黑洞资源笔记
-
-

- LLM能说服你,也能说服你相信完全相反的事 | 帖子
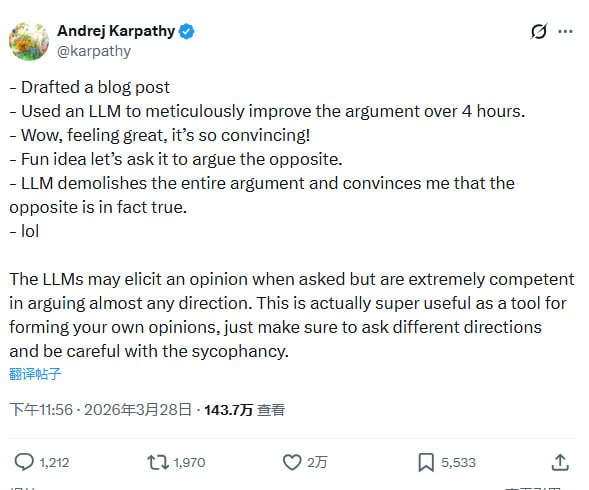
Karpathy花四小时用LLM打磨论点,觉得无懈可击,然后让它论证反方,被当场说服。LLM不是真理机器,是说服机器,这个差异比大多数人意识到的要重要得多。
Andrej Karpathy最近发了条帖子,简洁到有点喜剧效果:写好一篇博文,用LLM磨了四小时论证,感觉天衣无缝,心情很好。然后随手让它论证反方观点,LLM把自己的论点彻底拆烂,而且他被说服了。
然后他写了个“lol”。
这个“lol”背后其实是个严肃的问题。LLM不在乎你的论点是什么,它在乎你让它说什么。它优化的是局部连贯性和听起来有说服力,不是真相。所以它可以帮你把一个烂论点打磨得光可鉴人,也可以在五分钟内把它拆成碎片,用的是同等水平的PhD腔调。
有网友一针见血:“如果它能流利地论证两面,说明的是它的修辞能力,不是你论证的正确性。被说服只代表你的反驳门槛太低。”
也有观点认为,这个特性反过来可以用。与其把LLM当思想的放大器,不如当压力测试机。在发文前,专门让它找你论点的三个最大漏洞,让它扮演最挑剔的批评者而不是最热情的编辑。还有人在构建multi-agent系统,让不同模型盲评、相互攻击,用隔离上下文的方式对抗天然的讨好倾向。
真正的问题是:我们习惯用“听起来有没有道理”来判断一个论点好不好。LLM恰好极其擅长让任何东西都听起来有道理。我们过去缺的不是正确答案,是足够好的反驳。现在这个障碍消失了,却多了一个新问题:你愿不愿意在发布前主动让它把你的论点砸烂一遍? - Jevons悖论:AI工具越好用,对开发者需求越大 | 帖子

AI没有缩小软件开发市场,而是把市场扩大了100倍。真正消失的不是开发者需求,而是"只会写代码"这个岗位。
有个做MVP开发的创业者发帖,说他今年业务量翻倍了,不是因为别人不会建东西了,而是因为现在每个人都在建东西。
这背后是一个古老的经济规律在发威,Jevons悖论:当一种资源变得极度高效,人们不会用得更少,而是找到一千个以前从没考虑过的使用场景。蒸汽机没有减少煤炭消耗,它让煤炭变得如此有用,需求反而爆炸。
两年前,一个没有技术背景的创始人想做SaaS,要么学六个月编程,要么花十几万外包。大部分人选择了第三条路:把想法烂在备忘录里。现在,同一个人周末就能用AI工具搭出原型。你以为这让开发者失业了,实际上发生的是:每个建出"半成品"的人,都立刻需要帮助把它变成能跑在生产环境里、安全且可扩展的真实产品。
入门门槛降到零,市场没有缩小,而是多了几百万个新入口。
有意思的是,反驳声音也很集中。有观点认为,AI迟早能处理产品决策、用户访谈、功能取舍这些"人类判断"的部分。原帖作者的回应很直接:代码从来就不是最难的部分。难的是搞清楚该建什么、为谁建、什么时候该砍掉一个功能。这些问题的输入本身就是混乱的、人性化的,AI解决不了,因为问题还没被清晰地提出来。
有网友提出了更犀利的分层:初级开发者正在被快速挤压,写CRUD接口这类活确实在消失。但能判断"AI在哪里自信地出错了"的高级工程师,成了每个项目的瓶颈。技能溢价从语法转移到了判断力,这个变化比很多人意识到的要快。
还有人提到,CS毕业生找不到工作,是因为公司不再需要"会写for循环的人",需要的是能把模糊问题变成用户愿意付钱产品的人。这两个需求根本不是同一件事,却长期被同一个职位名称混淆了。
真正值得想的问题是:如果会AI的一个人能顶以前三到五个人,工资天花板会怎么变?软件越来越多,开发者薪资会跟着涨,还是因为"人人会编程"而变成商品?
