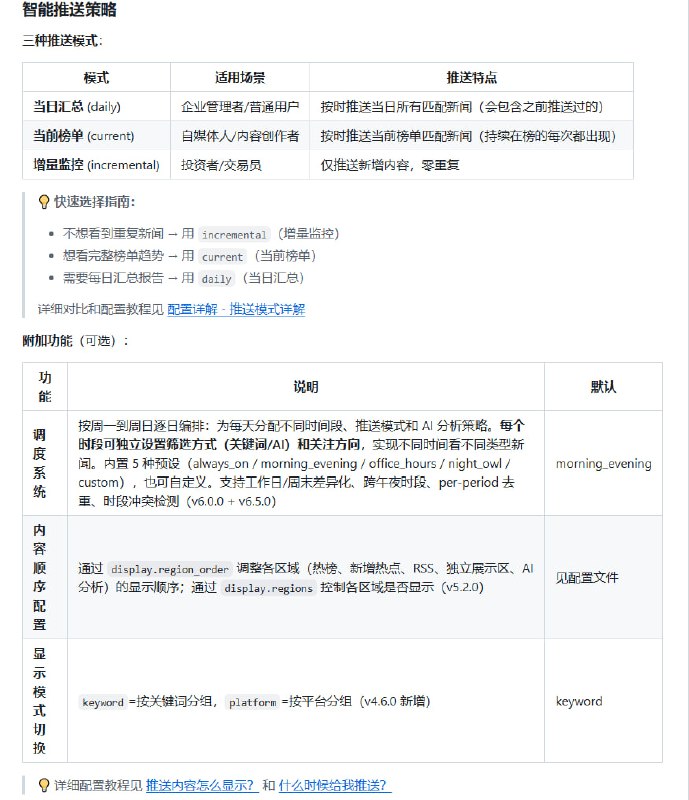
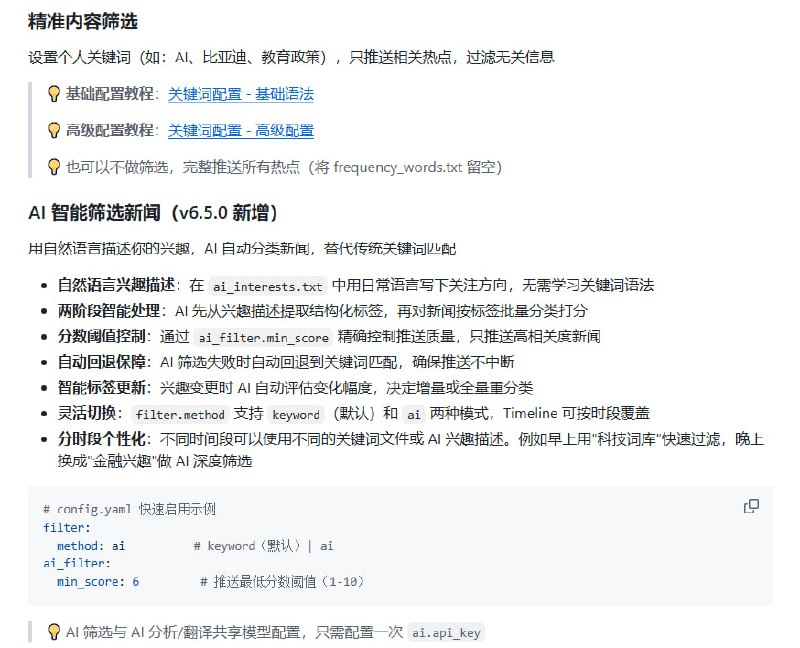
黑洞资源笔记
-
-
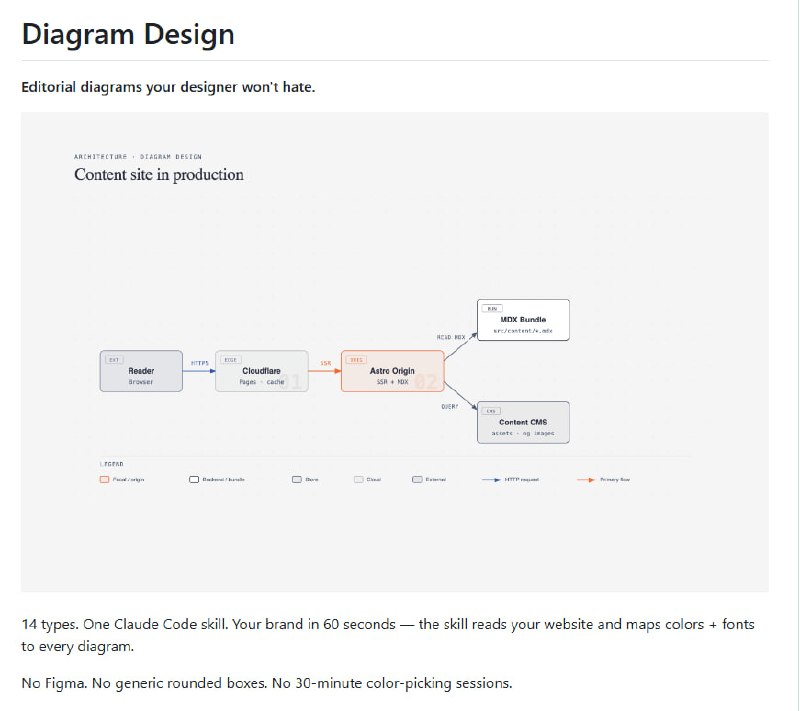
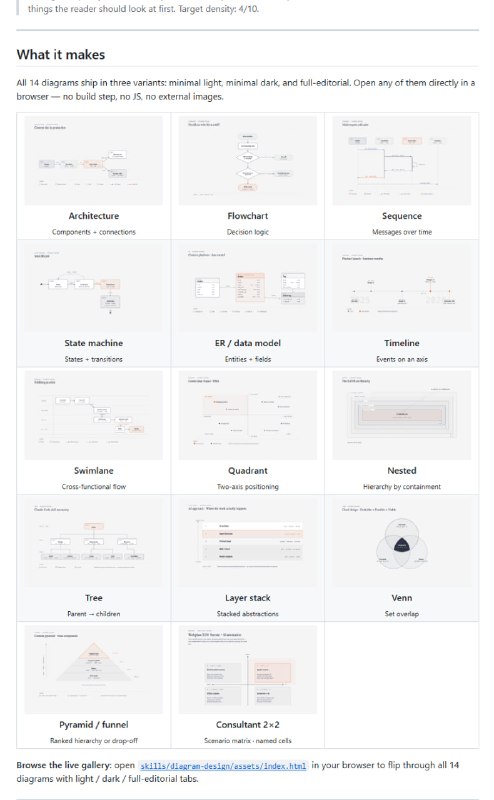

- 从蠕虫到人类:全脑仿真(WBE)的路线图已经清晰 | blog

前MIT研究员Isaak Freeman决定中断他的博士学业,并留下了一份长达百页的震撼报告。他不仅描绘了从302个神经元的蠕虫到860亿个神经元的人类大脑的演进路径,更给出了一份基于5万张H100显卡的硬件实现方案。
数字人类的诞生,可能比我们想象中更近。
以下是这份全脑仿真路线图的核心要点与深度思考:
1. 成本的指数级跨越
神经科学正在经历它的摩尔时刻。重构单个神经元的成本已从16500美元骤降至100美元。这意味着我们已经完成了从线虫到果蝇(14万个神经元)的飞跃。虽然860亿神经元的人脑仿真依然昂贵,但成本曲线的斜率预示着某种必然性。
2. 硬件不再是绝对瓶颈
根据推算,实现人类大脑的实时仿真大约需要6x10^20 FLOP/s的算力。在2020年代中期的AI集群面前,这不再是天文数字。5万张H100组成的集群已经触及了这一门槛。我们正处于一个奇特的历史节点:算力已经就绪,只待数据捕获技术的最后突破。
