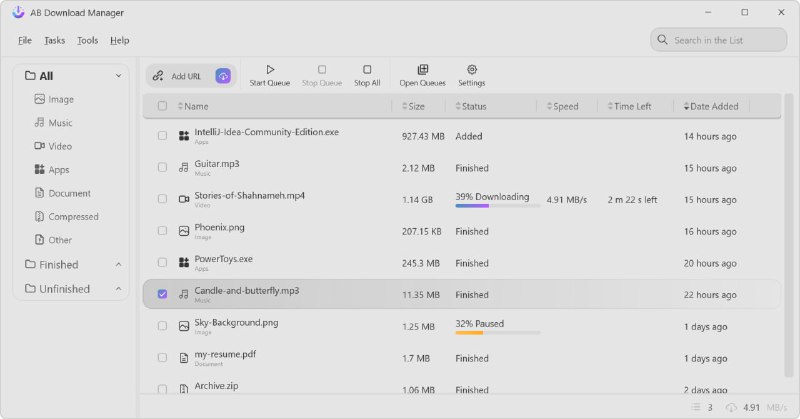
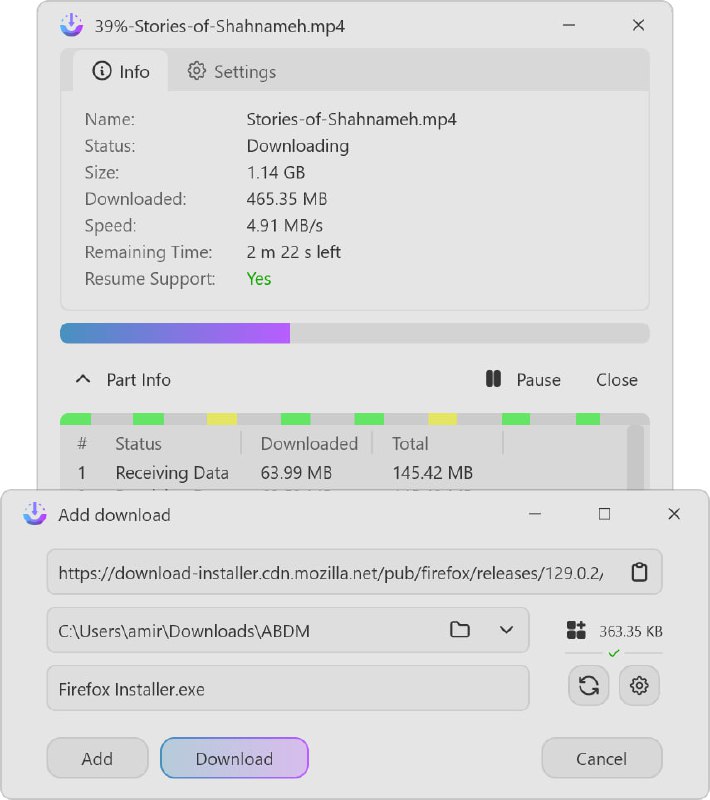
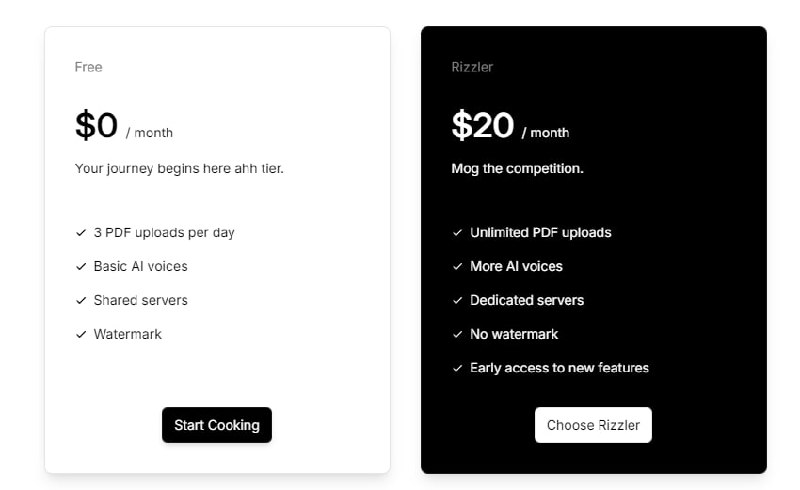
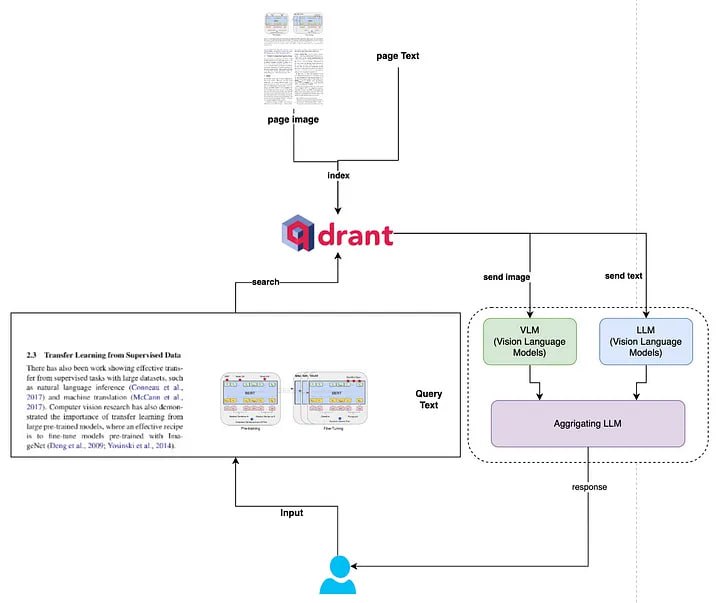
※ 大语言模型(LLM)相关:
- 收录了从 GPT 系列到 Llama、ChatGLM 等主流开源模型
包含模型训练、推理、部署等全流程工具
- 涵盖多语言实现(Python、C++、Rust 等)
- 提示词学习和优化项目
※ 视觉基础模型:
- 收录 SAM(Segment Anything)等视觉大模型
- 包含图像分割、目标检测等视觉任务相关模型
- 多模态模型融合应用
※ 应用开发平台:
- LangChain | LlamaIndex | Dify 等主流开发框架
- 向量数据库解决方案
- 主流 RAG 框架
※ 垂直领域应用:
- 医疗、法律、金融等专业领域的模型
- 学术研究相关工具
- 教育培训资源