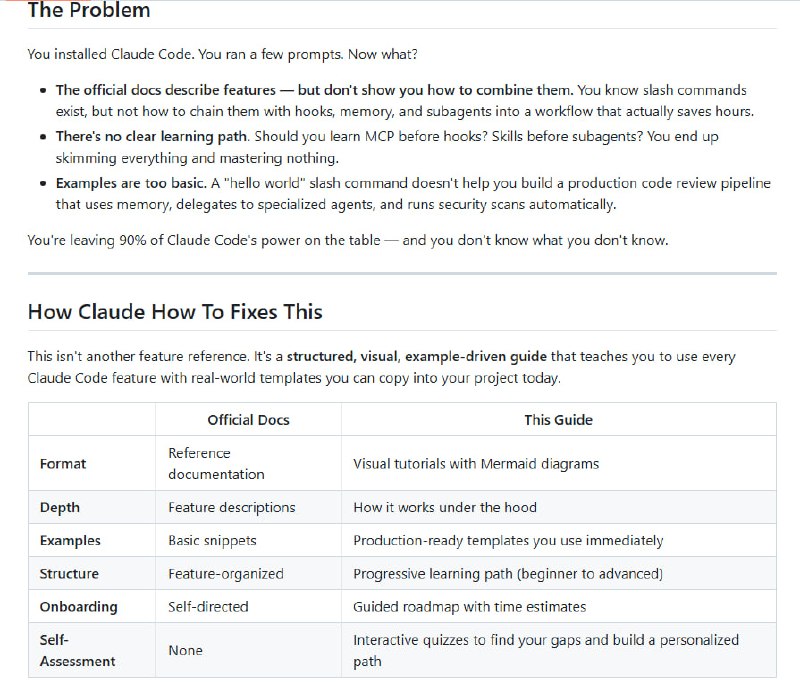
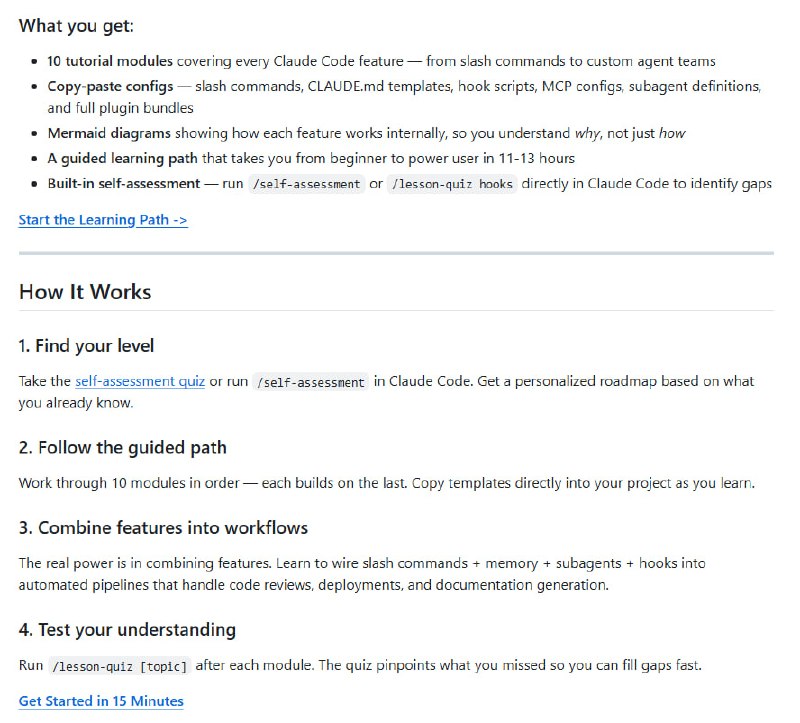
DeepSeek押注Agent:从“会聊天”到“会干活”
服务宕机12小时的热搜还没凉,DeepSeek悄悄挂出了17个岗位。
全部指向同一个方向:Agent。算法研究员、数据评测专家、基础设施工程师,连产品经理都单独开了Agent方向。岗位描述里有一句话值得注意——“重度使用Claude Code、Cursor等AI编程工具者优先”。一家AI公司在招聘时明确要求候选人用竞品工具,这本身就是一种表态。
所谓Agent,用最直白的话说:让AI从“被问才答”变成“自己想、自己干、干完自己检查”。规划任务、调用外部工具、多步执行、长期记忆。过去大模型像一个问答机,Agent更像一个能独立跑任务的进程。底层模型是CPU,Agent才是跑在上面的操作系统。
有观点认为,底层模型的能力已接近某种边际,接下来的竞争转移到“训练Agent”和评测基础设施。这个判断大概是对的。参数规模的军备竞赛跑到一定程度,差距开始在别处显现——谁能把模型的能力接进真实工作流,谁能让Agent在复杂任务里不乱、不循环、不幻觉。
DeepSeek-V3.2已经把思考推理和工具调用融进了正式版,此次招聘像是给这个方向补人手。有网友提到,宕机之后DeepSeek的编码风格突然发生变化,加上支持超长上下文,外界猜测内部正在测试新架构。招聘和模型迭代同步出现,这个时间点不像巧合。
年薪最高154万,实习生待遇也不含糊。钱堆在强化学习、评测、基础设施这几块,说明DeepSeek很清楚卡点在哪。一个Agent系统能不能用,不只取决于模型聪不聪明,还取决于评测数据集够不够准、运行时环境够不够稳、工具调用够不够可靠。这些都是脏活,也都是护城河。
有观点认为接下来半年内Agent会彻底改变工作流,很多执行类岗位将被替代。这个时间表可能太激进,但方向大概没错。
