npx lumentis:用单个命令从转录文本和非结构化信息生成精美的文档
黑洞资源笔记
-
- WavCraft:基于 LLM 的音频内容创作和编辑 Agent,通过连接各种音频专家模型和 DSP 函数,实现音频内容的创建和编辑

- MoneyPrinterTurbo - 利用大模型,一键生成短视频
只需提供一个视频主题或关键词,就可以全自动生成视频文案、视频素材、视频字幕、视频背景音乐,然后合成一个高清的短视频。
功能特性 🎯
1.完整的 MVC架构,代码 结构清晰,易于维护,支持API和Web界面
2.支持视频文案 AI自动生成,也可以自定义文案
3.支持多种 高清视频 尺寸
-竖屏 9:16,1080x1920
-横屏 16:9,1920x1080
4.支持批量视频生成,可以一次生成多个视频,然后选择一个最满意的
5.支持视频片段时长设置,方便调节素材切换频率
6.支持中文和英文视频文案
7.支持多种语音合成
8.支持字幕生成,可以调整字体、位置、颜色、大小,同时支持字幕描边`设置
9.支持背景音乐,随机或者指定音乐文件,可设置背景音乐音量
10.视频素材来源无版权问题
后期计划 🚀
1.优化语音合成,利用大模型,使其合成的声音,更加自然,情绪更加丰富
2.增加视频转场效果,使其看起来更加的流畅
3.优化视频素材的匹配度 - TagGUI:用于快速添加和编辑图像标签和描述的跨平台桌面应用,旨在为生成器式 AI 模型(如 Stable Diffusion)创建图像数据集,支持自动生成描述。
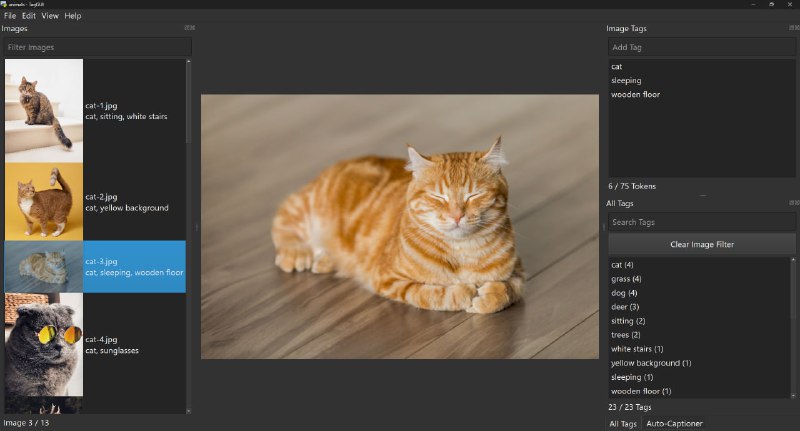
特征
键盘友好的界面,可快速标记
根据您自己最常用的标签自动完成标签
集成稳定扩散令牌计数器
使用 CogVLM、LLaVA、WD Tagger 等模型自动生成标题和标签
可选择加载 4 位自动字幕模型以减少 VRAM 使用
批量标签操作,对标签进行重命名、删除、排序等操作
高级图像列表过滤 -


-

-
- 如何找到 NVIDA GTC 视频的字幕内容,其实也适用于大部分在线视频的 srt/vtt 字幕。
1. 打开 Chrome 开发工具,然后刷新网页(确保字幕是在开发工具打开后加载的)
2. 开启视频字幕,拖放到有字幕的位置,找一个比较特别一点的字幕单词(更容易搜索到)
3. 再开发工具中切换到“Source”,在 “Top” 上点右键,选择“Search In All Files”
4. 输入关键字,然后按回车
5. 从下面的列表找到相应的字幕文件,双击打开,就可以将内容复制出来,保存成 .srt 或者 .vtt 格式的文件 -
-