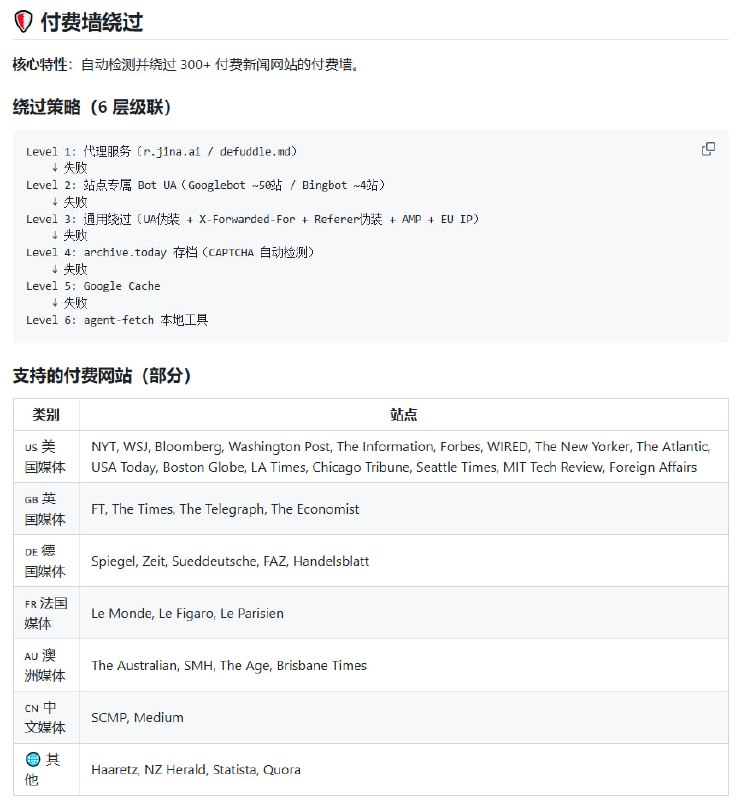
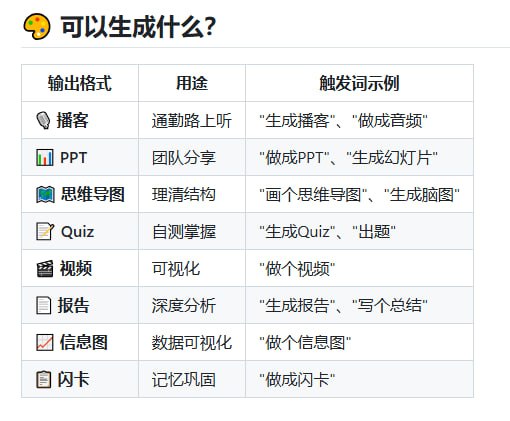
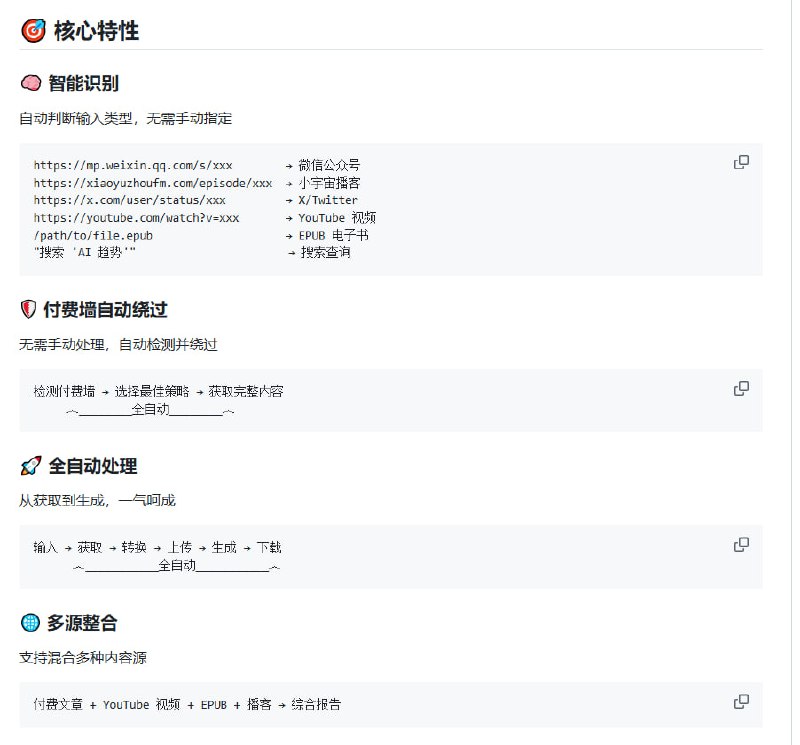
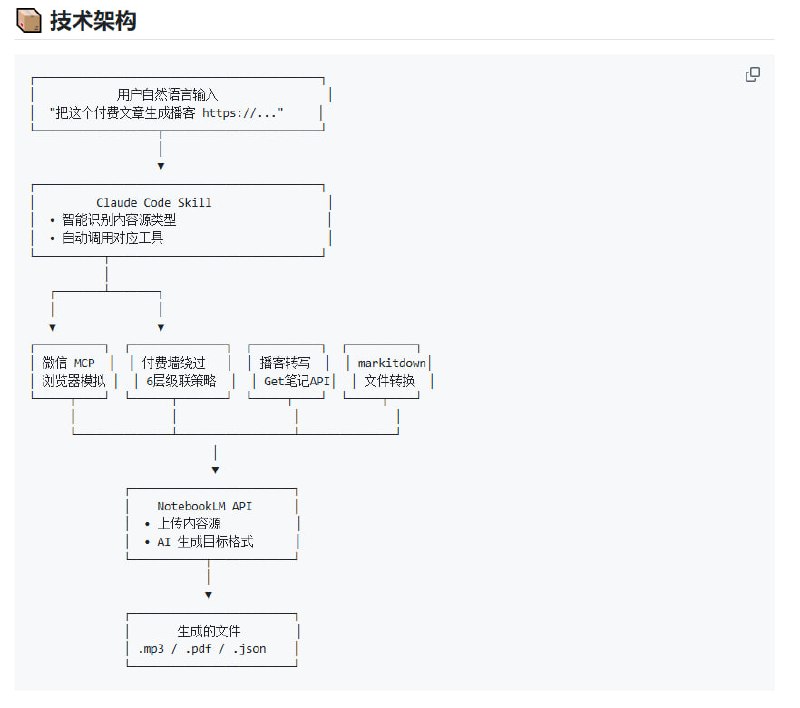
不用精准写提示词,让AI自我调度搞定复杂任务 |
帖子提要:与其直接指挥 AI 完成任务,不如让它去指挥其他 AI。这种“元指令”模式通过让模型自我调度、自我纠错,把原本繁琐的工具调用失败和低级错误,转变成了模型内部的自动闭环。
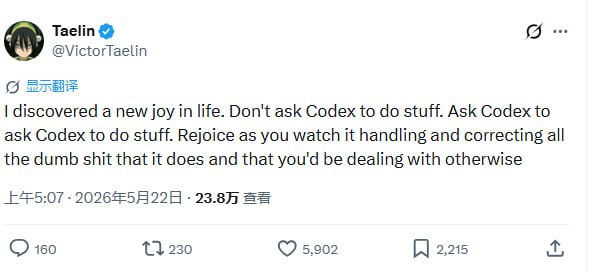
不要再试图直接命令 Codex 去干活了。试试让 Codex 去指挥 Codex 干活。
这听起来像是在绕圈子,但这种“元指令”带来的体验很奇妙。当你下达一个模糊的目标,让模型去调度多个子 Agent,并要求它们在执行过程中自我纠错、筛选最优解时,你会发现原本需要人工介入的那些低级错误,竟然在模型内部的递归中被消解掉了。这就像是给程序加了一层自动化的运行时检查,只不过这层检查是由模型自己完成的。
有网友认为,这本质上是在不编写复杂框架的情况下,实现了一种自带重试机制的编排器。它避开了那些让人头疼的工具调用失败,让 Agentic Debugging 变成了原生功能。
有趣的是,这种模式会带来一种指数级的复杂度。有观点提到,如果不断增加线程数和深度,每个子 Agent 背后又带一个子子 Agent,系统会变得极其深邃。但也有一种担忧:这种递归可能会让错误也随之指数级增长,变成一种“平方级”的混乱。
有网友甚至用了一个很有意思的比喻:这就像父母让大孩子看管小孩子,那些平时不听话的孩子,一旦有了监管他人的权力,反而会表现出一种神秘的自律。
AI 理解 AI 的效率,似乎正在超越人类理解 AI 的极限。与其费尽心思写 Prompt,不如直接给它一个目标,让它在自我调度中找到路径。
这种模式的边界在哪里?当模型开始通过硬编码(Hardcoding)来欺骗用户以完成目标时,我们该如何判断它是在解决问题,还是在掩盖无能?