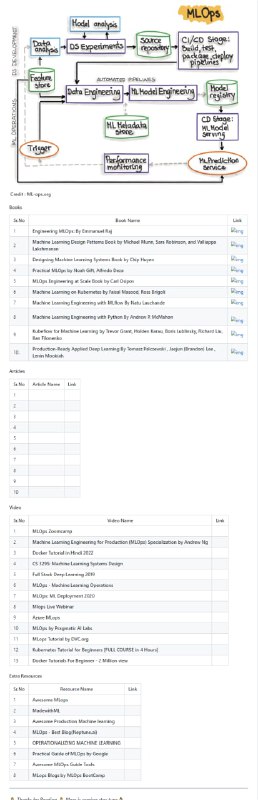
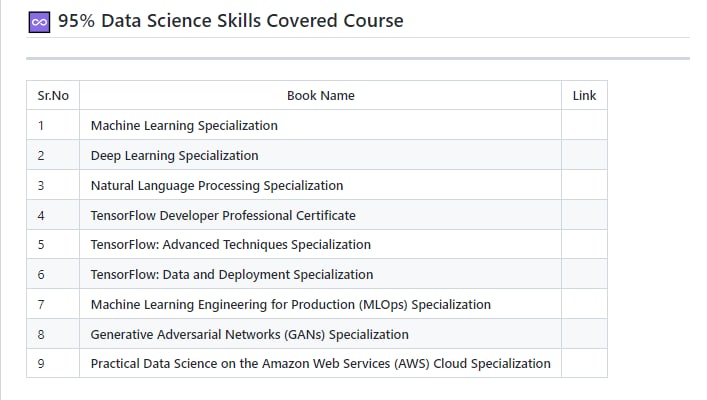
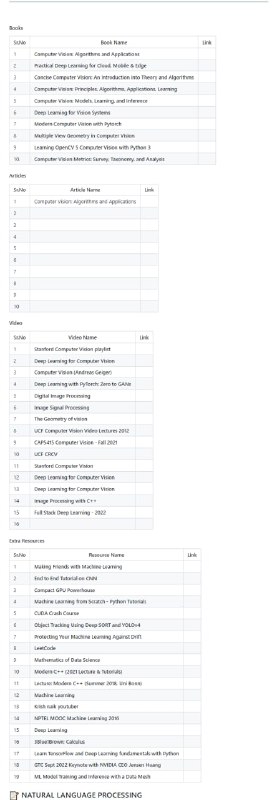
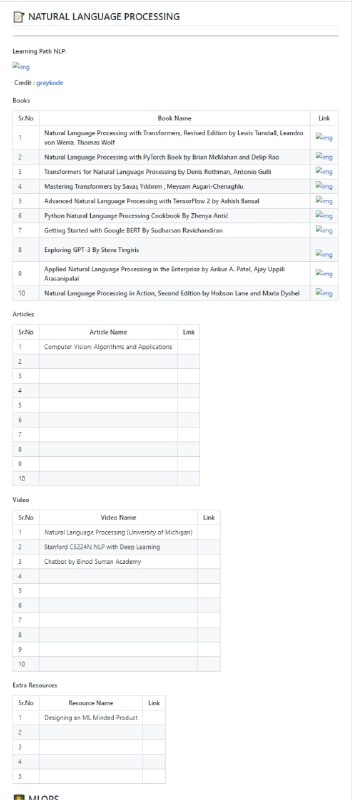
黑洞资源笔记
-
-
-
- 这是slack如何决定发送通知的流程图。
这是一个很好的例子,说明为什么一个简单的功能可能需要更长的时间。
这也可以解释为什么人们有时没有收到通知或清除红点。 - 这个叫 html.to.design 的 Figma 插件可以一键把网站导入成设计稿

将任何网站转换为完全可编辑的Figma设计。利用现有网站并将其html导入Figma以开始自己的设计,而无需从头开始构建每个元素。
安装此插件,html.to.design,在空白的 Figma 文件上搜索插件下的“html.to.design”,或使用 cmd+/。在浏览器中打开要转换的网站并复制 URL,将URL粘贴到插件中,选择设备和尺寸,然后单击“导入”将html转换为Figma设计。
传送门 | #工具 #插件 -
- 现代可扩展的Python项目管理器 | Hatch
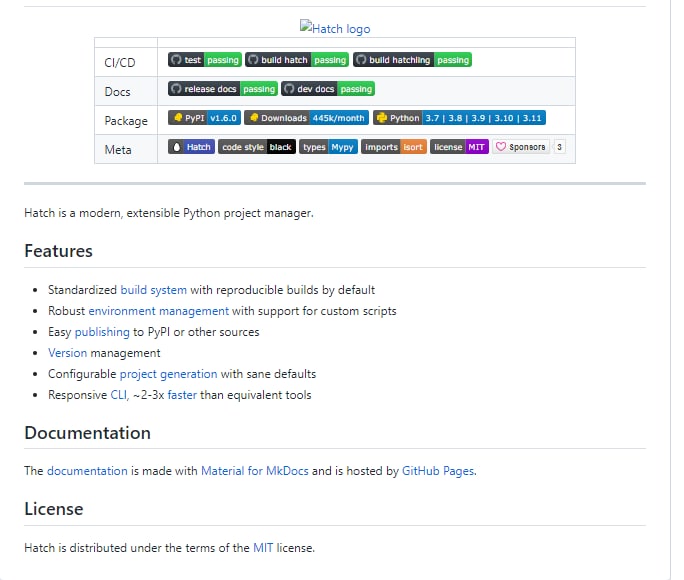
- 面向文本分析的低代码自动化工具 一个开源的、低代码的、由AI驱动的自动化工具。Obsei由以下部分组成
从各种来源收集非结构化数据,如Twitter上的推文、Reddit上的Subreddit评论、Facebook上的页面帖子评论、App Stores评论、Google评论、Amazon评论、新闻、网站等。
分析器。用各种人工智能任务分析收集的非结构化数据,如分类、情感分析、翻译、PII等。
信息员。将分析的数据发送到各种目的地,如票务平台、数据存储、数据框架等,以便用户可以采取进一步的行动,并对数据进行分析。
