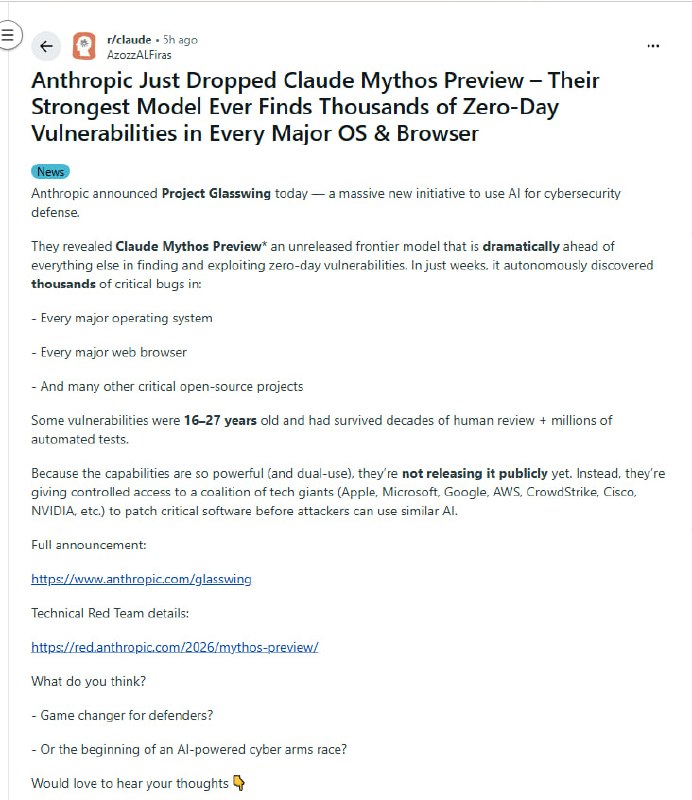
Anthropic 最近展示了一个令人脊背发凉的画面:Claude Mythos Preview 像是一个在暗处潜行的顶级黑客,它不需要人类指引,仅凭自主运行就挖出了 OpenBSD 中一个存在了 27 年的漏洞。这个以极高安全性著称的操作系统,在模型面前竟然出现了可以远程致瘫的裂缝。
这不再是简单的“代码补全”,而是一种深层的逻辑渗透。它能发现那些自动化测试工具跑了五百万次都未曾察觉的 FFmpeg 漏洞,甚至能自主串联 Linux 内核中的多个弱点,实现从普通用户权限到系统完全控制的权限提升。
有观点认为,这标志着网络安全防御范式的剧变。当红队(攻击方)只需要找到一个点,而蓝队(防御方)却必须堵住所有的洞时,这种不对称性在 AI 的加持下被放大了无数倍。
虽然 Anthropic 强调模型能用于自动化补丁编写和漏洞 triage,但技术圈的讨论充满了不安。有网友提到,这听起来就像《赛博朋克 2077》里的“黑墙”(Blackwall),一种不可逾越的技术屏障正在形成。如果顶尖的攻防能力被锁定在少数大企业和主权国家手中,互联网的平民化时代或许正在走向终结。
这种技术鸿沟正在拉开:一边是仅能使用基础模型的普通开发者,另一边是拥有数据中心级大脑、能够自主进行递归改进的机构。有人担心,随着模型能力的指数级增长,防御者的成本将变得无法承受。
不过,也有声音在试图冷静。有网友认为,这种“不公开”可能更多源于推理成本太高,或者是为了通过展示极端案例来为企业级服务造势。毕竟,如果一个模型能自主发现漏洞,它进行自我迭代的速度可能会让所有现有的安全协议都显得苍白无力。
当 AI 开始在代码的底层逻辑中寻找缝隙,我们究竟是在构建更坚固的堡垒,还是在亲手拆除最后一道防线?