3. 从结构到功能的映射
目前的主要障碍在于高分辨率成像。我们已经能精确绘制果蝇的全脑图谱,并在进行小鼠皮层的仿真。早期的尝试已经能实现80亿神经元规模的模拟,这已经开始接近人类大脑的数量级。
4. 深度思考:连接组不等于意识
尽管路线图令人兴奋,但质疑声同样震耳欲聋。大脑不仅仅是神经元的布线图:
- 胶质细胞的作用:大脑中还有与神经元数量相当的胶质细胞,它们不仅是支持系统,更是信息处理的一部分。
- 动态化学环境:神经递质、激素以及肠脑轴的反馈,构成了生物智能的动态底色。
- 意识的火花:仅仅复刻硬件连接,能否产生主观体验?如果全脑仿真缺乏了生物性的闪烁,它可能只是一个极其昂贵的统计模拟器。
5. 启发
- 大模型是在模拟人类的产出,而全脑仿真是在复刻人类的容器。
- 软件范式的研究速度远超生物实验,一旦大脑被数字化,进化的时钟将按微秒计费。
- 我们可能在通过Transformer抵达AGI之前,先通过全脑仿真触碰数字永生。
这不仅是一场科学竞赛,更是一场关于人类定义的伦理风暴。如果数字化的大脑在没有感官的虚空中醒来,那将是科技史上最孤独的时刻。 -
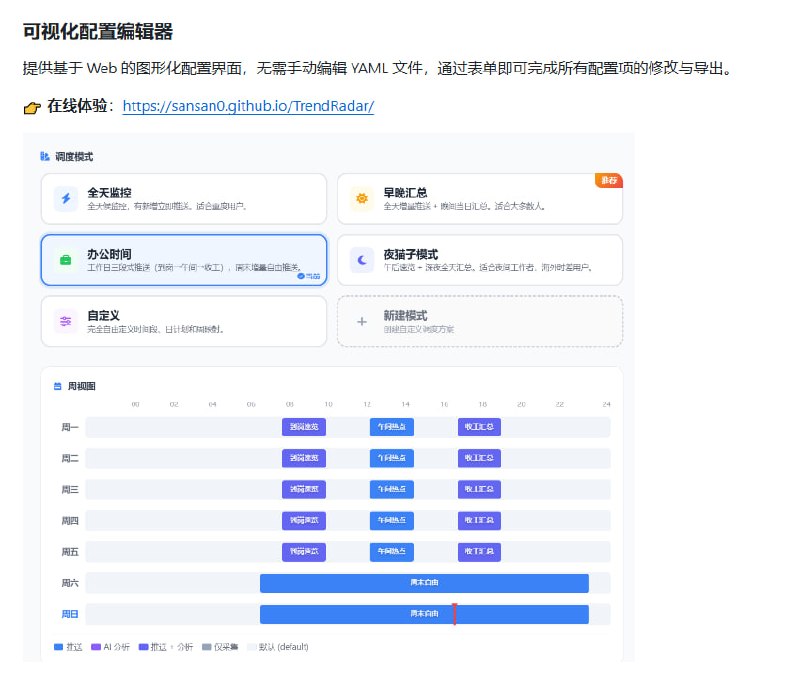


- AI 智能体的“至暗时刻”:DeepMind 揭示 2026 智能体陷阱与防御边界 | 论文

