黑洞资源笔记
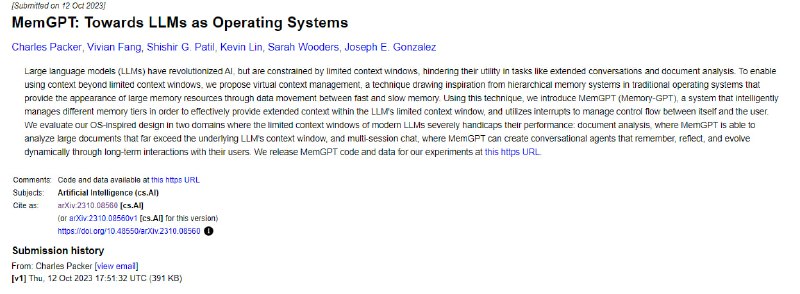
- MemGPT,一种内存管理技术,通过虚拟上下文管理扩展了大型语言模型的上下文窗口,实现了处理长对话和文档分析任务的能力。
-
-
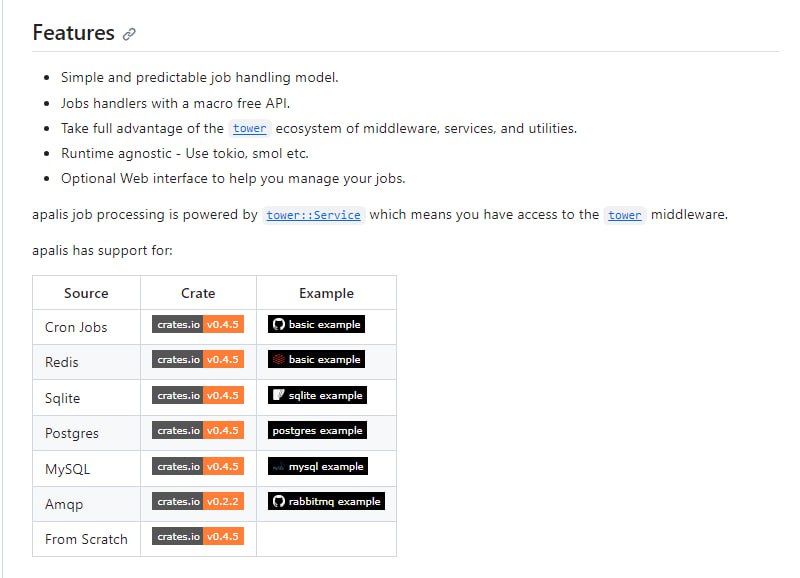
- apalis:Rust写的简单、可扩展多线程后台作业和消息处理库
- torch2jax:旨在实现在JAX中无需拷贝即可调用PyTorch代码,无论是在即时执行还是即时编译(JIT)模式下

- 用于机器人学习和具身AI领域研究的模块化框架
RoboHive 生态系统包含一系列预先存在的和新颖的环境,包括 Shadow Hand 的灵巧操纵、Franka 和 Fetch 机器人的全臂操纵任务以及各种四足运动任务。
与之前的作品相比,RoboHive 提供了精简且统一的任务界面,利用最新的模拟绑定,具有丰富的视觉多样性任务,并支持现实世界开发的通用硬件驱动程序。
RoboHive 的统一界面为研究人员提供了一个方便且易于访问的平台来研究多种学习范式,例如模仿、强化、多任务和分层学习。
RoboHive 还包括大多数环境的专家演示和基线结果,为基准测试和比较提供了标准。
特征:
最广泛、多样化的任务集合
完全可定制的视觉丰富的任务,专为行为泛化而设计。
奖励不可知的任务成功指标
支持多种算法系列+预训练基线
Sim 和硬件无关的机器人类,可在 sim <> real 之间轻松转换
远程操作支持。人类+专家数据集
RoboHive | #框架 - 法律AI相关的资源列表,包括数据集、网站和其他有用链接 | Awesome-LegalAI-Resources
-
- DEV ChatGPT Prompts:开发者ChatGPT提示集锦,帮助开发人员更好地使用ChatGPT来解决问题、进行代码优化和生成文档
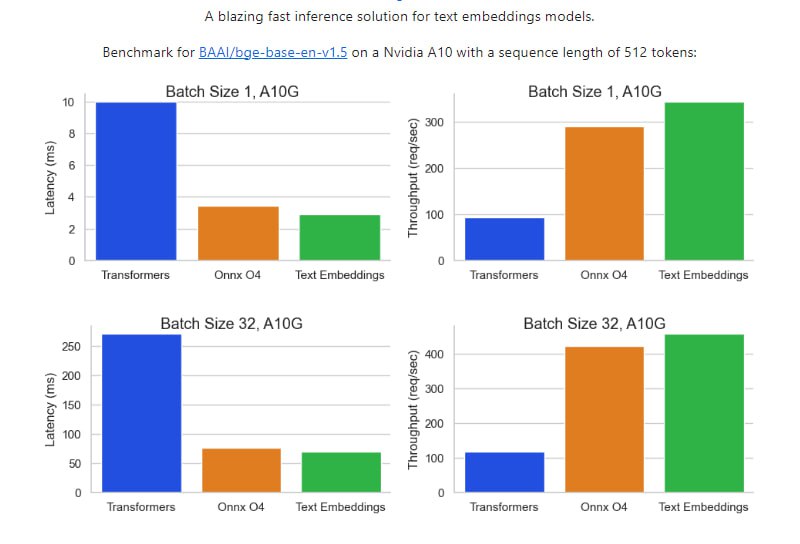
- Text Embeddings Inference:超快接口方案,专注于文本嵌入模型的快速推断
