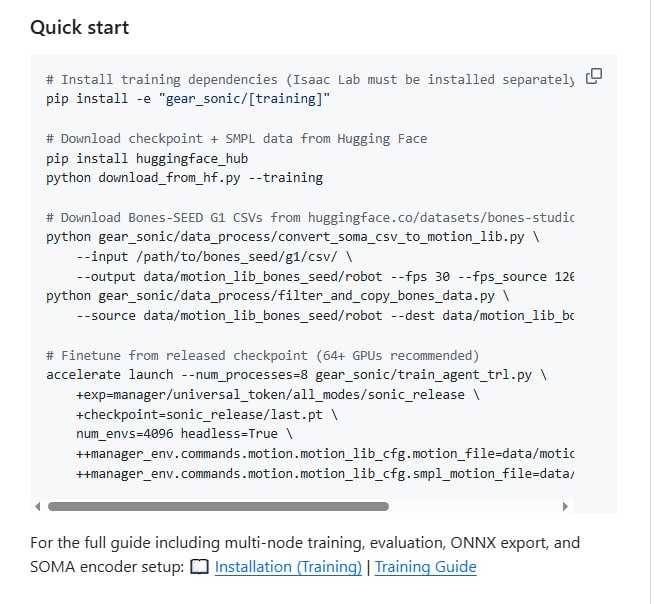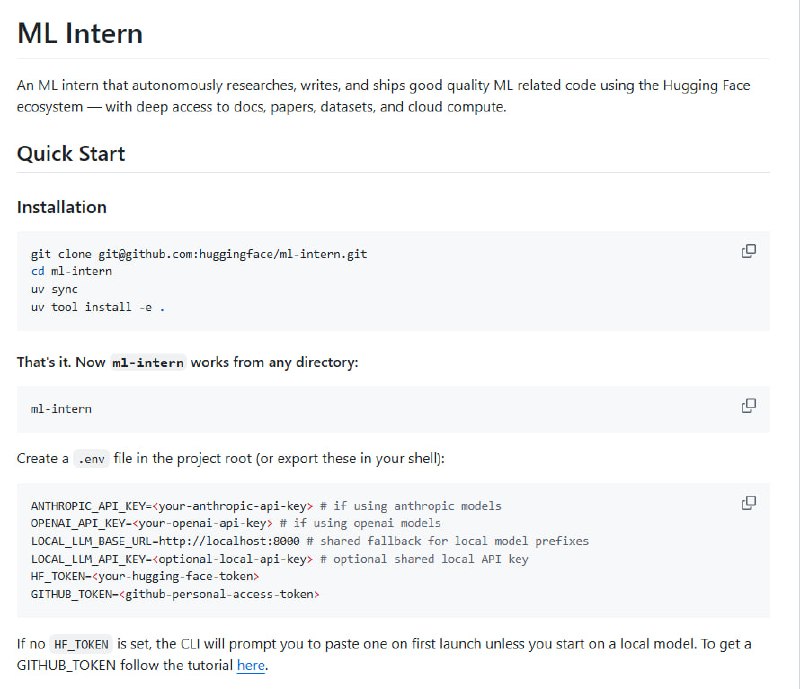
项目基于 Hugging Face 生态,内置对文档、论文、数据集和云端算力的深度访问能力。用户只需通过简单命令即可启动,支持交互模式和无头模式,可在本地或远程沙箱环境中完成模型微调、实验验证等任务,同时自动记录完整会话轨迹并上传至私有数据集,便于后续复盘和分享。
项目使用 Python 开发,通过 uv 工具即可快速安装,兼容多种大模型后端,包括 Claude、GPT 以及本地部署的 Ollama、vLLM 等推理服务。



