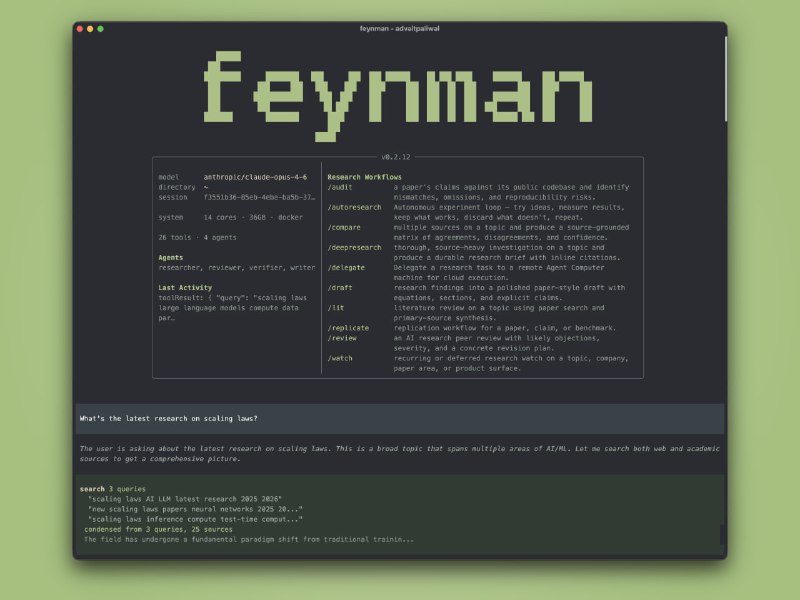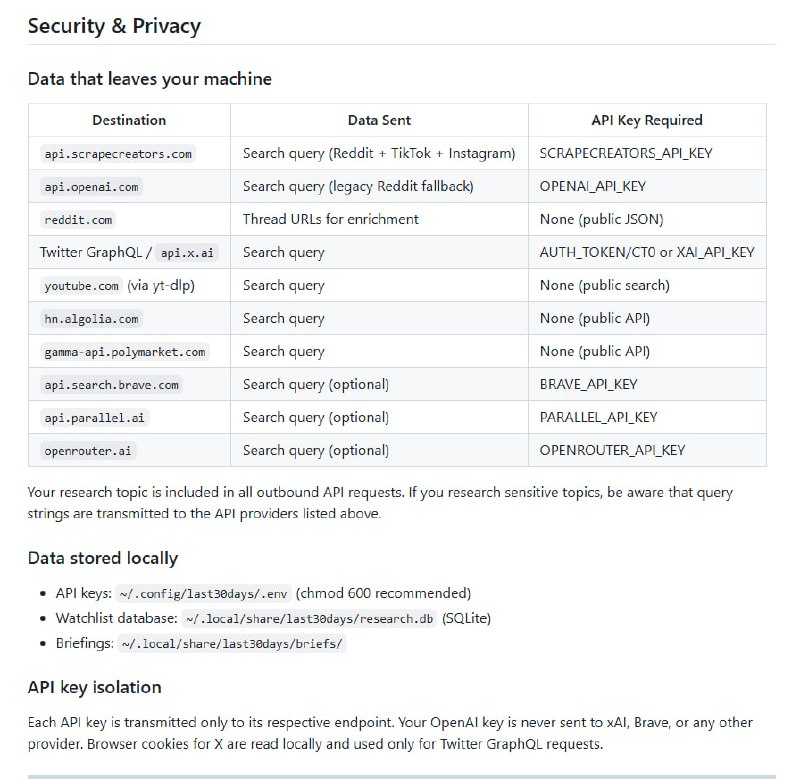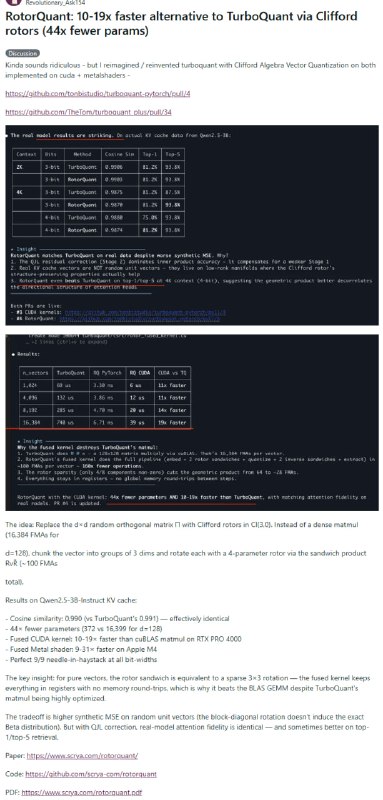
一位开发者用Clifford代数中的“旋子”替换了TurboQuant里的随机正交矩阵,在RTX PRO 4000上实现10-19倍加速,Apple M4上高达31倍,参数量减少44倍,而精度几乎没有损失。
TurboQuant的思路是把一个128维向量扔进128×128的随机旋转矩阵里猛甩,像洗牌一样把所有维度彻底打乱,然后再量化。效果好,但代价是16,384次浮点运算,计算量不小。
RotorQuant换了个角度。把128维向量切成43组,每组3个维度,用一个只有4个参数的Clifford旋子来旋转。总共约100次浮点运算,GPU把所有数据全程锁在寄存器里,连一次内存来回都没有。这才是速度优势真正的来源,跟参数少只有间接关系。
测试结果在Qwen2.5-3B的KV cache上:余弦相似度0.990,对比TurboQuant的0.991,needle-in-haystack测试满分。
有网友指出理论上的漏洞:TurboQuant的全局Haar旋转能把能量均匀散布到所有128个维度;而RotorQuant只在3个维度的小组内旋转,遇到one-hot向量这类极端情况,能量还是集中在几个维度里,这正是低比特量化最怕的场景。这也解释了为什么合成数据上的MSE更差。
有观点认为,这个理论缺陷在真实KV cache分布里基本不会触发,因为实际模型的向量根本不是对抗性构造的。理论最坏情况和工程实际之间的距离,有时候就是整个产品。
另一个有意思的讨论:游戏引擎里早就在用这套数学,Unity和Unreal处理3D旋转用的就是四元数,而四元数本质上是Clifford代数Cl(0,3)里的特殊情况。有网友调侃说,这不过是“图形编程101”里的老把戏换了个场合。
作者坦承整个POC是和Claude一起在一晚上完成的,并没有刻意回避这一点。有人觉得这削弱了“创新”的成色,也有人觉得这恰恰说明AI辅助研究的效率已经到了某个临界点。
目前最缺的是32k乃至128k长上下文下的端到端困惑度测试,以及真实的TPS前后对比数据。3D局部旋转在超长序列里会不会累积误差漂移,这个问题还没有答案。