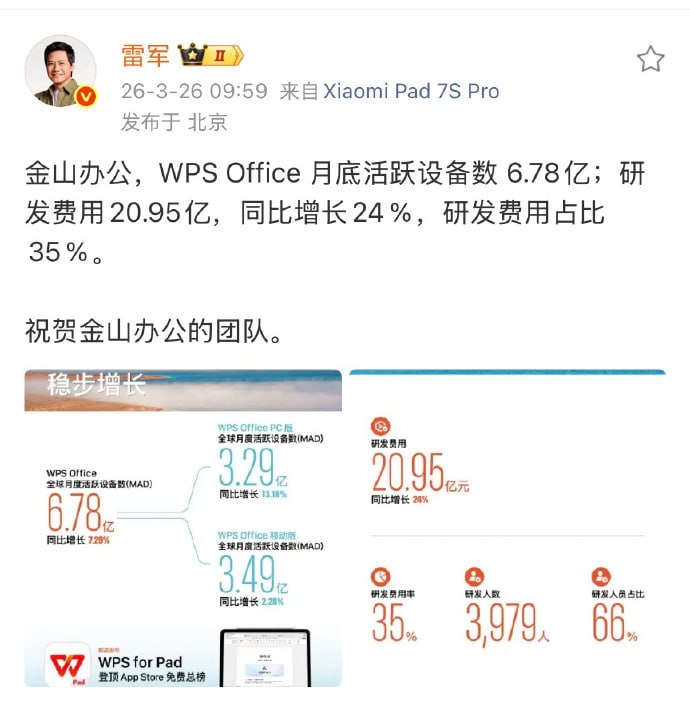
普通人给 AI 一个问题,等一个答案。Karpathy 给 AI 一套思维框架,然后让它在框架里工作。
有网友一语点破:这些提示词本身只是表象,真正的差距在于你如何定义问题。提示词是结果,思维方式才是原因。
以下是 7 种具体用法:
1. 系统拆解提示:遇到复杂问题,强制 Claude 按步骤走:明确问题、列出假设、识别约束、拆分子问题、提三种方案、比较权衡、给出执行路径、预判失败点。这套流程本质上是把你的思维过程外包出去,然后让 AI 替你跑一遍。
2. 第一性原理提示:不要类比,不要总结,从最底层概念开始,一层一层建起来,最后给出心智模型、真实应用和常见误解。适合搞懂 LLM、系统设计、数学原理这类容易“以为自己懂了”的东西。
3. 研究简报生成:让 Claude 给出某个领域的全景图,包括玩家格局、当前路径、失败案例、市场空白、逆向洞察和可落地机会。它会变成一个还不错的分析师。
4. 构建架构提示:从想法到实现,要求它给出最简版本、组件结构、数据流、技术栈、构建顺序、边界情况和扩展策略。省去大量乱猜阶段。
5. 提示词优化器:把你自己写的提示词扔进去,让它优化清晰度、结构、约束条件和输出格式,并解释改了什么、为什么更好。提示词质量会随时间复利增长。
6. 专家模式切换:让它以高级工程师对工程师的方式回答,跳过入门解释,直接聚焦实现、权衡和踩坑点。
7. 批判性思考伙伴:让它不要盲目附和,主动挑战你的假设、指出逻辑漏洞、提出替代方向。这一步大多数人从来不做。
有网友补充了一个实践细节:在开发应用的过程中,你得反复做审计,一旦发现模型开始循环并强行引入不必要的改动,那就是该叫停的时机。
这 7 个提示词值得存起来反复用。不过更值得记住的是:AI 给出的答案质量,上限就是你提出问题的质量。