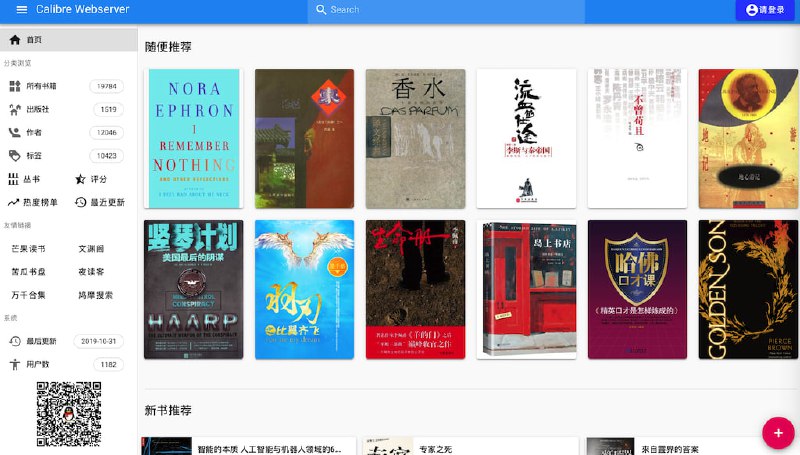
talebook 一个基于Calibre的简单的个人图书管理系统,支持在线阅读。主要特点是:
美观的界面:由于Calibre自带的网页太丑太难用,于是基于Vue,独立编写了新的界面,支持PC访问和手机浏览;
支持多用户:为了网友们更方便使用,开发了多用户功能,支持豆瓣(已废弃)、QQ、微博、Github等社交网站的登录;
支持在线阅读:借助Readium.js 库,支持了网页在线阅读电子书;
支持批量扫描导入书籍;
支持邮件推送:可方便推送到Kindle;
支持OPDS:可使用KyBooks等APP方便地读书;
支持一键安装,网页版初始化配置,轻松启动网站;
优化大书库时文件存放路径,可以按字母分类、或者文件名保持中文;
支持快捷更新书籍信息:支持从百度百科、豆瓣搜索并导入书籍基础信息;
支持私人模式:需要输入访问码,才能进入网站,便于小圈子分享网站;