黑洞资源笔记
-
-
- OpenWebMath:包含互联网上大部分高质量数学文本的数据集,从 Common Crawl 的超过 2000 亿 HTML 文件中过滤并提取出包含 147 亿 Token 的 630 万份文档,OpenWebMath 旨在用于预训练和微调大型语言模型 | #数据集
-
-

- 免费开源的屏幕实时翻译工具
主要特点
文字识别精度高:Translumo 允许同时组合使用多个 OCR 引擎。它使用机器学习训练模型对 OCR 的每个识别结果进行评分,并选择最好的结果。
界面简单:主要想法是制作一种不需要针对每种情况进行手动调整且方便日常使用的工具。
低延迟:实施了多项优化,以减少对系统性能的影响,并最大限度地减少文本出现和实际翻译之间的延迟。
集成现代 OCR 引擎: Tesseract 5.2、WindowsOCR、EasyOCR
可用翻译器: Google 翻译、Yandex 翻译、Naver Papago、DeepL
可用识别语言:英语、俄语、日语、中文(简体)、韩语
可用翻译语言:英语、俄语、日语、中文(简体)、韩语、法语、西班牙语、德语、葡萄牙语、意大利语、越南语、泰语、土耳其语
系统要求
Windows 10 内部版本 19041 (20H1) / Windows 11
DirectX11
8 GB RAM (适用于 EasyOCR 模式)
5 GB 可用存储空间(适用于 EasyOCR 模式)
支持 CUDA SDK 11.8 的 Nvidia GPU(GTX 7xx 系列或更高版本)(适用于 EasyOCR 模式)
Translumo | #工具 - 传奇程序员卡马克 (John Carmack),与强化学习之父萨顿 (Richard Sutton)强强联手了,All in AGI。

2030年向公众展示通用人工智能的目标是可行的。并且与主流方法不同,不依赖大模型范式,更追求实时的在线学习。| 详文 -
-
- 一个基于 Rust 的 Postgres 扩展,可显著提高 Postgres 的全文搜索功能。pg_bm25以现代搜索引擎用来计算搜索结果相关性分数的算法 BM25 命名。

使用该类型的 Postgres 原生全文搜索tsvector有两个主要问题:
性能:在大表上搜索和排名很慢。当表增长到数百万行时,单个全文搜索可能需要几分钟的时间。
功能:Postgres 不支持模糊搜索、相关性调整或 BM25 相关性评分等操作,而这些操作是现代搜索引擎的基础。
pg_bm25旨在弥合 Postgres 全文搜索的本机功能与 ElasticSearch 等专业搜索引擎的本机功能之间的差距。目标是消除将 ElasticSearch 这样繁琐的服务引入数据堆栈的需要。
一些功能pg_bm25包括:
100% Postgres 原生,对外部搜索引擎零依赖;
构建于 Tantivy 之上,Tantivy 是 Apache Lucene 搜索库的基于 Rust 的替代品;
与Postgres 的内置全文搜索和排序功能tsquery和相比,超过 100 万行的查询时间快了 20 倍ts_rank;
支持模糊搜索、聚合、突出显示和相关性调整;
相关性评分使用 BM25,与 ElasticSearch 使用的算法相同;
实时搜索 - 新数据可立即搜索,无需手动重新索引。
pg_bm25站在几个开源巨头的肩膀上。这篇博文的目的是认识这些项目并分享pg_bm25其构建方式,为开发人员提供 Postgres 数据库的简单性和世界级搜索引擎的搜索功能。
pg_bm25 | #扩展 - 用不到500行Python代码写一个简单的Web Server | link