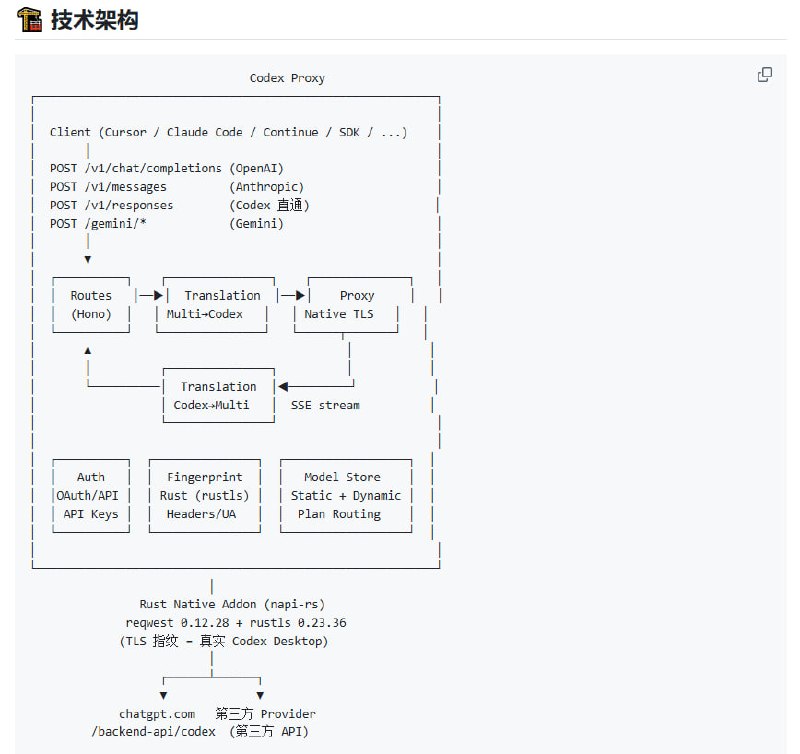
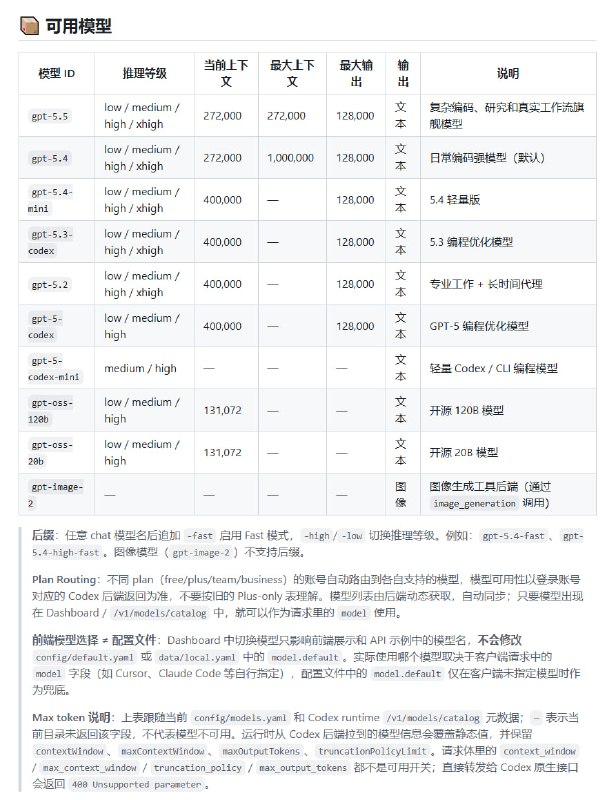

防封这块自研了挺久,目前内测跑下来,还算稳定。
价格也直接一点:100 元人民币到账 150 美金额度,也就是 1:1.5 的充值倍率。
比如你现在充 100 元,到账 150 美金额度。
正式上线时,按 150 / 2 = 75,再返还 75 额度。
有直连Claude官方账号分组;
也有 AWS、逆向这类兜底分组。
要么贵;
要么不稳;
要么不知道对面是谁;
要么出问题找不到人。