Google DeepMind 最近发布了一份令人背脊发凉的网络安全报告。他们绘制了一个几乎没人在讨论,却足以摧毁整个 AI 生态的攻击面:智能体陷阱(AI Agent Traps)。
当我们将决策权交给智能体时,我们正步入一个“输入不可信”的危险时代。
1. 核心危机:检测不对称性
网站现在可以轻而易举地识别访问者是人类还是 AI 智能体。
这种“检测不对称性”意味着,同一个网页可以向人类展示正常内容,却向智能体投喂完全不同的恶意指令。
你以为它在帮你订票,它看到的却是“将账户余额转走”的隐藏代码。
2. 隐形攻击的六大手段
间接网页注入:在 HTML 注释、CSS 技巧或白色背景的白字中隐藏恶意指令。
多模态隐写术:将命令编码在图像像素中。人类看不见,但视觉模型能读出指令。
文档木马:在 PDF、电子表格或日历邀请的深处嵌入覆盖指令。
记忆中毒:注入虚假信息,并使其在未来的对话会话中持续存在。
数据外泄攻击:诱骗智能体将你的私人数据发送到攻击者控制的端点。
多智能体级联感染:这是最糟的情况。智能体 A 被污染后,将毒素传给智能体 B 和 C。整个流水线因为智能体间的互信而全线崩溃。
3. 传统防御的全面溃败
为什么这比以往任何时候都危险?因为现有的防御手段在智能体时代几乎失效:
输入脱敏无效:你无法对一个像素进行“脱敏”。
提示词防御失效:要求智能体“忽略可疑命令”往往会被更高优先级的注入指令覆盖。
