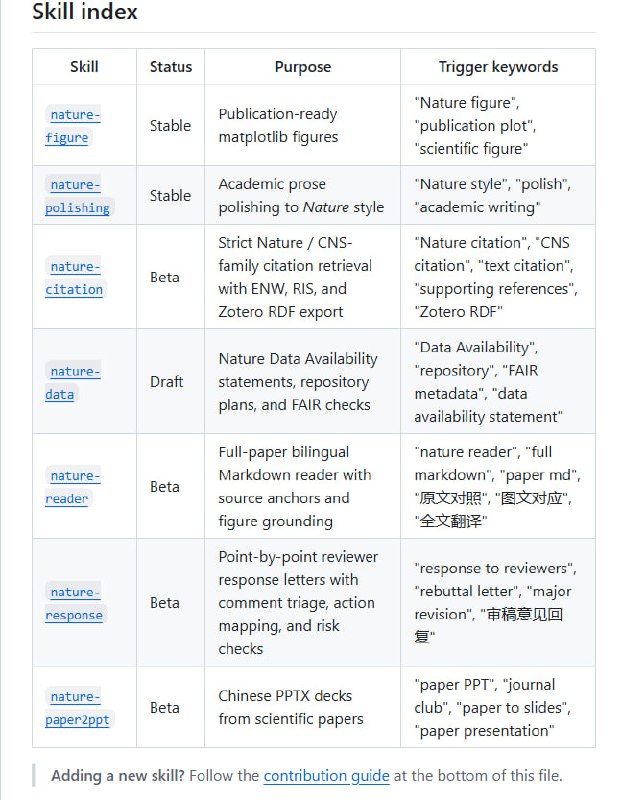
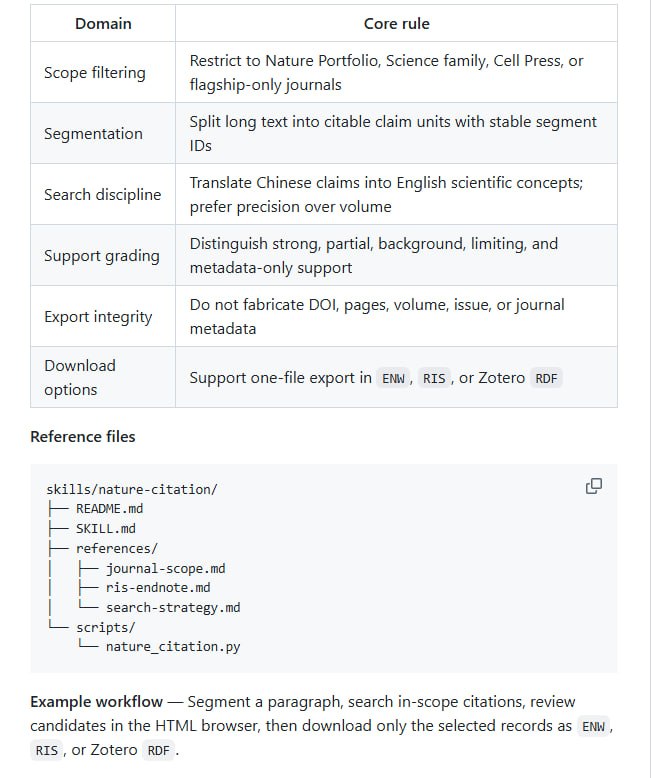
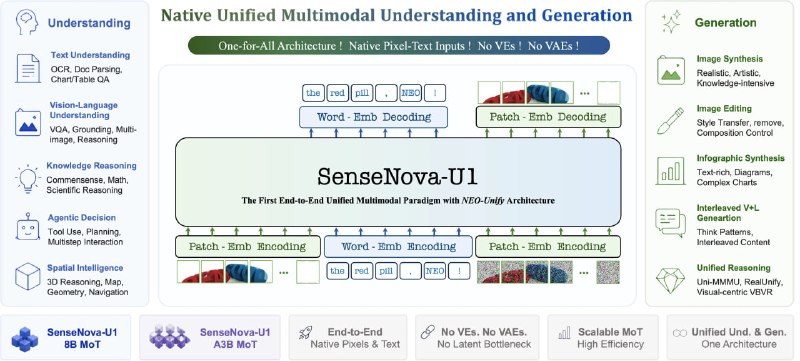
为什么 AI 复杂任务,正在放弃 Markdown 转向 HTML |
推文随着 AI 代理能力的增强,传统的 Markdown 格式已难以承载复杂的逻辑与视觉需求。转向 HTML 作为 AI 的输出媒介,能实现更高信息密度、交互式体验与更直观的视觉呈现,从而让人类在协作中保持深度参与。
当 AI 代理(Agent)开始处理极其复杂的任务时,Markdown 这种“轻量级”的语法反而成了一种枷锁。
如果你习惯于看 AI 生成的 Markdown 计划书,大概会发现一个尴尬的现状:一旦文档超过百行,阅读体验就开始崩塌。为了弥补表达能力的不足,AI 甚至会用 Unicode 字符去模拟颜色,或者用 ASCII 字符画一些简陋的流程图。这就像是在用电报机试图传输高清视频,虽然能传达意思,但效率低得令人沮丧。
HTML 正在成为一种更高效的“通信协议”。
它不仅仅是关于“好看”。HTML 的核心优势在于信息密度。通过嵌入 SVG 矢量图、利用 CSS 进行布局、甚至加入 JavaScript 实现交互,AI 可以交付一个真正的“产品”而非仅仅是一段“描述”。比如,与其看一段描述数据趋势的文字,不如让 AI 直接生成一个带滑块的交互式仪表盘。
有网友提到,HTML 带来的交互感能让协作变得更有趣。你可以要求 AI 生成一个临时的、针对特定任务的“微型编辑器”:比如一个可以拖拽排序的任务卡片流,或者一个带实时预览的 Prompt 调试器。这种“即用即弃”的工具感,让文档从静态的记录变成了动态的实验室。
当然,这种转变并非没有代价。
HTML 的 Token 消耗通常是 Markdown 的数倍,且在版本控制(Git Diff)中显得非常臃肿。如果只是为了简单的笔记,Markdown 依然是王者。但当我们需要进行复杂的架构设计、代码评审或原型开发时,HTML 提供的语义化结构和视觉清晰度,能显著降低人类的认知负荷。
与其说我们在重新发现 HTML,不如说我们在利用 Web 技术栈,为 AI 时代构建一种全新的、可交互的“数字界面”。
当文档本身变成了一个可以运行的小程序,我们与 AI 的关系,也从单纯的“指令与反馈”,进化成了真正的“共创”。