- 深度学习系统&人工智能系统,主要为本科生高年级、硕博研究生、AI系统从业者设计。
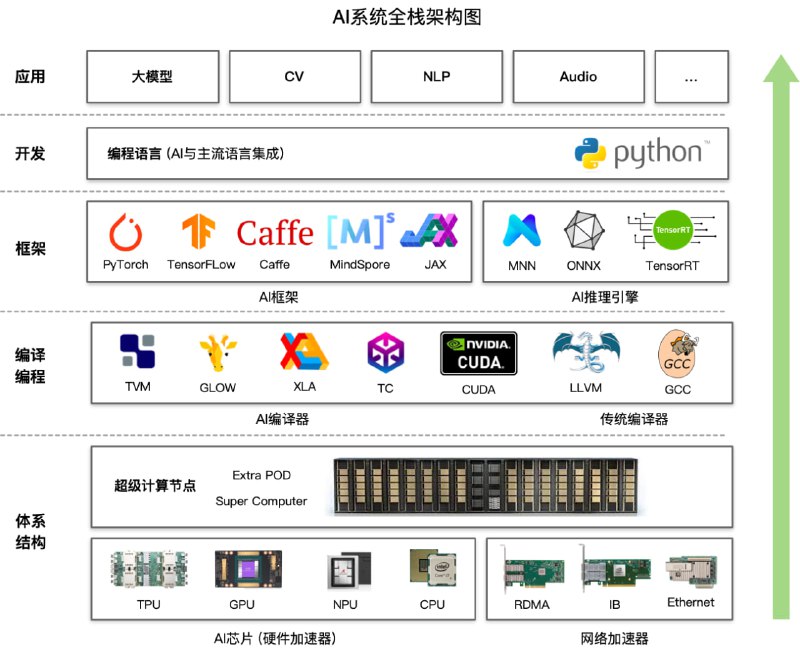
这个开源项目英文名字叫做 Deep Learning System 或者 AI System(AISys),中文名字叫做 深度学习系统 或者 AI系统。
本开源项目主要是探讨和学习人工智能、深度学习的系统设计,而整个系统是围绕着 ZOMI 在工作当中所积累、梳理、构建 AI 系统全栈的内容。
课程主要包括以下五大模块:
第一部分,AI基础知识和AI系统的全栈概述的AI系统概述,以及深度学习系统的系统性设计和方法论,主要是整体了解AI训练和推理全栈的体系结构内容。
第二部分,硬核篇介绍AI芯片,这里就很硬核了,从芯片基础到AI芯片的范围都会涉及,芯片设计需要考虑上面AI框架的前端、后端编译,而不是停留在天天喊着吊打英伟达,被现实打趴。
第三部分,进阶篇介绍AI编译器原理,将站在系统设计的角度,思考在设计现代机器学习系统中需要考虑的编译器问题,特别是中间表达乃至后端优化。
第四部分,实际应用推理系统,讲了太多原理身体太虚容易消化不良,还是得回归到业务本质,让行业、企业能够真正应用起来,而推理系统涉及一些核心算法和注意的事情也分享下。
第五部分,介绍AI框架核心技术,首先介绍任何一个AI框架都离不开的自动微分,通过自动微分功能后就会产生表示神经网络的图和算子,然后介绍AI框架前端的优化,还有最近很火的大模型分布式训练在AI框架中的关键技术。
第六部分,汇总篇介绍大模型,大模型是全栈的性能优化,通过最小的每一块AI芯片组成的AI集群,编译器使能到上层的AI框架,中间需要大量的集群并行、集群通信等算法在软硬件的支持。 - 本书的标题是“理解深度学习”,以区别于涵盖编码和其他实际方面的大部头。主要讨论深度学习的基本思想。

书的第一部分介绍了深度学习模型,讨论了如何训练它们,衡量它们的性能以及如何改进这些性能。接下来的部分考虑了专门用于图像、文本和图形数据的体系结构。
这些章节只需要初级线性代数、微积分和概率知识。
Understanding Deep Learning | #电子书 -