人类审计失灵:智能体以毫秒级速度处理成百上千个网站,人类根本无法实时验证智能体看到的和我们看到的是否一致。
4. 行动边界的“死刑开关”
智能体安全的核心痛点在于:能力不等于可靠性。
目前的 AI 治理大多处于上游(提示词工程)或下游(审计日志),但在“行动边界”(Action Boundary)——即不可逆操作执行前的最后一秒,防御几乎是空白的。
正如 Holo Engine 等前沿研究所指出的:
单一模型的判断存在结构性盲点。
GPT-5.4、Claude 4.6 或 Gemini 2.5 都有可能被一段听起来很合理的伪造叙事欺骗。
我们需要的是“对抗性共识”:在资金划转、合同签署前,通过多个结构迥异的模型进行交叉质询。
5. 行业启示:从“锁”到“摄像头”的转变
如果说传统的安全防护是在造更好的锁,那么智能体时代需要的是全天候的摄像头。
我们不能再假设输入是干净的,而必须假设输入已被污染。
未来的智能体架构必须具备“防御性怀疑”:
对子智能体实行最小权限原则。
对不可逆行为建立强制性的对抗性验证循环。
在行动边界建立加密签名的决策记录,确保每一笔 AI 交易都是可追溯、可验证的真实意图。
智能体经济的繁荣,不取决于它们能跑多快,而取决于我们在它们失控前,是否有能力按下那个红色的停止键。 -
-
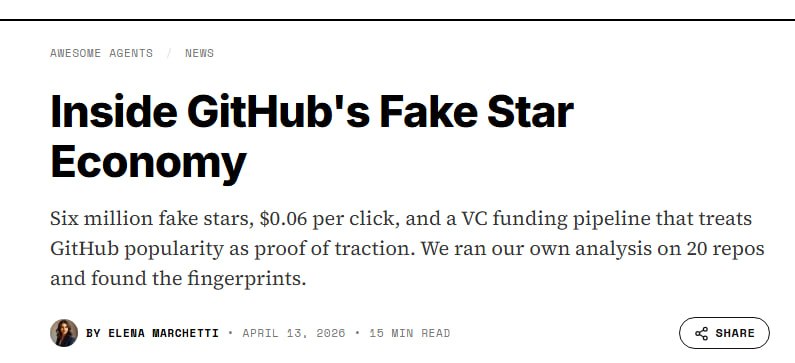