真正没解决的问题是:Agent的自主性和可控性之间的张力。让它更自主,就更容易偏;约束得越死,又回到了问答机。这不是招几个工程师能解决的事,更像是一个还在跑的实验。
服务宕机12小时的热搜还没凉,DeepSeek悄悄挂出了17个岗位。
全部指向同一个方向:Agent。算法研究员、数据评测专家、基础设施工程师,连产品经理都单独开了Agent方向。岗位描述里有一句话值得注意——“重度使用Claude Code、Cursor等AI编程工具者优先”。一家AI公司在招聘时明确要求候选人用竞品工具,这本身就是一种表态。
所谓Agent,用最直白的话说:让AI从“被问才答”变成“自己想、自己干、干完自己检查”。规划任务、调用外部工具、多步执行、长期记忆。过去大模型像一个问答机,Agent更像一个能独立跑任务的进程。底层模型是CPU,Agent才是跑在上面的操作系统。
有观点认为,底层模型的能力已接近某种边际,接下来的竞争转移到“训练Agent”和评测基础设施。这个判断大概是对的。参数规模的军备竞赛跑到一定程度,差距开始在别处显现——谁能把模型的能力接进真实工作流,谁能让Agent在复杂任务里不乱、不循环、不幻觉。
DeepSeek-V3.2已经把思考推理和工具调用融进了正式版,此次招聘像是给这个方向补人手。有网友提到,宕机之后DeepSeek的编码风格突然发生变化,加上支持超长上下文,外界猜测内部正在测试新架构。招聘和模型迭代同步出现,这个时间点不像巧合。
年薪最高154万,实习生待遇也不含糊。钱堆在强化学习、评测、基础设施这几块,说明DeepSeek很清楚卡点在哪。一个Agent系统能不能用,不只取决于模型聪不聪明,还取决于评测数据集够不够准、运行时环境够不够稳、工具调用够不够可靠。这些都是脏活,也都是护城河。
有观点认为接下来半年内Agent会彻底改变工作流,很多执行类岗位将被替代。这个时间表可能太激进,但方向大概没错。
真正没解决的问题是:Agent的自主性和可控性之间的张力。让它更自主,就更容易偏;约束得越死,又回到了问答机。这不是招几个工程师能解决的事,更像是一个还在跑的实验。