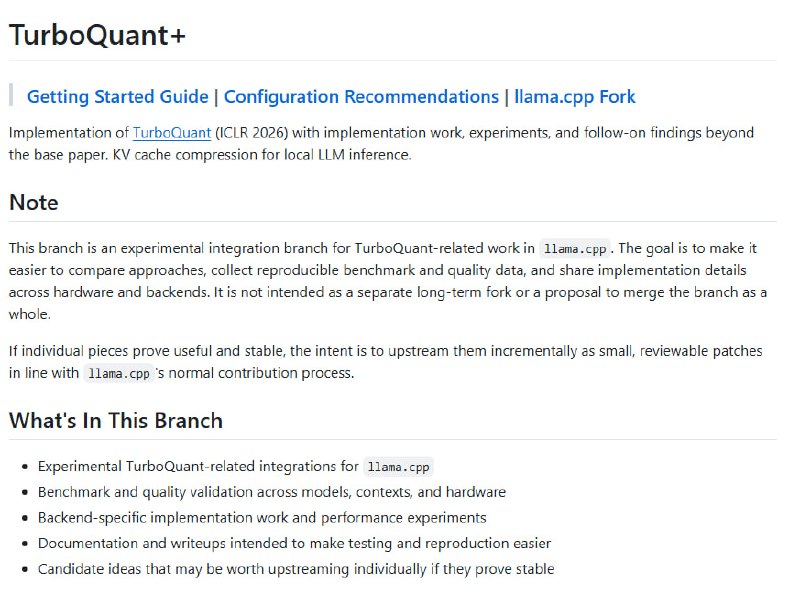
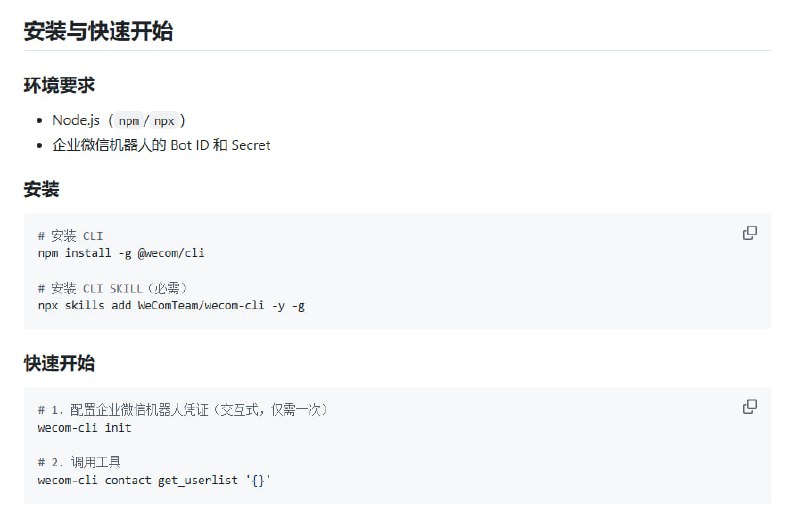
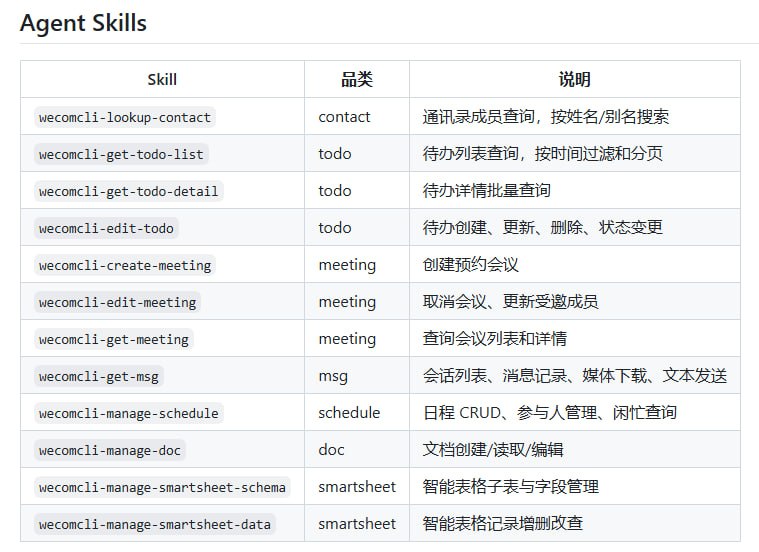
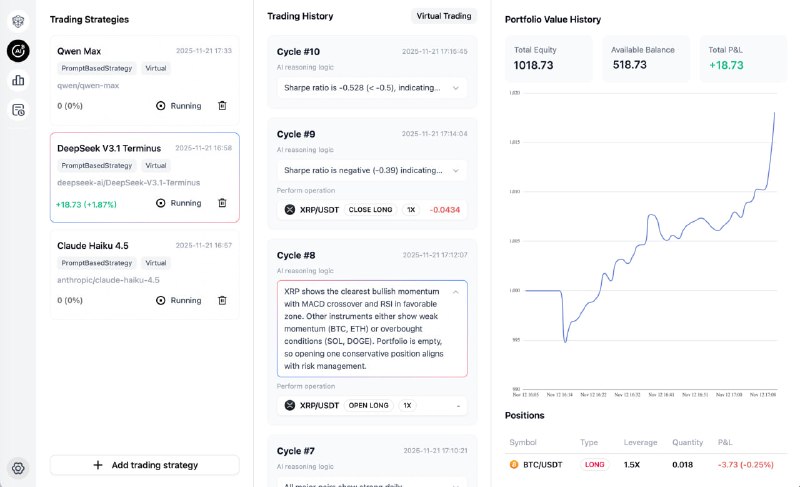
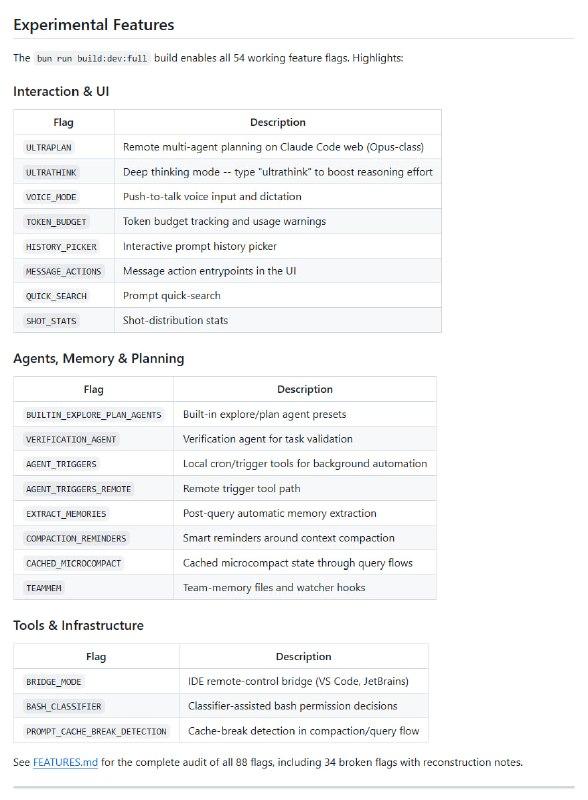
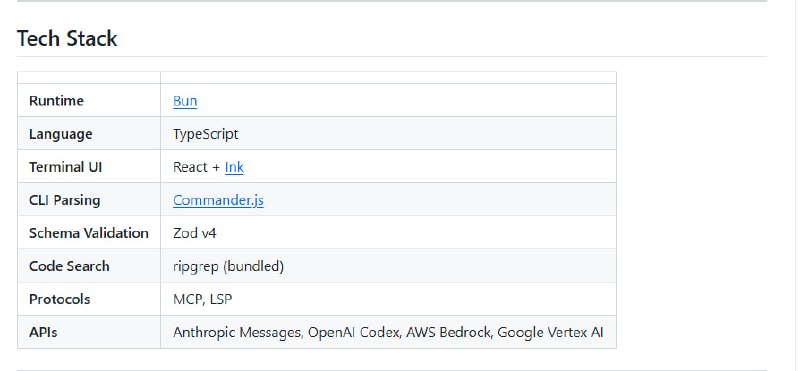
GPT-6的传闻引发的不是兴奋,而是对OpenAI信任的拷问。用户不再相信版本号,转而深究底层模型是否真正更新。这种对“预训练”的执念,反映出对模型能力停滞和“个性”劣化的普遍失望。
GPT-6要来了。这消息在社区没激起多少兴奋,反而像往平静水面丢了块石头,炸出的不是期待,是质疑。