在过去的二十年里,网络以无数的方式改变了社会,但其核心却变化甚微。大多数系统仍然遵循蒂姆·伯纳斯·李二十五年前制定的规则。特别是,大多数 Web 服务器仍然以相同的方式处理与当时相同类型的消息。
本章将探讨他们是如何做到这一点的。同时,它将探索开发人员如何创建不需要重写即可添加新功能的软件系统。 - 用AI还原采访乔布斯于1985年对个人电脑、智能手机及未来科技的看法。 | YouTube
AI Talk是全网首档由aigc技术生成的对话节目,关注科技、商业和人文
剧本:GPT4 艺术设计:Midjourney v5 互动: AI.Talk -
- CryAnalyzer:可以听懂婴儿为什么哭。
它记录并分析超过20000种婴儿哭闹的声音,5秒左右会告诉你婴儿哭闹的原因。识别婴儿情绪状态的准确率超过80%。
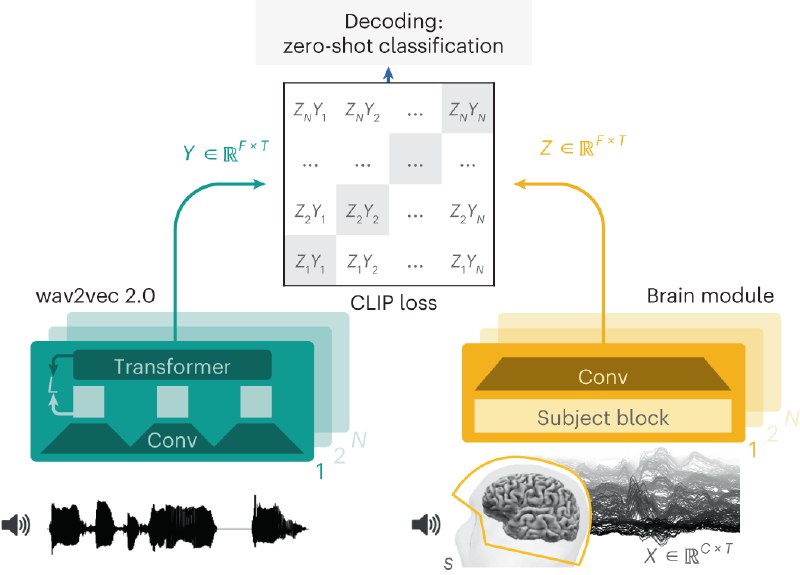
该应用程序的运行方式是记录宝宝的哭声 5 秒钟,然后根据应用程序中存储的历史数据进行分析,以匹配宝宝的特定需求。推荐0-6个月大的婴儿 - BrainMagick:通过分析脑电活动来推断一个人正在听什么,并将其转化为语音。
由Facebook Research 研究的项目,该研究使用非侵入性的电子脑图(EEG)和磁脑图(MEG)技术来解码大脑波并将其转化为语音。这一研究成果已经发表在2023年的 Nature 上,而且项目是开源的。
该模型通过预测与相应大脑活动模式匹配的语音音频的表示来解码语音。该研究在准确性方面取得了显著的改进,特别是在使用MEG记录时,准确性高达73%。
这一成果对于那些因神经系统疾病而失去说话能力的人来说是一个巨大的希望,因为它为恢复他们的沟通能力提供了一条新途径。
工作原理:
1、数据输入与表示: BrainMagick 使用两种类型的数据输入:一是脑电活动数据(EEG或MEG),二是与之相关的音频数据。这些音频数据通过Wav2Vec 2.0模型转换成特定的表示形式。
2、对比损失: 项目使用对比损失(Contrastive Loss)作为训练的目标函数。简单来说,对比损失试图最小化正样本(即与当前脑电活动匹配的音频)与脑电活动表示之间的距离,同时最大化负样本(即与当前脑电活动不匹配的音频)与脑电活动表示之间的距离。
3、多数据集验证: 该方法在4个不同的数据集上进行了验证,包括2个MEG数据集和2个EEG数据集。这些数据集涵盖了175名志愿者和超过160小时的脑电活动记录。
4、性能评估: 在Gwilliams数据集上,该方法达到了41%的top-1准确率。这意味着该模型能够在超过1300个未见过的候选句子中,准确地识别出受试者当前正在听哪个句子,以及该句子中的哪个单词。
在MEG记录的3秒语音片段中,模型能够从超过1500个可能的片段中识别出匹配的片段,准确率高达73%。
技术细节与实现:
依赖与环境: 项目推荐使用NVIDIA GPU进行训练,并且具体列出了所需的软件包和环境设置步骤。
数据预处理与缓存: 项目代码中包含了数据预处理的步骤,包括潜在的下采样和低/高通滤波等。为了提高效率,最耗时的计算被缓存起来。
配置与实验管理: 项目使用Hydra进行配置管理,并使用Dora进行实验的启动和管理。
Nature报道 | 项目地址 | paper - Google Photo带来了三个很实用的AI功能:自动优化合影画面的人脸效果,比如给你AI算出一些笑容、更自然的表情等等。还有移动画面中的一些元素到你喜欢的位置。另外也能够通过算法,将画面中一些原本模糊、缺失的部分进行补齐。
- 350 多个高质量的TailwindCSS 组件,可以将其用于个人项目,完全免费 | tailspark
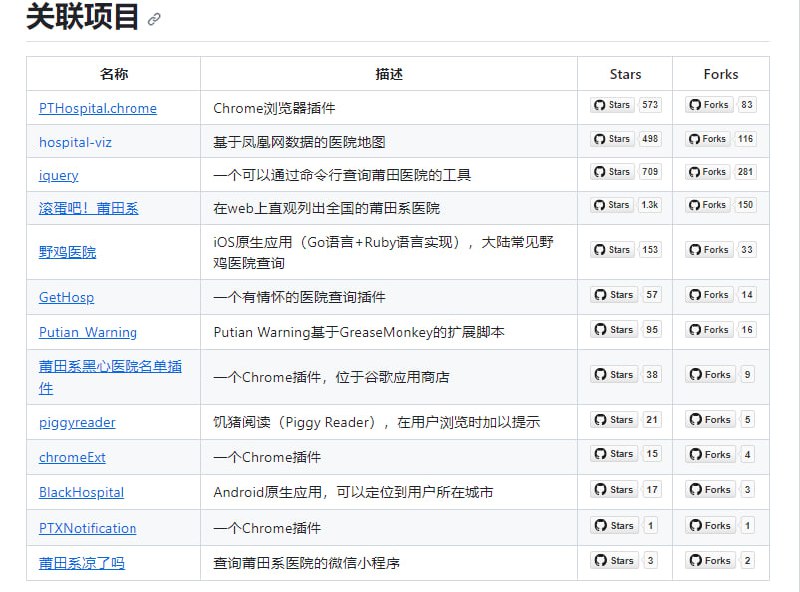
- 一份开源的医院开放数据,该项目的意图是收集汇总与国内一些医疗机构有关的开放数据,供广大寻医问药的患者及家属参考。| link
-