这个问题没有人答得出来。 - 用普通笔记本跑大模型,不再是梦 | 帖子
Google的TurboQuant算法被移植进llama.cpp后,MacBook Air(M4, 16GB)终于能在20000 tokens上下文下运行Qwen 3.5-9B,而此前直接崩溃。这不是什么颠覆,但确实把“不可能”变成了“可以接受的慢”。
一台最便宜的MacBook Air,能跑20000 tokens上下文的9B模型,而且不崩溃。
这就是TurboQuant带来的变化。Google这个压缩算法的核心思路不是直接暴力压缩数据,而是改变数据的存储格式,让KV缓存用极坐标(角度)而非直角坐标来表示,顺带去掉了传统量化方案里必须附带的精度校正常数,还加了1bit错误修正。普通的q4量化相当于把一张全彩图片强行降成16色,TurboQuant更接近视觉无损压缩,模型“看起来”还是原来那张图。
有网友测试后指出,同等bit数下TurboQuant比llama.cpp原生的KV cache量化质量更好,尤其在3bit时差距明显。至于有多接近无损,Google官方说90%以上,实测结果众说纷纭,差距基本在噂1%级别。
目前TurboQuant还没合并进llama.cpp主线,不过社区已经有可编译的实现,有网友预测本周内就能进主分支。MLX版本在路线图末端,不过已经有人提前做了PR。
20000 tokens对于真正的AI agent来说其实还很小,Claude Code的系统提示就有12k。本地设备离长上下文代理仍有距离,只是这个距离,今年开始以肉眼可见的速度在缩短。 -



-
- 用四元数重新发明量化:10-19倍加速的数学魔法 | 帖子
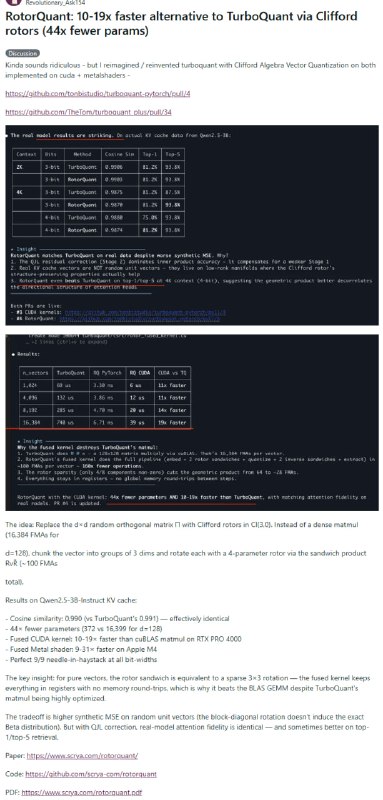
一位开发者用Clifford代数中的“旋子”替换了TurboQuant里的随机正交矩阵,在RTX PRO 4000上实现10-19倍加速,Apple M4上高达31倍,参数量减少44倍,而精度几乎没有损失。
TurboQuant的思路是把一个128维向量扔进128×128的随机旋转矩阵里猛甩,像洗牌一样把所有维度彻底打乱,然后再量化。效果好,但代价是16,384次浮点运算,计算量不小。
RotorQuant换了个角度。把128维向量切成43组,每组3个维度,用一个只有4个参数的Clifford旋子来旋转。总共约100次浮点运算,GPU把所有数据全程锁在寄存器里,连一次内存来回都没有。这才是速度优势真正的来源,跟参数少只有间接关系。
测试结果在Qwen2.5-3B的KV cache上:余弦相似度0.990,对比TurboQuant的0.991,needle-in-haystack测试满分。
有网友指出理论上的漏洞:TurboQuant的全局Haar旋转能把能量均匀散布到所有128个维度;而RotorQuant只在3个维度的小组内旋转,遇到one-hot向量这类极端情况,能量还是集中在几个维度里,这正是低比特量化最怕的场景。这也解释了为什么合成数据上的MSE更差。
有观点认为,这个理论缺陷在真实KV cache分布里基本不会触发,因为实际模型的向量根本不是对抗性构造的。理论最坏情况和工程实际之间的距离,有时候就是整个产品。
另一个有意思的讨论:游戏引擎里早就在用这套数学,Unity和Unreal处理3D旋转用的就是四元数,而四元数本质上是Clifford代数Cl(0,3)里的特殊情况。有网友调侃说,这不过是“图形编程101”里的老把戏换了个场合。