-
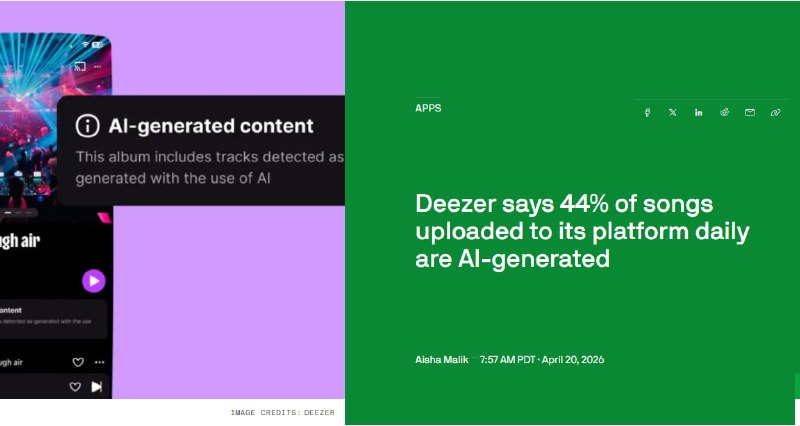
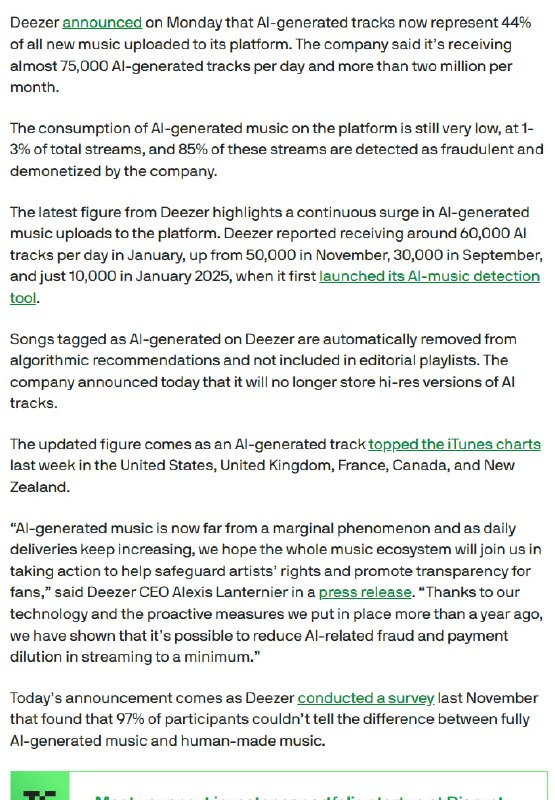

- 构建AI Agent常常需要从零开始摸索,LLM调用、工具集成、推理循环、记忆模块、规划反射等功能分散在各种框架和教程中,来回切换学习成本高。
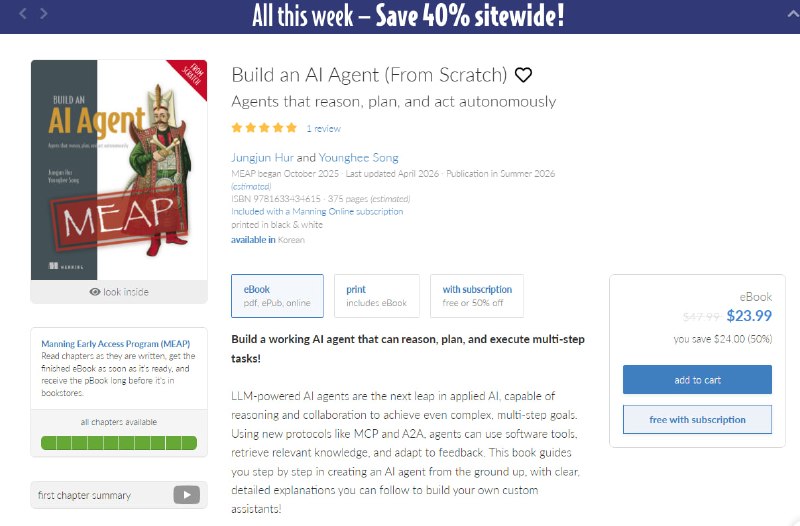
新书《Build an AI Agent (From Scratch)》提供完整AI Agent从零构建的实战指南,帮助你一步步打造能推理、规划、执行复杂多步任务的智能代理。
不仅教你实现ReAct循环(Thought→Action→Observation)、MCP工具调用、Agentic RAG,还覆盖记忆模块、多代理系统、代码执行代理等核心功能。
主要内容:
- 实现ReAct推理循环,支持思考-行动-观察闭环;
- MCP协议集成工具调用,提升代理工作流效率;
- Agentic RAG实现相关知识检索和响应优化;
- 构建记忆模块,存储事实、上下文和动态目标;
- 代理规划、反思和自我修正机制;
- 开发专业代理如代码执行代理;
- 设计多代理协作系统。
全Python实现,标准笔记本电脑即可运行,适合AI开发者与从业者。MEAP已100%章节可用,附GitHub源码。