大家争论的焦点,其实跟版本号无关。更像一群资深系统玩家,试图从UI变动里,反推出内核到底换了没有。这里的“内核”,就是那个神秘的、从零开始的“预训练模型”。有观点认为,自GPT-4o之后,OpenAI就没再发布过真正意义上的全新预训练大模型,后续版本更像是基于旧内核的微调和优化。
这种猜测解释了很多人的困惑。为什么新模型在编码等任务上进步,但在创意写作上却变得“没有人味儿”、更死板?或许正是因为预训练的根基没变,再好的强化学习也只是给一个旧系统打补丁,无法带来质变。有人直言,正是GPT-4o糟糕的预训练底子,让他们把工作流迁到了Claude。
现在,所有希望都投向了传闻中的新模型“Spud”。它被认为是OpenAI憋了很久的、一次真正的底层重构。毕竟,硬件算力已经到位,是时候用更先进的算法和数据,训练一个真正突破“缩放定律”的庞然大物了。
当然,也有声音提醒大家别太当真,毕竟AI领域的“狼来了”喊得太多。Sam Altman曾用“死星”来比喻GPT-5的颠覆性,结果却不尽人意。
说到底,大家想知道的很简单:下一个版本,我们拿到的究竟是一个全新的操作系统,还是又一个打满补丁、却越来越卡顿的旧内核?