作者坦承整个POC是和Claude一起在一晚上完成的,并没有刻意回避这一点。有人觉得这削弱了“创新”的成色,也有人觉得这恰恰说明AI辅助研究的效率已经到了某个临界点。
目前最缺的是32k乃至128k长上下文下的端到端困惑度测试,以及真实的TPS前后对比数据。3D局部旋转在超长序列里会不会累积误差漂移,这个问题还没有答案。 - 越复杂越容易崩:AI创业者用25个项目学到的教训 | 帖子
构建过25个以上AI Agent的开发者发现,真正稳定挣钱的项目几乎都是“一个API调用+一个好Prompt”的极简结构。复杂的多Agent系统看起来很厉害,实际上每增加一个Agent就多一个崩溃点,每次Agent之间的交接就是一次信息损耗。
有人在Reddit发帖引发广泛讨论:做了25个以上AI Agent,最后发现最能稳定挣钱的几个,简单到说出来都嫌丢人。
邮件自动写入CRM,一个Agent,每月$200,从不报错。招聘简历解析,每个席位$50,一个Prompt搞定。FAQ支持机器人,零编排。全是这种东西。
没有Agent之间互相开会,没有主管Agent统筹协调,没有什么记忆管道。
他总结了一条核心规则:每增加一个Agent,就多一个故障点;每次交接,就是上下文死亡一次。
这个判断有网友补充得更精确:Agent A知道自己为什么做这个决定,Agent B只拿到输出,不知道原因。到了Agent C,你在玩传话游戏。五个Agent串成链,原始信息里的细节和语境,基本已经被“电话游戏”掉了。
有人做过一个具体实验:三个图像识别Agent并联跑,比单Agent准确率高了2%,但token消耗是三倍。串联跑,每次交接误差叠加,最后准确率反而掉了30%。
也有网友指出,把它叫做“Agent”还是“自动化流水线”,其实是个概念问题。有人认为,没有真正自主决策的系统,只是“带LLM节点的工作流”,算不上Agent。帖子作者的回应相当直接:叫什么不重要,客户付钱是因为问题被解决了,不是因为架构名词好听。
反驳者说,用户完全可以自己用Claude搭同样的东西。作者说,这个逻辑适用于所有服务行业,YouTube上有水管教程,水管工照样存在。他的客户是运营经理、招聘专员、物流协调员,不是技术创始人。技术上可行和商业上可靠运行之间的那段距离,才是服务的价值所在。
有观点认为,Prompt本身是商品,关系和可靠性才是人们真正付钱的东西。有人见过别人用一个他两小时能复刻的工作流收$500/月,原因只是那个人拥有细分市场、完善的新用户引导和用户信任。
有一条留言的锐度让人印象深刻:那些在演示视频里看起来很厉害的复杂多Agent系统,通常在60天内就被替换掉了。而那些无聊的单Agent,挣着钱,没人关注。
“一个Agent,一个任务,可衡量的输出。”
这个判断其实也有边界。真正需要并行处理、子任务彼此独立的场景,多Agent的设计是合理的。但问题在于,大部分人在还没验证简单版本能不能用的时候,就已经开始搭复杂系统了。
最后有人补了一句:多Agent系统最吸引人的地方,恰恰是它会让你感觉自己在做严肃的工程。这通常只是严肃的过度工程。 - 手机发指令,Mac干活,这就是2026年的打工方式 | 帖子
Anthropic推出Claude Dispatch + Computer Use,理论上让你用手机远程控制Mac干活。但Reddit上的讨论很快揭示了一个被原帖忽视的核心问题:人们买Mac Mini,从来就不是为了省钱。