所有的观察者都可以在数据库(Sqlite、Postgres、MySQL等)中存储他们的状态,这使得Obsei适用于预定作业或无服务器应用程序。
未来的方向--
面向文本、图像、音频、文档和视频的工作流
从所有可能的私人和公共渠道收集数据
将每个可能的工作流程添加到人工智能下游应用中,以实现人工认知工作流程的自动化
obsei | #工具 - 从类似Markdown的文本创建漂亮的级联时间线 | Markwhen
-
-
-
- 面向人脸识别的百万人脸图像数据集
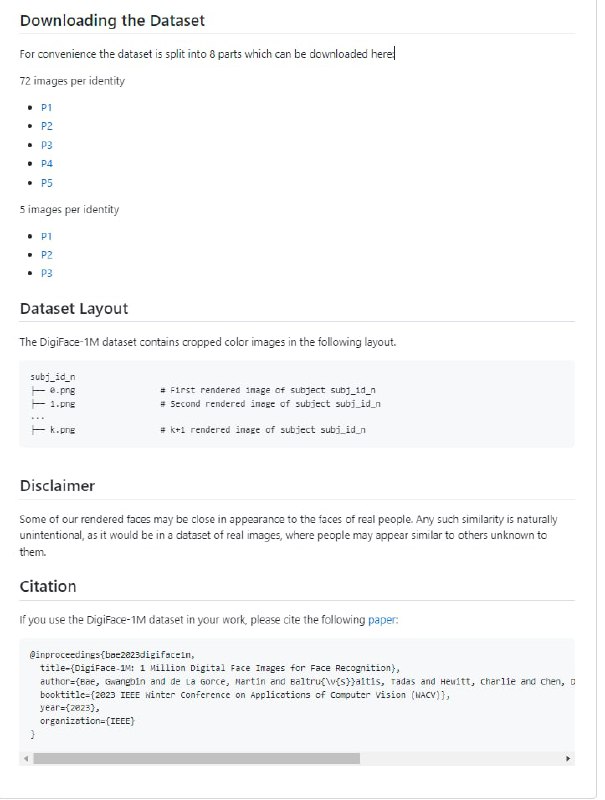
DigiFace-1M数据集是100多万张用于人脸识别的不同合成人脸图像的集合。
它在我们的论文《DigiFace-1M: 1 Million Digital Face Images for Face Recognition》中被介绍,可用于训练面部识别的深度学习模型。
该数据集包含:
720K的图像,10K的身份(每个身份72张图像)。对于每个身份,有4组不同的配件被采样,每组有18张图像被渲染。
500K的图像,100K的身份(每个身份5张图像)。对于每个身份,只有一套配件被取样。
DigiFace-1M数据集可用于非商业研究,并根据LICENSE中的许可进行授权。
DigiFace-1M Dataset | #数据集 - 用于神经网络高效训练的数据流库(PyTorch)
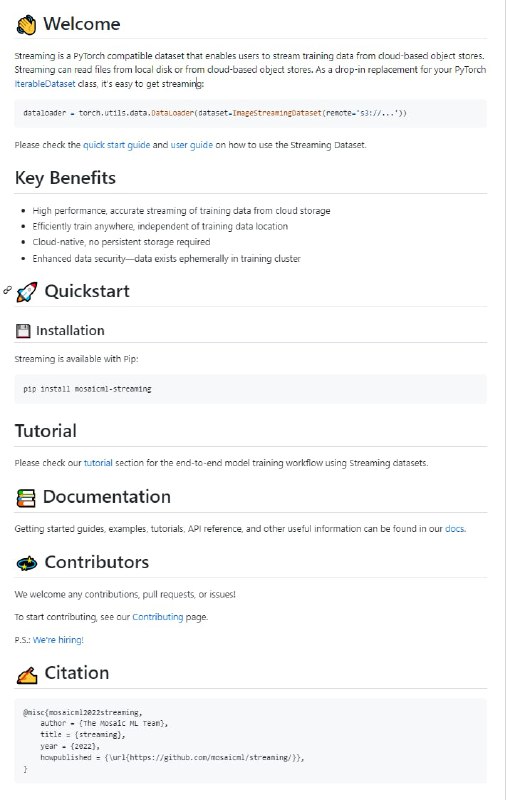
Streaming是一个与PyTorch兼容的数据集,它允许用户从基于云的对象存储中流式传输培训数据。流可以从本地磁盘或基于云的对象存储读取文件。作为PyTorch IterableDataset类的替代品,很容易获得流媒体
Website | Getting Started | Docs |Github | #机器学习 - TencentPretrain:腾讯预训练模型框架
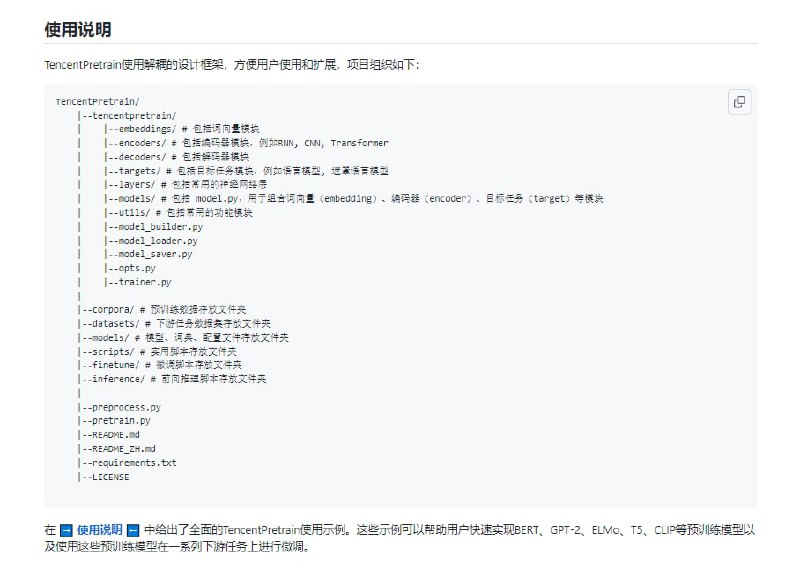