- RIP: 快速、精简的Rust实现的pip库,允许从Rust解析和安装Python PyPI包到虚拟环境中
- 可扩展的轻量级一站式训练、推理深度学习框架。它集成了各种高效的微调方法,如LoRA、QLoRA、阿里云自研的ResTuning-Bypass等,以及开箱即用的训练推理脚本,使开发者可以在单张商业级显卡上微调推理LLM&AIGC模型。此外,SWIFT与PEFT完全兼容,使开发者可以在ModelScope模型体系中使用PEFT的能力。
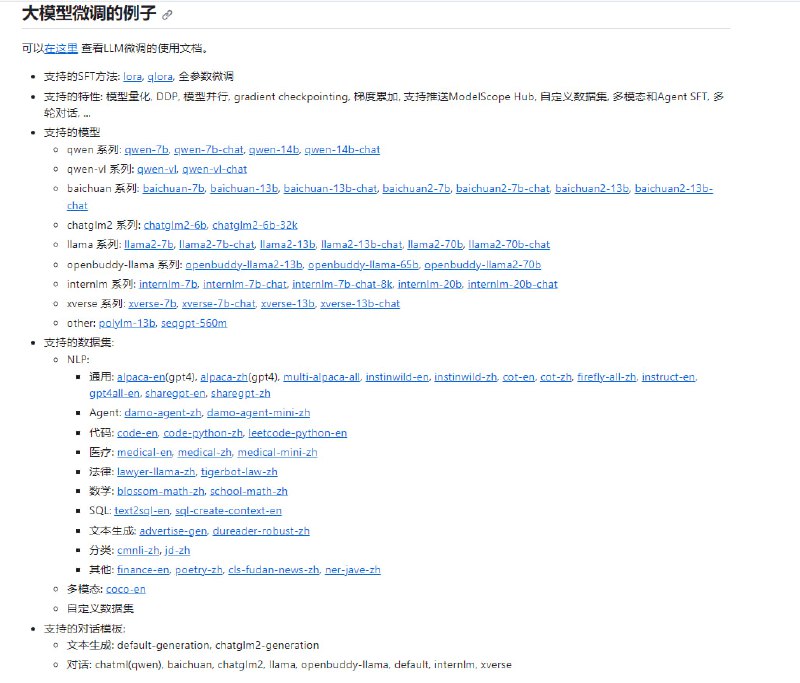
目前支持的方法:
LoRA:LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
Adapter:Parameter-Efficient Transfer Learning for NLP
Prompt: Visual Prompt Tuning
Side: Side-Tuning: A Baseline for Network Adaptation via Additive Side Networks
ResTuning-Bypass
所有在PEFT上提供的tuners
主要能力:
可以通过model-id使SWIFT或PEFT的方法使用ModelScope Hub中的模型
在单次训练或推理中可以使用多个tuners
支持调用activate_adapter或deactivate_adapter或set_active_adapters来使部分tuner激活或失活,用户可以在推理时同时加载多个独立的tuners在不同线程中并行使用。
swift | #框架 - Corax: Core RL in JAX:JAX强化学习算法库
它旨在为 RL 算法提供模块化、纯功能性组件,可以轻松地用于不同的训练循环和加速器配置。目标是提供强大的基线代理,可以为未来的强化学习研究进行分叉和定制。 - Cannoli:用 Obsidian Canvas 编辑器构建和运行无代码 LLM 脚本