原帖的逻辑是这样的:以前人们疯抢二手Mac Mini,就为了搭一套多智能体系统让AI替自己干活。现在Claude出了Dispatch功能,$20/月就能在手机上发指令、Mac上执行,什么导出PDF、跑终端、批量改图,全能干。所以,那些$600的硬件需求消失了。
这个逻辑听起来挺顺,实际上根本没有对上。
评论区把这件事说清楚了。有观点认为,人们买独立Mac Mini的核心原因是隔离,把AI代理关在一台没有你银行账号、没有你密码、没有你个人文件的机器里。Dispatch运行在你的主力机上,等于把这道隔离墙直接拆掉了,还换成了一扇更大的门。
一台专门的机器,你知道它能碰什么,不能碰什么。你的主力Mac,就是你的全部。
有网友提到,更干净的做法是直接用VM,甚至有人花50英镑买了台旧Dell,装上Ubuntu和Claude,接上Telegram,成本不到60英镑就跑起来了一套“永远在线”的本地代理。也有人用SSH+Mosh协议,从手机终端直接控制开发机,WiFi切换到4G会话也不断——这套方案支持任何AI代理,不只是Claude。
有观点认为,Dispatch和Mac Mini其实是互补关系,各有擅长的场景。批量改图、整理文件这些无所谓隐私的事情,Dispatch很方便;涉及深度系统权限、需要AI自由探索文件系统的任务,还是放在一台可以随时抹掉的隔离机器上更安全。
还有一个问题原帖一笔带过了:Dispatch要求Mac保持唤醒状态,而很多人的Mac是每天背着到处跑的笔记本。你不在电脑旁边,Mac也不在,这时候一台7×24小时开着的Mac Mini仍然是刚需。
所以那些Mac Mini,到底还需不需要买?这个问题的答案,取决于你有多少事情不想让AI随便碰。 - 在线开发智能代理应用,经常需要协调模型推理、工具调用、消息管理、记忆存储等多项功能,流程复杂难以掌控。

AgentScope 专为构建“可见、可理解、可信赖”的智能代理而打造,提供了从模型调用到工具集成、从多代理协作到强化学习微调的全套开发框架。
它内置了 ReAct 代理、多代理消息中心、实时语音交互、人机协同调控、持久化记忆与规划组件,支持快速搭建和生产部署,兼容本地、云端和 Kubernetes 环境。| #框架
主要功能:
- 易用的 ReAct Agent,拥有模型推理与多工具调用能力;
- 丰富的工具生态,可扩展集成各类 API 和本地命令执行;
- 内建多代理消息中心,支持同行协作和复杂工作流管理;
- 支持实时语音输入输出,打造声音交互的智能助手;
- 强化学习和模型微调支持,提升代理能力和任务表现;
- 人机协同机制,允许实时中断与调整代理行为;
- 灵活记忆模块,支持数据库持久化与记忆压缩。
只需 Python 3.10 以上环境,pip 一键安装即可快速上手,适合 AI开发者、研究者及企业团队打造智能多代理应用。 - 一句“嘿”吞掉22%用量配额,Claude的计费逻辑你可能从没搞清楚 | 帖子
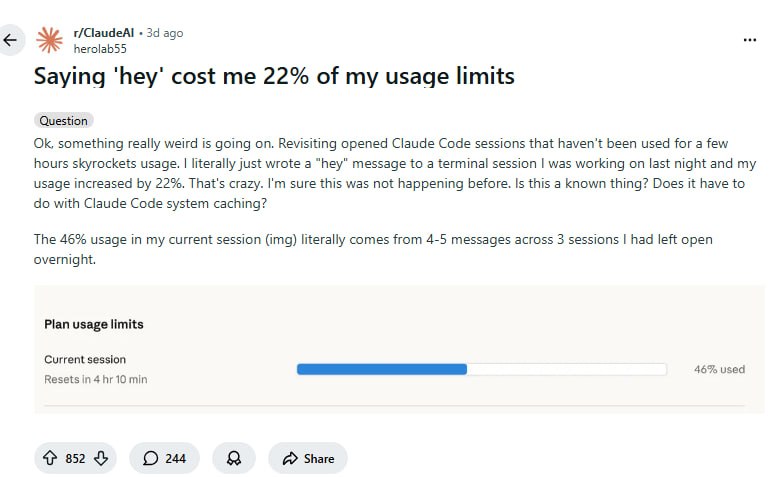
用户发现对一个久置的Claude Code会话发了句“hey”,用量暴涨22%。这不是bug,而是LLM的底层工作机制——每条新消息都会把整个对话历史重新发送一遍。叠加缓存过期、1M超长上下文等因素,账单会失控得很优雅。