预训练已经成为人工智能技术的重要组成部分,为大量人工智能相关任务带来了显著提升。TencentPretrain是一个用于对文本、图像、语音等模态数据进行预训练和微调的工具包。TencentPretrain遵循模块化的设计原则。通过模块的组合,用户能迅速精准的复现已有的预训练模型,并利用已有的接口进一步开发更多的预训练模型。通过TencentPretrain,我们建立了一个模型仓库,其中包含不同性质的预训练模型(例如基于不同模态、编码器、目标任务)。用户可以根据具体任务的要求,从中选择合适的预训练模型使用。TencentPretrain继承了开源项目UER的部分工作,并在其基础上进一步开发,形成支持多模态的预训练模型框架。
TencentPretrain有如下几方面优势:
可复现 TencentPretrain已在许多数据集上进行了测试,与原始预训练模型实现(例如BERT、GPT-2、ELMo、T5、CLIP)的表现相匹配
模块化 TencentPretrain使用解耦的模块化设计框架。框架分成Embedding、Encoder、Target等多个部分。各个部分之间有着清晰的接口并且每个部分包括了丰富的模块。可以对不同模块进行组合,构建出性质不同的预训练模型
多模态 TencentPretrain支持文本、图像、语音模态的预训练模型,并支持模态之间的翻译、融合等操作
模型训练 TencentPretrain支持CPU、单机单GPU、单机多GPU、多机多GPU训练模式,并支持使用DeepSpeed优化库进行超大模型训练
模型仓库 我们维护并持续发布预训练模型。用户可以根据具体任务的要求,从中选择合适的预训练模型使用
SOTA结果 TencentPretrain支持全面的下游任务,包括文本/图像分类、序列标注、阅读理解、语音识别等,并提供了多个竞赛获胜解决方案
预训练相关功能 TencentPretrain提供了丰富的预训练相关的功能和优化,包括特征抽取、近义词检索、预训练模型转换、模型集成、文本生成等
项目地址 | 项目文档 |#框架