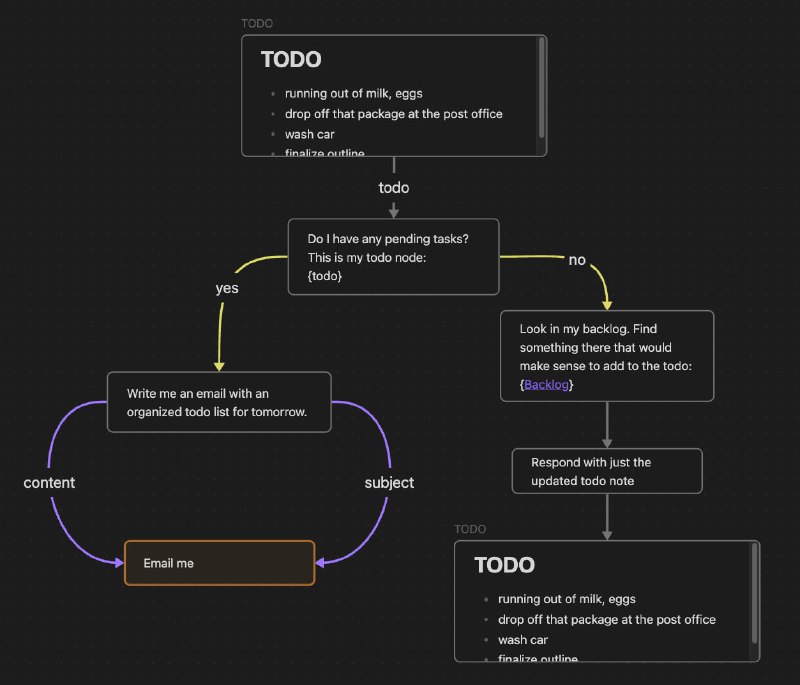
Cannolis 是利用 Openai API 读取/写入您的保管库并使用 HTTP 请求执行操作的脚本。Cannolis 是在 Obsidian Canvas 编辑器中创建的,使用卡片和箭头来定义变量和逻辑。它们可以使用控制功能区按钮或命令选项板在 Obsidian 中运行。
使用颜色或前缀,你可以创建不同类型的节点和箭头来定义基本逻辑功能,例如变量、字段、循环和分支选择。如果 Canvas 是有向无环图并遵循 Cannoli 模式,则它可以作为 cannoli 运行。
Cannoli 还可用于制作具有自定义逻辑和功能的 llm 聊天机器人。完成流媒体和可定制的格式。 - 现代统计学导论(第二版)
作者希望读者从这本书中获得三个想法,除了形成统计思维和方法的基础。
1. 统计学是一个应用广泛的实践领域。
2. 你不必是数学大师就能从有趣的真实数据中学习。
3. 数据是混乱的,统计工具并不完美。然而,当你理解这些工具的优点和缺点时,你可以用它们来了解世界的有趣事物。
主要内容:
第一部分:数据介绍。数据结构、变量、摘要、图形以及基本的数据收集和研究设计技术。
第二部分:探索性数据分析。数据可视化和总结,特别强调多变量关系。
第三部分:回归建模。使用线性和逻辑回归对数值和分类结果进行建模,并使用模型结果描述关系并进行预测。
第四部分:推理基础。案例研究用于介绍随机化测试、自举间隔和数学模型的统计推理思想。
第五部分:统计推断。使用随机化测试、自举间隔和数学模型对数值和分类数据进行进一步的统计推断细节。
第六部分:推理建模。将迄今为止提出的推理技术扩展到线性和逻辑回归设置,并评估模型性能。
Introduction to Modern Statistics (2nd Ed) | #电子书 - 一个类似于Readerwise的功能强大的商业化浏览器插件,可以对网页内容进行标记、收藏和保存,也支持接入AI对网页总结。
所有数据都保存在本地,可以本地对保存的网页、PDF进行全文检索检索。
Memex | Chrome Store | home | #插件