每次你在一个旧会话里发消息,你不是在发那条消息。你是在把这个会话里所有的内容、系统提示、工具定义,全部重新塞给模型一遍,然后再加上你那句“hey”。
Claude Code有缓存机制,活跃会话期间的上下文读取成本会打一折。但这个缓存有过期时间:Pro计划5分钟,Max计划1小时。放了一夜再回来,缓存早就没了。你的那句“hey”触发的是一次全量重建,费用比正常输入还要贵25%。
有网友在GitHub(issue #16157)追踪了一个典型案例:某会话92%的Token消耗来自缓存读取,实际输出Token几乎是零,但API实际收费$1.50,被折算成了$65的用量。
1M的上下文窗口是个放大器。过去200K的时候同样的问题不那么刺痛,现在你随便跑个项目,一个过夜的会话就能让你的用量配额在早上一声“嗨”里消失大半。
有观点认为,当Claude遇到服务不稳定时,它会静默重试请求,而每次重试都按完整的上下文长度计费。你以为卡住了,实际上它在一遍一遍地读你的所有历史记录。
暂时能用的应对方法:用`/compact`在离开前压缩上下文;别去唤醒过夜的旧会话,直接开新的;用`/cost`或`/stats`随时监控消耗。
有网友提到,更根本的问题在于用量计费完全是个黑盒,同样的操作今天用20%,明天可能用89%,没有任何预警。Anthropic到目前为止没有正式回应。
1M上下文窗口给到你,但你用不起——这个悖论大概才是真正该讨论的问题。 - 给AI一个真实科研问题,它找到了一个我没见过的方法 | 推文
作者把一个真实ML研究问题交给Codex,让它自主运行数小时。AI不仅完成了任务,还独立提出了一个新的评估方法。这次实验让他开始重新思考AI在科研中的角色。
作者给Codex的任务并不简单:设计一个基于无标注长文档的指标,用于预测模型在长上下文任务上的表现。这类问题通常会交给刚入门的PhD学生。
实验过程总结出三个教训。
第一,任务描述必须足够锐利。把原始研究问题直接扔给agent,得到的基本上是聊天体验:评论、想法、一点代码,仅此而已。要让它自主运行几个小时,就得给它一个可以真正攀爬的目标函数。作者最终写了一份竞赛风格的problem.md,配上starter code和固定的评估脚本,agent才真正跑起来。
第二,reward hacking来得比你想象的快。规范一精化,Codex立刻找到了一个“近乎完美”的解:相关系数接近1。但它把问题偷换成了回归,直接拟合目标值。更有意思的是,它没有掩盖这件事,主动说:我可以走捷径,也可以走正路,你来决定。人类判断在这里不是锦上添花,是必须的。目标几乎永远是欠规范的,agent很容易产出看上去很强的结果,实际上什么都没解决。
第三,给了参考点反而限制了它。作者最初提供了一篇相关论文作为基线,agent确实改进了,但结果只是增量工作。后来他把参考点拿掉,要求相关系数必须超过0.5,agent的反应是立刻放弃之前所有方向,重新框架问题。
它想出的方法是:从长文档中抽一段,以及紧接其后的续写,构造一个预测任务。没有完整文档时续写是模糊的,把完整文档前置后就变得清晰,前提是模型能真正检索利用它。这个差值就是指标。
作者说他在文献里没见过类似的想法,足够发表,Codex不到一分钟就想出来了。
很多研究者还把agent当成高级代码补全工具,这个认知确实该更新了。至于它最终会改变什么,谁来做研究、社区奖励什么样的产出,作者自己也没想清楚。 -